Al sistema operativo Linux le gusta presumir de su potencia y destreza informática. Su enfoque algorítmico para cosas como el procesamiento de archivos, especialmente bajo la administración de archivos, produce hitos importantes para los usuarios de Linux en la búsqueda de dominar las huellas de administración de Linux.
Un aspecto del procesamiento de archivos en el entorno del sistema operativo Linux que debemos tener muy en cuenta es identificar las líneas más largas dentro de un archivo compatible con Linux editable.
Implicación práctica de líneas largas en un archivo
Considere el escenario en el que trabaja en una empresa o está lidiando con un proyecto que procesa archivos de registro enormes. Estos archivos pueden representarse como líneas de texto individuales cuando en realidad pueden encapsular miles de documentos JSON.
Si el tamaño de estas líneas de texto es muy/inusualmente largo, es posible que sea necesario procesarlas a través de un servidor proxy para redirigir correctamente los archivos a un servidor de destino como un servidor de búsqueda elástico.
Sin embargo, estos pasos cuidadosos para el procesamiento de archivos pueden conducir a errores de procesamiento de archivos no deseados cuando en realidad solo está lidiando con líneas extra largas en sus archivos. Es imposible diagnosticar un error de este tipo sin conocer la amenaza en juego.
Este tutorial le llevará a través de los pasos necesarios para identificar las líneas más largas dentro de un archivo de destino en un entorno de sistema operativo Linux.
Enunciado del problema
Para hacer que este artículo sea más divertido y atractivo, vamos a crear un archivo de texto de referencia con varias líneas diferentes y luego implementaremos soluciones válidas de Linux para encontrar las líneas más largas.
$ sudo nano sample_file.txt
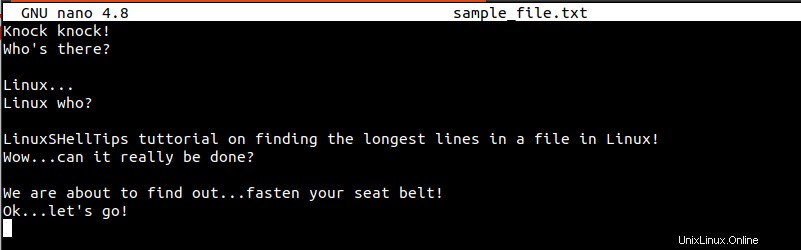
Nos esforzaremos por identificar las líneas más largas en el archivo anterior (sample_file.txt ) a través de útiles comandos de Linux.
1. Encuentra la línea más larga en un archivo usando el comando Awk
Idealmente, podríamos anteponer todas las líneas en el archivo anterior usando un awk de una sola línea comando para determinar sus longitudes exactas como se muestra a continuación.
$ awk '{printf "%2d| %s\n",length,$0}' sample_file.txt
Según la captura de pantalla anterior, 73 es la longitud de línea más grande.
Imprimir la línea más larga en un archivo usando los comandos wc y grep
Al combinar estos dos comandos, puede usar expresiones regulares del comando grep y max-line-length del comando wc. El wc el comando toma el -L opción de comando para determinar la longitud máxima de línea como se muestra a continuación.
$ grep -E "^.{$(tr '\t' ' ' El comando anterior debe imprimir las líneas más largas en el archivo sample_file.txt .

Dado que teníamos dos líneas idénticas con la mayor longitud de línea de 73 , el comando anterior imprimió los dos líneas. Si fuera solo una línea con la mayor longitud de línea de 73, solo se imprimiría esa línea.
Ahora nos sentimos cómodos buscando la(s) línea(s) más larga(s) en un archivo en Linux.