Como administrador de sistemas, es imperativo facilitar la alta disponibilidad en todos los niveles posibles en la arquitectura y el diseño de un sistema, y el entorno de SAP no es diferente. En este artículo, analizo cómo aprovechar Red Hat Enterprise Linux (RHEL) Pacemaker para alta disponibilidad (HA) de SAP NetWeaver Advanced Business Application Programming (ABAP) SAP Central Service (ASCS)/Enqueue Replication Server (ERS).
[ También te puede interesar: Guía de inicio rápido de Ansible para administradores de sistemas de Linux]
SAP tiene una arquitectura de tres capas:
- Capa de presentación —Presenta una GUI para la interacción con la aplicación SAP
- Capa de aplicación —Contiene uno o más servidores de aplicaciones y un servidor de mensajes
- Capa de base de datos —Contiene la base de datos con todos los datos relacionados con SAP (por ejemplo, Oracle)
En este artículo, el enfoque principal está en la capa de aplicación. Las instancias del servidor de aplicaciones proporcionan las funciones de procesamiento de datos reales de un sistema SAP. Según los requisitos del sistema, se crean múltiples servidores de aplicaciones para manejar la carga en el sistema SAP. Otro componente principal en la capa de aplicación es ABAP SAP Central Service (ASCS). Los servicios centrales comprenden dos componentes principales:Servidor de mensajes (MS) y Servidor de puesta en cola (ES). El servidor de mensajes actúa como un canal de comunicación entre todos los servidores de aplicaciones y maneja la distribución de la carga. El servidor Enqueue controla el mecanismo de bloqueo.
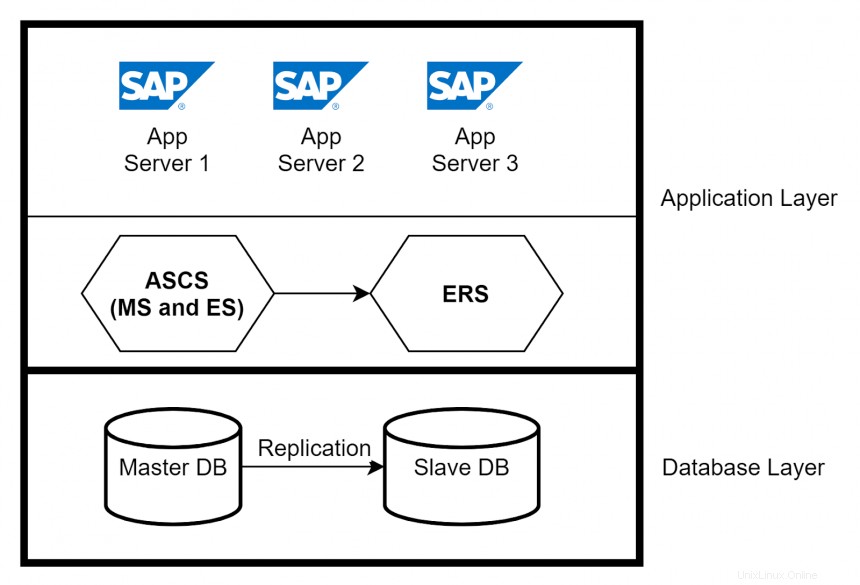
Alta disponibilidad en capas de aplicaciones y bases de datos
Puede implementar una alta disponibilidad para los servidores de aplicaciones utilizando un equilibrador de carga y haciendo que varios servidores de aplicaciones manejen las solicitudes de los usuarios. Si un servidor de aplicaciones falla, solo los usuarios conectados a ese servidor se ven afectados. Aísle el bloqueo eliminando el servidor de aplicaciones del balanceador de carga. Para una alta disponibilidad de ASCS, utilice el servidor de replicación en cola (ERS) para replicar las entradas de la tabla de bloqueo. En la capa de la base de datos, puede configurar la replicación de la base de datos nativa entre las bases de datos principal y secundaria para garantizar una alta disponibilidad.
Introducción a la alta disponibilidad de RHEL con Pacemaker
RHEL High Availability permite la conmutación por error de los servicios de un nodo a otro sin problemas dentro de un clúster sin causar ninguna interrupción en el servicio. ASCS y ERS se pueden integrar en un clúster RHEL Pacemaker. En caso de que falle un nodo ASCS, los paquetes del clúster cambian a un nodo ERS donde las instancias de MS y ES continuarán ejecutándose sin detener el sistema. En caso de que falle un nodo ERS, el sistema no se ve afectado, ya que MS y ES seguirán ejecutándose en el nodo ASCS. En este caso, la instancia de ERS no se ejecutará en el nodo ASCS ya que las instancias de ES y ERS no necesitan ejecutarse en el mismo nodo.
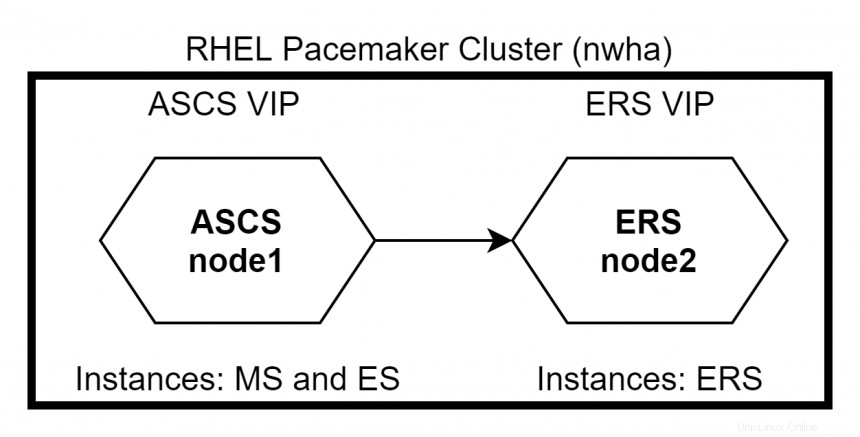
Configuración de marcapasos RHEL
Hay dos formas de configurar los nodos ASCS y ERS en el clúster de RHEL Pacemaker:Principal/Secundario y Independiente . El Principal/Secundario El enfoque es compatible con todas las versiones menores de RHEL 7. El enfoque independiente es compatible con RHEL 7.5 y versiones posteriores. RHEL recomienda el uso del enfoque independiente para todas las implementaciones nuevas.
Configuración de clúster
Los pasos generales para la configuración del clúster incluyen:
- Instale los paquetes de Pacemaker en ambos nodos del clúster.
# yum -y install pcs pacemaker - Cree el HACLUSTER ID de usuario con.
Para usar# passwd haclusterpcspara configurar el clúster y comunicarse entre los nodos, debe establecer una contraseña en cada nodo para el ID de usuario hacluster , que es elpcscuenta de administración. Se recomienda que la contraseña para el usuario hacluster ser el mismo en cada nodo. - Habilite e inicie las
pcsservicios.# systemctl enable pcsd.service; systemctl start pcsd.service - Autenticar
pcscon hacluster usuario
Autenticar laspcsusuario hacluster para cada nodo del clúster. El siguiente comando autentica al usuario hacluster en nodo1 para ambos nodos en un clúster de dos nodos (node1.example.com y node2.example.com).# pcs cluster auth node1.example.com node2.example.com Username: hacluster Password: node1.example.com: Authorized node2.example.com: Authorized - Cree el clúster.
Clúster nwha se crea utilizando el nodo 1 y el nodo 2:# pcs cluster setup --name nwha node1 node2 - Inicie el clúster.
# pcs cluster start --all - Habilite el inicio automático del clúster después de reiniciar.
# pcs cluster enable --all
Creación de recursos para instancias de ASCS y ERS
Ahora que el clúster está configurado, debe agregar los recursos para los nodos ASCS y ERS. Los pasos generales incluyen:
- Instalar
resource-agents-sapen todos los nodos del clúster.# yum install resource-agents-sap - Configure el sistema de archivos compartido como recursos administrados por el clúster.
El sistema de archivos compartido, como/sapmnt,/usr/sap/trans,/usr/sap/se agregan como recursos montados automáticamente en el clúster mediante el comando:SYS # pcs resource create <resource-name> Filesystem device=’<path-of-filesystem>’ directory=’<directory-name>’ fstype=’<type-of-fs>’
Ejemplo:# pcs resource create sid_fs_sapmnt Filesystem device='nfs_server:/export/sapmnt' directory='/sapmnt' fstype='nfs' - Configure el grupo de recursos para ASCS.
Para el nodo ASCS, los tres grupos de recursos necesarios son los siguientes (suponiendo que el ID de instancia de ASCS sea 00):- Dirección IP virtual para el ASCS
- Sistema de archivos ASCS (por ejemplo,
/usr/sap/<SID>/ASCS00) - Instancia de perfil ASCS (por ejemplo,
/sapmnt/<SID>/profile/<SID>_ASCS00_<hostname>)
- Configure el grupo de recursos para ERS.
Para el nodo ERS, los tres grupos de recursos necesarios son los siguientes (suponiendo que el ID de instancia de ERS sea 30):- Dirección IP virtual para el ERS
- Sistema de archivos ERS (por ejemplo,
/usr/sap/<SID>/ERS30) - Instancia de perfil ERS (por ejemplo,
/sapmnt/<SID>/profile/<SID>_ERS30_<hostname>)
- Cree las restricciones.
Establezca las restricciones del grupo de recursos ASCS y ERS para lo siguiente:- Restringir la ejecución de ambos grupos de recursos en el mismo nodo
- Hacer que ASCS se ejecute en el nodo donde se ejecutaba ERS en caso de una conmutación por error
- Mantener la secuencia de orden de inicio/parada
- Asegúrese de que el clúster se inicie solo después de que se hayan montado los sistemas de archivos requeridos
Pruebas de conmutación por error de clúster
Suponiendo que ASCS se ejecuta en node1 y ERS se ejecuta en node2 inicialmente. Si nodo1 cae, ASCS y ERS cambian a node2 . Debido a la restricción definida, ERS no se ejecutará en node2 .
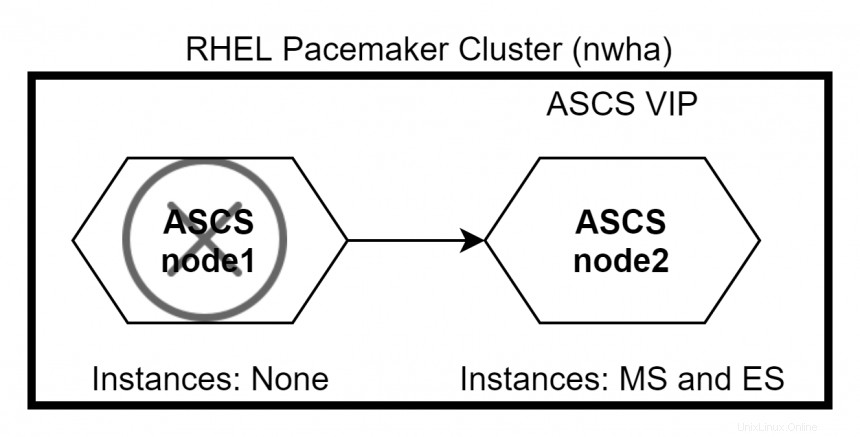
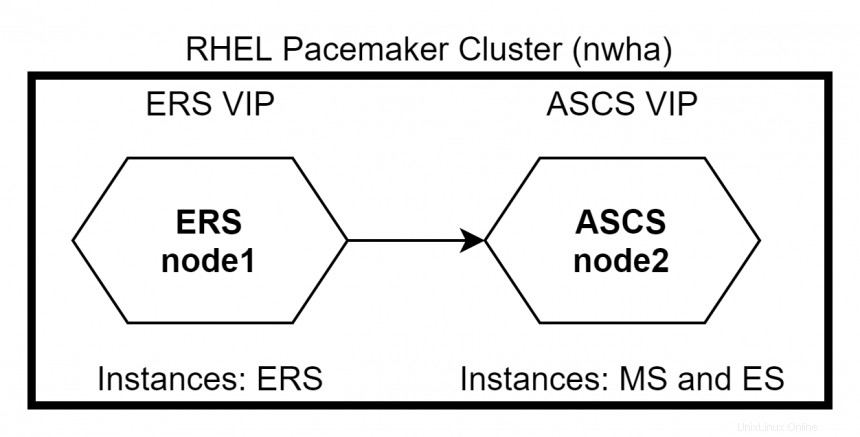
Cuando nodo1 vuelve a funcionar, ERS cambiará a node1 mientras ASCS permanece en node2 . Usa el comando #pcs status para comprobar el estado del clúster.
[ Un curso gratuito para usted:Resumen técnico de virtualización y migración de infraestructura. ]
Terminar
RHEL Pacemaker es una gran utilidad para lograr un clúster de alta disponibilidad para SAP. También puede realizar vallas configurando STONITH para garantizar la integridad de los datos y evitar la utilización de recursos por parte de un nodo defectuoso en el clúster.
Para todos los entusiastas de la automatización, puede utilizar Ansible para controlar su clúster de Pacemaker mediante el uso del módulo pacemaker_cluster de Ansible. Por mucho que protejas tus sistemas, cuídate y mantente a salvo.