Antes de realizar un recorrido en profundidad por esta guía de artículos, primero debemos comprender qué está tratando de descubrir el artículo. Necesitamos entender o responder a la pregunta 'por qué es importante contar archivos en Linux '. La ambición de todo administrador de Linux es estar familiarizado con los entresijos de la arquitectura de su sistema operativo.
Por lo tanto, conocer la ubicación y la cantidad de archivos de directorio que tiene que administrar/gestionar es igualmente importante. En este caso, podría tener miles de archivos generados manual o automáticamente por usuarios del sistema o programas y desea realizar un seguimiento de su número creciente o finito.
Hay varios comandos integrados basados en Linux que pueden ayudarlo fácilmente en tales circunstancias. Sin embargo, si buscamos la forma más rápida de lograr el objetivo de este artículo, debemos ser exigentes y considerar otras opciones viables.
Manera rápida de contar archivos recursivamente en Linux
Pocos comandos de Linux destacan en cuanto a contar archivos de forma recursiva y rápida. Comparemos los dos más populares.
Comando de búsqueda de Linux versus comando de localización
Para fines de demostración, apuntaremos a la cantidad de archivos dentro de /home/user directorio del sistema operativo Linux.
Para obtener la diferencia de velocidad entre el comando de búsqueda y el comando de localización, asociaremos su ejecución con el tiempo incorporado de Linux. comando para que podamos averiguar qué método de contar archivos recursivamente es más rápido.
Dado que el comando de búsqueda ya está preinstalado en su sistema Linux, solo necesitamos instalar el localizar comando antes de que iniciemos su comparación de velocidad de ejecución.
$ sudo apt-get install mlocate [On Debian, Ubuntu and Mint] $ sudo yum install mlocate [On RHEL/CentOS/Fedora and Rocky Linux/AlmaLinux] $ sudo emerge -a sys-apps/mlocate [On Gentoo Linux] $ sudo pacman -S mlocate [On Arch Linux] $ sudo zypper install mlocate [On OpenSUSE]
En referencia a esta guía de artículos, el principal ubicar comando [OPCIÓN] lo que nos interesa es -c , -count ya que buscamos una salida estándar que refleje un número consultado de conteos de archivos.
Primero, usemos el comando de búsqueda para contar la cantidad de archivos dentro de /home/user directorio. Su comando debería parecerse a lo siguiente:
$ time find /home/dnyce -type f | wc -l
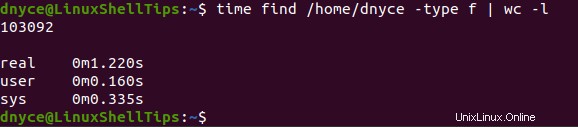
En segundo lugar, veamos qué resulta en localizar el comando rendirá para contar archivos en ese mismo /home/user directorio. Su implementación de comandos es la siguiente:
$ time locate -c /home/dnyce
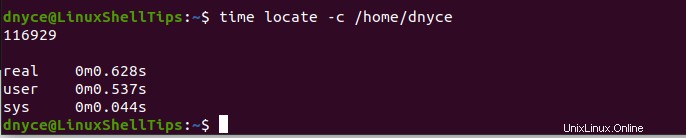
Con el tiempo comando que realiza un seguimiento del tiempo de ejecución de estos dos comandos (buscar y localizar ), podemos notar que el localizar El comando profundizó recursivamente para producir más conteos de archivos en menos tiempo.
Para utilizar Linux localizar comando, debe cumplir con la siguiente regla de sintaxis:
$ locate [OPTION]… [PATTERN]…
Comprobando el localizar página del comando man ($ man locate) , también se dará cuenta de que este comando también se puede usar para otras funcionalidades viables relacionadas con archivos.
Además, incluso si traemos otro comando popular (comando ls) para contar archivos en un directorio de destino, no será recursivamente más profundo y rápido al nivel de localizar comando.
$ time ls /home/dnyce | wc -l
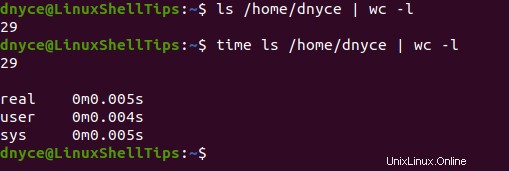
El localizar el comando es más rápido que buscar porque su algoritmo de conteo de archivos está orientado a la base de datos y no al sistema de archivos como su contraparte.
El comportamiento funcional predeterminado de localizar El comando es ignorar la existencia de los archivos consultados fuera del alcance de la base de datos. Además, después de una actualización exitosa más reciente de la base de datos en los archivos existentes, ubicar El comando no informa inmediatamente de la creación de nuevos archivos.