Si usa Linux para el trabajo regular o para desarrollar e implementar software, debe haberse topado con el comando grep.
En este artículo explicativo, le diré qué es el comando grep y cómo funciona.
¿Qué es grep?
Grep es una utilidad de línea de comandos en sistemas Unix y Linux. Se utiliza para encontrar patrones de búsqueda en el contenido de un archivo determinado.
Con su nombre inusual, es posible que haya adivinado que grep es un acrónimo. Esto es al menos parcialmente cierto, pero depende de a quién le preguntes.
Según fuentes acreditadas, el nombre en realidad se deriva de un comando en un editor de texto UNIX llamado ed. En el cual, la entrada g/re/p realizó una búsqueda global (g) de una expresión regular (re) y posteriormente imprimió (p) cualquier línea coincidente.
El comando grep hace lo que hicieron los comandos g/re/p en el editor. Realiza una búsqueda global de una expresión regular y la imprime. Es mucho más rápido en la búsqueda de archivos de gran tamaño.

Esta es la narrativa oficial, pero también puede verla descrita como G global R E regular xpresión (P procesador | P arser | P impresora). A decir verdad, hace todo eso.
La interesante historia detras de la creacion de grep
Ken Thompson ha hecho algunas contribuciones increíbles a la informática. Ayudó a crear Unix, popularizó su enfoque modular y escribió muchos de sus programas, incluido grep.
Thompson creó grep para ayudar a uno de sus colegas en Bell Labs. El objetivo de este científico era examinar los patrones lingüísticos para identificar a los autores (incluido Alexander Hamilton) de los Federalist Papers. Este extenso cuerpo de trabajo fue una colección de 85 artículos y ensayos anónimos redactados en defensa de la Constitución de los Estados Unidos. Pero dado que estos artículos eran anónimos, el científico estaba tratando de identificar a los autores según el patrón lingüístico.
El editor de texto original de Unix, ed, (también creado por Thompson) no era capaz de buscar en un cuerpo de texto tan grande dadas las limitaciones de hardware de la época. Entonces, Thompson transformó la función de búsqueda en una utilidad independiente, independiente del editor de ed.
Si lo piensas bien, eso significa que Alexander Hamilton técnicamente ayudó a crear grep. Siéntase libre de compartir este hecho divertido con sus amigos en su fiesta de relojes Hamilton. 🤓
¿Qué es una expresión regular, otra vez?
Una expresión regular (o regex) se puede considerar como una especie de consulta de búsqueda. Las expresiones regulares se utilizan para identificar, hacer coincidir o administrar el texto.
Sin embargo, Regex es capaz de mucho más que búsquedas de palabras clave. Se puede utilizar para encontrar cualquier tipo de patrón imaginable. Los patrones se pueden encontrar más fácilmente usando metacaracteres. Estos caracteres especiales que hacen que esta herramienta de búsqueda sea mucho más poderosa.

Cabe señalar que grep es solo una herramienta que usa expresiones regulares. Hay capacidades similares en toda la gama de herramientas, pero los metacaracteres y la sintaxis pueden variar. Esto significa que es importante conocer las reglas de su procesador de expresiones regulares en particular.
Un ejemplo práctico de grep:coincidencia de números de teléfono
Esta herramienta puede resultar intimidante tanto para los novatos como para los usuarios experimentados de Linux. Desafortunadamente, incluso un patrón relativamente simple como un número de teléfono puede dar como resultado una cadena de expresiones regulares de aspecto "aterrador".
Quiero asegurarles que no hay necesidad de entrar en pánico cuando vean expresiones como esta. Una vez que se familiarice con los conceptos básicos de expresiones regulares, puede abrir un nuevo mundo de posibilidades para su computación.
Nota cultural :este ejemplo utiliza las convenciones de EE. UU. (NANP) para los números de teléfono. Estas son identificaciones de 10 dígitos que se dividen en un código de área (3 dígitos) y una combinación única de 7 dígitos donde los primeros 3 dígitos corresponden a una oficina central de telecomunicaciones (conocido como prefijo) y los últimos 4 se llaman la línea número. Entonces el patrón es AAA-PPP-LLLL.
Creé un archivo llamado phone.txt y anotó 4 variaciones comunes del mismo número de teléfono. Voy a usar grep para reconocer el patrón numérico independientemente del formato.
También agregué una línea que no se ajustará a la expresión para usar como control. La línea final 555!123!1234 no es un patrón de número de teléfono estándar y la expresión grep no lo devolverá.
Contenido de phone.txt los archivos son:
example@unixlinux.online:~$ cat phone.txt
5551231234
555 123 1234
555-123-1234
(555)-123-1234
555!123!1234
Para "grep" los números de teléfono, voy a escribir mi expresión regular usando metacaracteres para aislar los datos relevantes e ignorar lo que no necesito.
El comando completo se verá así:
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
Se ve un poco intenso, ¿verdad? Dividámoslo en partes para tener una mejor idea de lo que está sucediendo.
Comprender regex, un segmento a la vez
Primero separemos la sección del RegEx que busca el "código de área" en el número de teléfono.
También se repite parcialmente un patrón similar para obtener el resto de los dígitos. Es importante tener en cuenta que el código de área a veces se encapsula entre paréntesis, por lo que debe tenerlo en cuenta con la expresión aquí.
La lógica de toda la sección del código de área está encapsulada en un conjunto de llaves redondas con escape. Puedes ver que mi código comienza con \( y termina con \) .
Cuando usa corchetes [0-9] , le está haciendo saber a grep que está buscando un número entre 0 y 9. De manera similar, podría usar [a-z] para hacer coincidir las letras del alfabeto.
El número entre llaves {3\} , significa que el elemento entre llaves cuadradas coincide exactamente tres veces.
¿Sigo confundido? No te estreses. Vas a ver este ejemplo de varias maneras para que te sientas seguro de seguir adelante.
Intentemos ver la lógica de la sección del código de área en pseudocódigo. He aislado cada segmento de la expresión.
Pseudocódigo del código de área RegEx
- \(
- (Número de 3 dígitos)
- |
- Número de 3 dígitos
- \)
Con suerte, verlo así hace que la expresión regular sea más sencilla. En lenguaje sencillo, está buscando números de 3 dígitos. Cada dígito puede ser del 0 al 9, y puede haber o puede no haber paréntesis alrededor del código de área.
Luego, hay una parte rara al final de nuestra primera sección.
- [-]\?
¿Qué significa? El \? símbolo significa "coincidencia con cero o uno del carácter anterior". Aquí, eso se refiere a lo que está entre corchetes [ -] .
En otras palabras, puede haber o no un guión después de los dígitos.
Código de área
Ahora, reconstruyamos el mismo bloque con el código real. Luego, agregaré las otras partes de la expresión.
- \(
- ([0-9]\{3\})
- |
- [0-9]\{3\}
- \)
- [-]\?
Prefijo
Para completar el patrón del número de teléfono, puede reutilizar parte de su código existente.
[0-9]\{3\}[ -]\?
No tiene que preocuparse por los paréntesis que rodean el prefijo, pero aún puede o no tener un - entre el prefijo y los dígitos de línea del número de teléfono.
Números de línea
La última sección del número de teléfono no requiere que busquemos ningún otro carácter, pero debe actualizar la expresión para reflejar el dígito adicional.
[0-9]\{4\}
Eso es todo. Ahora asegurémonos de que la expresión esté entre comillas para minimizar comportamientos inesperados.
Aquí está la expresión completa de nuevo
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
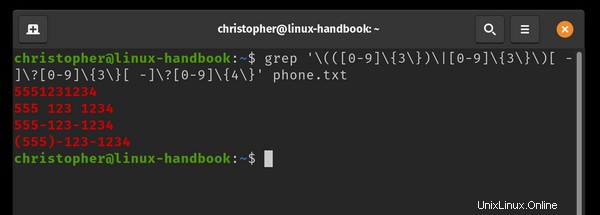
Puede ver que los resultados están resaltados en color. Es posible que este no sea el comportamiento predeterminado en su distribución de Linux.
Consejo adicional
Si desea que sus resultados se destaquen, puede agregar --color=auto a tu mando. También puede agregar esto a su perfil de shell como un alias para que cada vez que escriba grep se ejecuta como grep --color=auto .
Espero que ahora comprenda mejor el comando grep. Mostré solo un ejemplo para explicar las cosas. Si está interesado, puede consultar este artículo para obtener más ejemplos prácticos del comando grep.
Proporcione su sugerencia sobre el artículo dejando un comentario.