Dado que ya se ha establecido que el sistema operativo Linux es el mejor en todos los oficios informáticos a través de los numerosos consejos y artículos sobre la línea de comandos de Linux que ha encontrado en este sitio.
Es hora de hacer crecer aún más la reputación de este sistema operativo. Como parte de la administración de archivos de Linux, buscaremos formas de mezclar líneas en un archivo que reside en un entorno de sistema operativo Linux.
Mezclar líneas en un archivo en un entorno de sistema operativo Linux puede tomar dos enfoques. En el enfoque uno, es posible que desee mezclar/reorganizar las líneas en un archivo de destino para que aparezcan en un orden requerido específico. En tal caso, se invoca un comando de clasificación.
En el enfoque 2, no tiene en cuenta el orden en que deben aparecer las líneas finales en el archivo de destino. En tales casos, un comando shuf es llamado.
Este artículo nos llevará a través de diferentes técnicas de Linux para mezclar líneas aleatoriamente en un archivo en Linux.
Enunciado del problema
Tendremos que crear un archivo de texto de muestra con unas pocas líneas al que nos referiremos mientras implementamos y ejecutamos varios comandos de reproducción aleatoria de Linux que se analizarán.
$ sudo nano sample_file.txt
Podemos usar el comando cat para la vista numerada de este archivo completo:
$ cat -n sample_file.txt
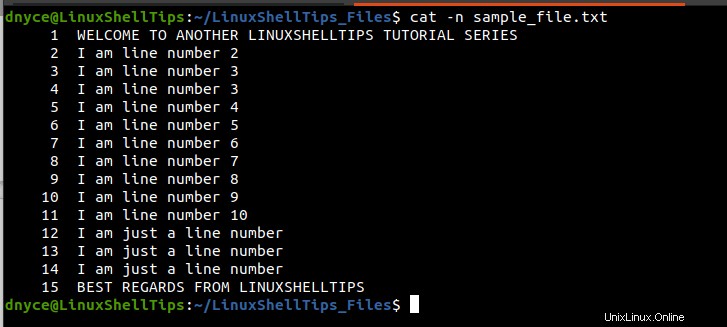
El comando gato la salida nos dice que estamos tratando con un archivo de texto con un total de 15 líneas. Además, como habrás notado, las líneas 12 a 14 son repetitivos. La aparición de estas tres líneas nos ayudará a comprender cómo funcionan los diferentes comandos de barajado.
Mezclar líneas utilizando el comando Shuf en Linux
Desde las GNU Coreutils anfitriones del paquete shuf comando, debe instalarse de forma predeterminada en la distribución de su sistema operativo Linux. La función principal del shuf El comando es generar permutaciones aleatorias basadas en una entrada que se le alimenta.
El mecanismo de trabajo del shuf el comando es el siguiente; primero carga los datos de entrada en la memoria, indica si la memoria libre es más grande que el tamaño del archivo/datos de entrada antes de continuar con su ejecución.
Su sintaxis es la siguiente:
$ shuf [TARGET_INPUT_FILE]
En nuestro caso, su implementación será la siguiente:
$ shuf sample_file.txt
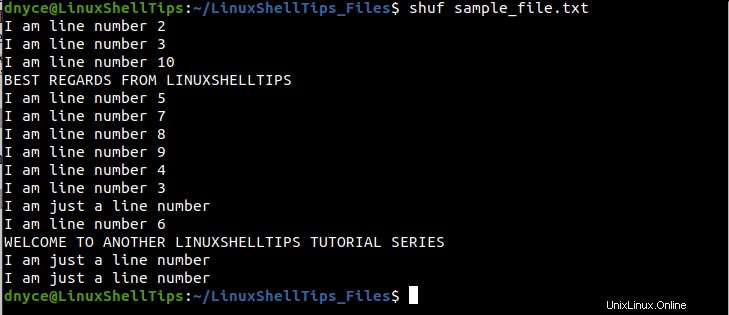
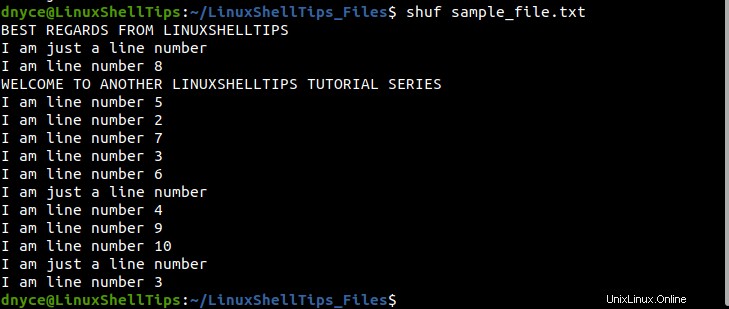
Como puede ver, hemos logrado mezclar aleatoriamente las líneas en nuestro archivo de texto de muestra. Si ejecuta el shuf comando, una y otra vez, obtendrá un resultado diferente cada vez:
$ shuf random_file.txt
Usar el comando Ordenar para barajar líneas en Linux
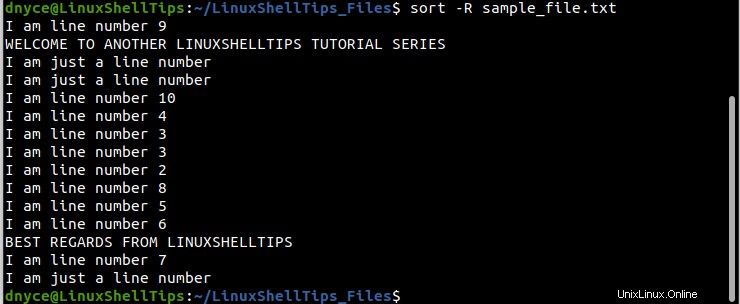
Mientras que ordenar se usa principalmente para reorganizar las líneas de un archivo de una manera específica, podemos aleatorizar estas líneas de archivo si combinamos el ordenar comando con -R opción.
$ sort -R sample_file.txt
Ejecutar el comando una y otra vez debería producir resultados diferentes cada vez.
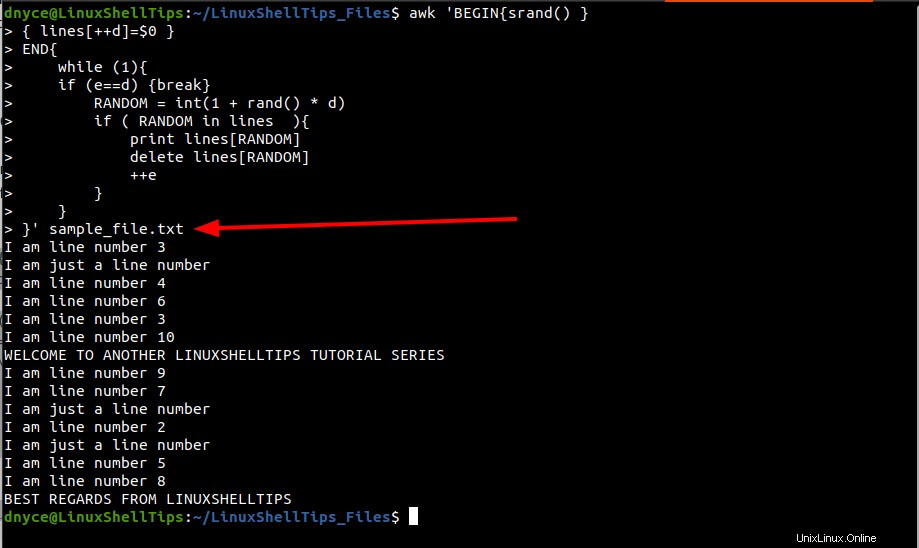
Utilice el comando Awk para mezclar líneas de archivo en Linux
Según su página man de Linux (man awk ), wow es un lenguaje de programación de procesamiento de texto y escaneado de patrones perfecto. Sin embargo, para comprender su uso en la combinación de líneas, necesitará cierta exposición a conceptos de programación como variables, bucles (bucles while) y sentencias (sentencia if) como se muestra a continuación:
awk 'BEGIN{srand() }
{ lines[++d]=$0 }
END{
while (1){
if (e==d) {break}
RANDOM = int(1 + rand() * d)
if ( RANDOM in lines ){
print lines[RANDOM]
delete lines[RANDOM]
++e
}
}
}' sample_file.txt
Ahora nos sentimos cómodos mezclando líneas en un archivo en Linux.