Este artículo analiza el montaje espacio de nombres y es el tercero de la serie Linux Namespace. En el primer artículo, brindé una introducción a los siete espacios de nombres más utilizados, sentando las bases para el trabajo práctico iniciado en el artículo sobre espacios de nombres de usuario. Mi objetivo es desarrollar algunos conocimientos fundamentales sobre cómo funcionan las bases de los contenedores de Linux. Si está interesado en cómo Linux controla los recursos en un sistema, consulte la serie CGroup, escribí anteriormente. Con suerte, para cuando haya terminado con el trabajo práctico de los espacios de nombres, puedo vincular los CGroups y los espacios de nombres de una manera significativa, completando la imagen por usted.
Sin embargo, por ahora, este artículo examina el espacio de nombres de montaje y cómo puede ayudarlo a comprender mejor el aislamiento que los contenedores de Linux brindan a los administradores de sistemas y, por extensión, a plataformas como OpenShift y Kubernetes.
[ También te puede interesar: Compartir grupos complementarios con contenedores Podman ]
El espacio de nombres del montaje
El espacio de nombres de montaje no se comporta como cabría esperar después de crear un nuevo espacio de nombres de usuario. De forma predeterminada, si tuviera que crear un nuevo espacio de nombres de montaje con unshare -m , su visión del sistema permanecería prácticamente sin cambios y sin restricciones. Esto se debe a que cada vez que crea un nuevo espacio de nombres de montaje, una copia de los puntos de montaje del espacio de nombres principal se crea en el nuevo espacio de nombres de montaje. Eso significa que cualquier acción realizada en archivos dentro de un espacio de nombres de montaje mal configurado será impactar al anfitrión.
Algunos pasos de configuración para montar espacios de nombres
Entonces, ¿de qué sirve el espacio de nombres de montaje entonces? Para ayudar a demostrar esto, uso un tarball de Alpine Linux.
En resumen, descárguelo, descomprímalo y muévalo a un nuevo directorio, otorgando permisos de directorio de nivel superior para un usuario sin privilegios:
[root@localhost ~] export CONTAINER_ROOT_FOLDER=/container_practice
[root@localhost ~] mkdir -p ${CONTAINER_ROOT_FOLDER}/fakeroot
[root@localhost ~] cd ${CONTAINER_ROOT_FOLDER}
[root@localhost ~] wget https://dl-cdn.alpinelinux.org/alpine/v3.13/releases/x86_64/alpine-minirootfs-3.13.1-x86_64.tar.gz
[root@localhost ~] tar xvf alpine-minirootfs-3.13.1-x86_64.tar.gz -C fakeroot
[root@localhost ~] chown container-user. -R ${CONTAINER_ROOT_FOLDER}/fakeroot
La fakeroot el directorio debe ser propiedad del usuario container-user porque una vez que crea un nuevo espacio de nombres de usuario, la raíz el usuario en el nuevo espacio de nombres se asignará al container-user fuera del espacio de nombres. Esto significa que un proceso dentro del nuevo espacio de nombres pensará que tiene las capacidades necesarias para modificar sus archivos. Aún así, los permisos del sistema de archivos del host evitarán que el usuario del contenedor cuenta de cambiar los archivos de Alpine desde el tarball (que tienen raíz como propietario).
Entonces, ¿qué sucede si simplemente inicia un nuevo espacio de nombres de montaje?
PS1='\u@new-mnt$ ' unshare -Umr Ahora que está dentro del nuevo espacio de nombres, es posible que no espere ver ninguno de los puntos de montaje originales del host. Sin embargo, este no es el caso:
root@new-mnt$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/cs-root 36G 5.2G 31G 15% /
tmpfs 737M 0 737M 0% /sys/fs/cgroup
devtmpfs 720M 0 720M 0% /dev
tmpfs 737M 0 737M 0% /dev/shm
tmpfs 737M 8.6M 728M 2% /run
tmpfs 148M 0 148M 0% /run/user/0
/dev/vda1 976M 197M 713M 22% /boot
root@new-mnt$ ls /
bin container_practice etc lib media opt root sbin sys usr
boot dev home lib64 mnt proc run srv tmp var
La razón de esto es que systemd el valor predeterminado es compartir recursivamente los puntos de montaje con todos los espacios de nombres nuevos. Si montó un tmpfs sistema de archivos en algún lugar, por ejemplo, /mnt dentro del nuevo espacio de nombres de montaje, ¿puede verlo el host?
root@new-mnt$ mount -t tmpfs tmpfs /mnt
root@new-mnt$ findmnt |grep mnt
└─/mnt tmpfs tmpfs rw,relatime,seclabel,uid=1000,gid=1000 El anfitrión, sin embargo, no ve esto:
[root@localhost ~]# findmnt |grep mnt Por lo menos, sabrá que el espacio de nombres de montaje funciona correctamente. Este es un buen momento para tomar un pequeño desvío para discutir la propagación de los puntos de montaje. Estoy resumiendo brevemente, pero si está interesado en una mayor comprensión, eche un vistazo al artículo LWN de Michael Kerrisk, así como a la página del manual para el espacio de nombres de montaje. Normalmente no confío tanto en las páginas del manual, ya que a menudo encuentro que no son fáciles de digerir. Sin embargo, en este caso, están llenos de ejemplos y (en su mayoría) en un inglés sencillo.
Teoría de los puntos de montaje
Los montajes se propagan de forma predeterminada debido a una característica del kernel denominada subárbol compartido. . Esto permite que cada punto de montaje tenga su propio tipo de propagación asociado. Estos metadatos determinan si los nuevos montajes en una ruta determinada se propagan a otros puntos de montaje. El ejemplo dado en la página del manual es el de un disco óptico. Si su disco óptico se montó automáticamente en /cdrom , el contenido solo sería visible en otros espacios de nombres si se establece el tipo de propagación adecuado.
Grupos de pares y estados de montaje
La documentación del kernel dice que un "grupo de pares se define como un grupo de vfsmounts que propagan eventos entre sí". Los eventos son cosas como montar un recurso compartido de red o desmontar un dispositivo óptico. ¿Por qué es esto importante? Preguntas. Bueno, cuando se trata del espacio de nombres de montaje, los grupos de pares
- compartido - Una montura que pertenece a un grupo de pares. Cualquier cambio que ocurra se propagará a través de todos los miembros del grupo de pares.
- esclavo - Propagación unidireccional. El punto de montaje maestro propagará eventos a un esclavo, pero el maestro no verá ninguna acción que realice el esclavo.
- compartido y esclavo - Indica que el punto de montaje tiene un maestro, pero también tiene su propio grupo de pares. El maestro no será notificado de los cambios en un punto de montaje, pero los miembros del grupo de pares en sentido descendente sí lo harán.
- privado - No recibe ni reenvía ningún evento de propagación.
- no enlazable - No recibe ni reenvía ningún evento de propagación y no puede ser enlazado montado.
Es importante tener en cuenta que el estado del punto de montaje es por punto de montaje . Esto significa que si tiene / y /boot , por ejemplo, tendría que aplicar por separado el estado deseado a cada punto de montaje.
En caso de que se esté preguntando acerca de los contenedores, la mayoría de los motores de contenedores usan estados de montaje privados cuando montan un volumen dentro de un contenedor. No te preocupes demasiado por esto por ahora. Solo quiero proporcionar algo de contexto. Si desea probar algunos escenarios de montaje específicos, consulte las páginas del manual, ya que los ejemplos son bastante buenos.
Creando nuestro espacio de nombres de montaje
Si usa un lenguaje de programación como Go o C, puede usar las llamadas al kernel del sistema sin procesar para crear el entorno adecuado para sus nuevos espacios de nombres. Sin embargo, dado que la intención detrás de esto es ayudarlo a comprender cómo interactuar con un contenedor que ya existe, tendrá que hacer algunos trucos bash para que su nuevo espacio de nombres de montaje tenga el estado deseado.
Primero, cree el nuevo espacio de nombres de montaje como un usuario normal:
unshare -Urm
Una vez que esté dentro del espacio de nombres, mire el findmnt del dispositivo mapeador, que contiene el sistema de archivos raíz (para abreviar, eliminé la mayoría de las opciones de montaje de la salida):
findmnt |grep mapper
/ /dev/mapper/cs-root xfs rw,relatime,[...] Solo hay un punto de montaje que tiene el asignador de dispositivos raíz. Esto es importante porque una de las cosas que debe hacer es vincular el dispositivo del mapeador al directorio de Alpine:
export CONTAINER_ROOT_FOLDER=/container_practice
mount --bind ${CONTAINER_ROOT_FOLDER}/fakeroot ${CONTAINER_ROOT_FOLDER}/fakeroot
cd ${CONTAINER_ROOT_FOLDER}/fakeroot
Esto se debe a que está utilizando una utilidad llamada pivot_root para realizar un chroot -como acción. pivot_root toma dos argumentos:new_root y old_root (a veces denominado put_old ). pivot_root mueve el sistema de archivos raíz del proceso actual al directorio put_old y hace new_root el nuevo sistema de archivos raíz.
IMPORTANTE :Una nota sobre chroot . chroot a menudo se piensa que tiene beneficios de seguridad adicionales. Hasta cierto punto, esto es cierto, ya que se necesita una gran cantidad de experiencia para liberarse de él. Un chroot cuidadosamente construido puede ser muy seguro. Sin embargo, chroot no modifica ni restringe las capacidades de Linux que mencioné en el artículo anterior sobre el espacio de nombres. Tampoco limita las llamadas al sistema al kernel. Esto significa que un agresor lo suficientemente hábil podría escapar de un chroot eso no ha sido bien pensado. Los espacios de nombres de montaje y usuario ayudan a resolver este problema.
Si usa pivot_root sin el montaje de enlace, el comando responde con:
pivot_root: failed to change root from `.' to `old_root/': Invalid argument
Para cambiar al sistema de archivos raíz de Alpine, primero cree un directorio para old_root y luego gire al sistema de archivos raíz previsto (Alpine). Dado que el sistema de archivos raíz de Alpine Linux no tiene enlaces simbólicos para /bin y /sbin , tendrá que agregarlos a su ruta y luego, finalmente, desmontar old_root :
mkdir old_root
pivot_root . old_root
PATH=/bin:/sbin:$PATH
umount -l /old_root
Ahora tiene un entorno agradable donde el usuario y montar Los espacios de nombres trabajan juntos para proporcionar una capa de aislamiento del host. Ya no tiene acceso a los archivos binarios en el host. Intente emitir el findmnt comando que usaste antes:
root@new-mnt$ findmnt
-bash: findmnt: command not found También puede mirar el sistema de archivos raíz o intentar ver qué está montado:
root@new-mnt$ ls -l /
total 12
drwxr-xr-x 2 root root 4096 Jan 28 21:51 bin
drwxr-xr-x 2 root root 18 Feb 17 22:53 dev
drwxr-xr-x 15 root root 4096 Jan 28 21:51 etc
drwxr-xr-x 2 root root 6 Jan 28 21:51 home
drwxr-xr-x 7 root root 247 Jan 28 21:51 lib
drwxr-xr-x 5 root root 44 Jan 28 21:51 media
drwxr-xr-x 2 root root 6 Jan 28 21:51 mnt
drwxrwxr-x 2 root root 6 Feb 17 23:09 old_root
drwxr-xr-x 2 root root 6 Jan 28 21:51 opt
drwxr-xr-x 2 root root 6 Jan 28 21:51 proc
drwxr-xr-x 2 root root 6 Feb 17 22:53 put_old
drwx------ 2 root root 27 Feb 17 22:53 root
drwxr-xr-x 2 root root 6 Jan 28 21:51 run
drwxr-xr-x 2 root root 4096 Jan 28 21:51 sbin
drwxr-xr-x 2 root root 6 Jan 28 21:51 srv
drwxr-xr-x 2 root root 6 Jan 28 21:51 sys
drwxrwxrwt 2 root root 6 Feb 19 16:38 tmp
drwxr-xr-x 7 root root 66 Jan 28 21:51 usr
drwxr-xr-x 12 root root 137 Jan 28 21:51 var
root@new-mnt$ mount
mount: no /proc/mounts
Curiosamente, no hay proc sistema de archivos montado por defecto. Intenta montarlo:
root@new-mnt$ mount -t proc proc /proc
mount: permission denied (are you root?)
root@new-mnt$ whoami
root
Porque proc es un tipo especial de montaje relacionado con el espacio de nombres PID que no puede montar aunque esté en su propio espacio de nombres de montaje. Esto se remonta a la herencia de capacidad que discutí anteriormente. Retomaré esta discusión en el próximo artículo cuando cubra el espacio de nombres PID. Sin embargo, como recordatorio sobre la herencia, eche un vistazo al siguiente diagrama:
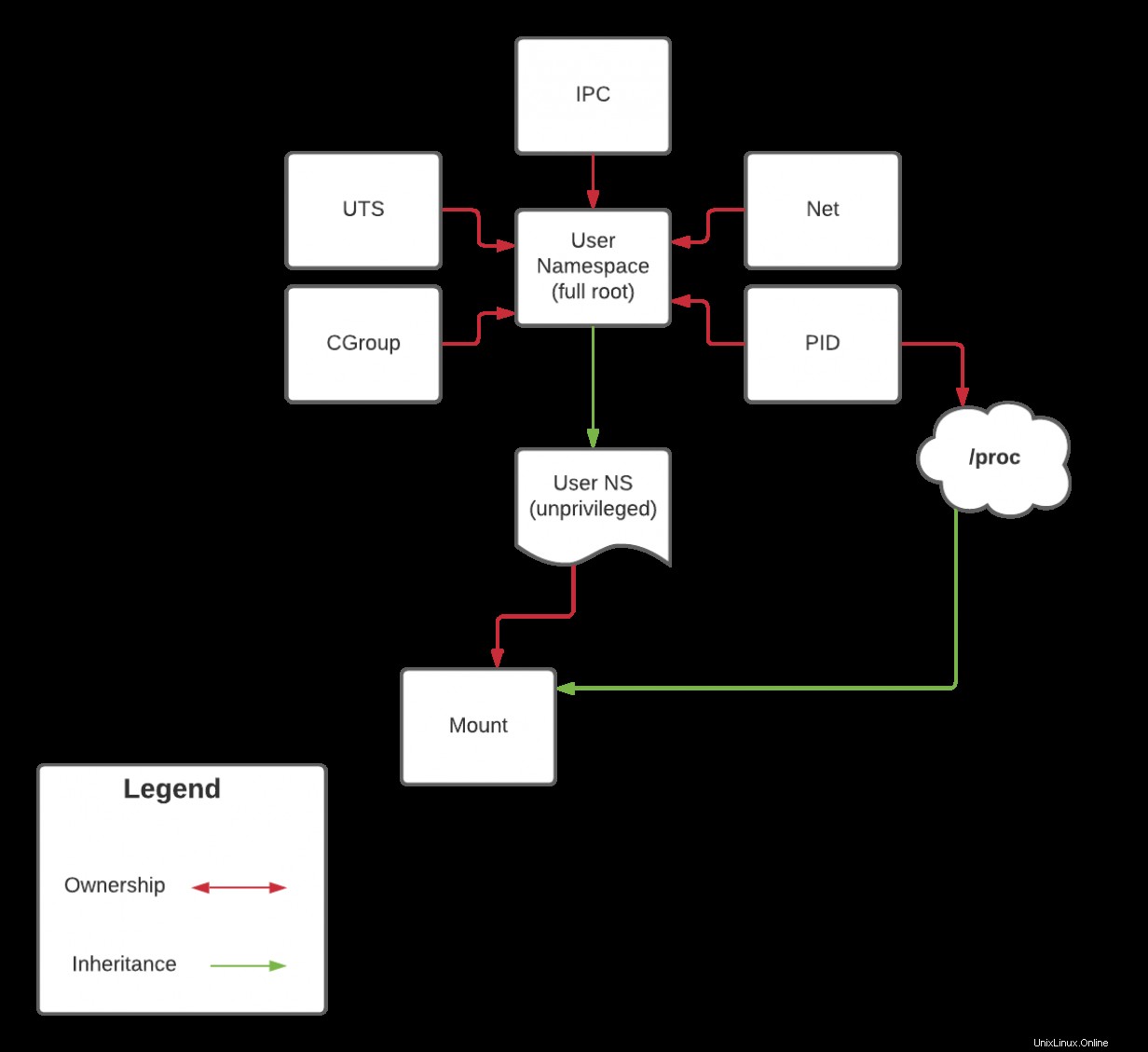
En el próximo artículo, repetiré este diagrama, pero si lo has seguido desde el principio, deberías poder hacer algunas inferencias antes de eso.
[ El manual del propietario de API:7 prácticas recomendadas para programas de API efectivos ]
Conclusión
En este artículo, cubrí una teoría más profunda sobre el espacio de nombres de montaje. Discutí los grupos de pares y cómo se relacionan con los estados de montaje que se aplican a cada punto de montaje en un sistema. Para la parte práctica, descargó un sistema de archivos Alpine Linux mínimo y luego explicó cómo usar los espacios de nombres de usuario y montaje para crear un entorno que se parece mucho a chroot excepto potencialmente más seguro.
Por ahora, pruebe a montar sistemas de archivos dentro y fuera de su nuevo espacio de nombres. Intente crear nuevos puntos de montaje que usen el compartido , privado y esclavo estados de montaje. En el próximo artículo, usaré el espacio de nombres PID para continuar construyendo el contenedor primitivo para obtener acceso al proc sistema de archivos y aislamiento de procesos.