Curl es una excelente herramienta para descargar archivos en la terminal de Linux.
La sintaxis habitual para descargar un archivo con el mismo nombre que el archivo original es bastante simple:
curl -O URL_of_the_fileEsto funciona la mayor parte del tiempo. Sin embargo, notará que, a veces, cuando descarga un archivo de GitHub o SourceForge, no obtiene el archivo correcto.
Por ejemplo, estaba tratando de descargar el script archinstall en formato tar gz. Los archivos se encuentran en la página de publicación.
Si abro este enlace del código fuente en un navegador, me da el código fuente en formato .tar.gz.
Sin embargo, si uso la terminal para descargar el mismo archivo usando el comando curl, obtengo un archivo pequeño que no está en el formato de archivo correcto.
tar -zxvf v2.4.2.tar.gz
gzip: stdin: not in gzip format
tar: Child returned status 1
tar: Error is not recoverable: exiting now
Cuando ejecuto el comando de archivo para saber el tipo de archivo exacto, me dice que es un documento HTML.
file v2.4.2.tar.gz
v2.4.2.tar.gz: HTML document, ASCII text, with no line terminators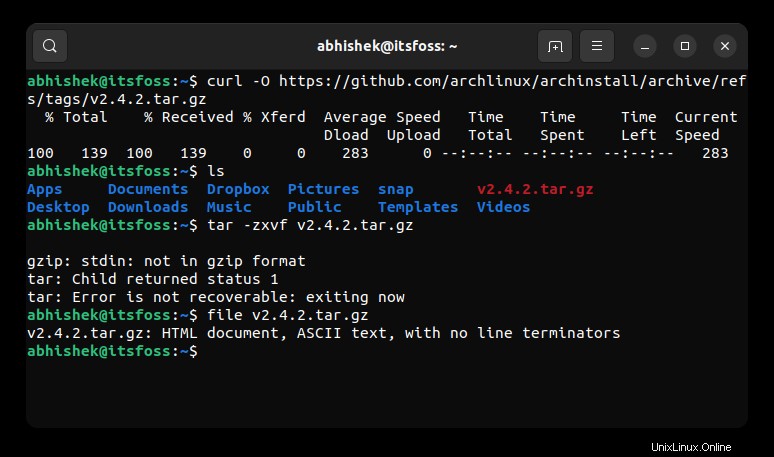
¿Documento HTML en lugar del archivo zip o tarball? ¿Dónde está el problema? Déjame mostrarte la solución rápida.
Descargar correctamente el archivo de almacenamiento con curl
El problema aquí es que la URL que tiene redirige al archivo de almacenamiento real. Para obtener eso, necesita usar opciones adicionales.
curl -JLO URL_of_the_fileLas opciones pueden estar en cualquier orden. Es más fácil recordar a J LO (Jennifer López).
Aquí hay una explicación rápida de las opciones basadas en la página de manual del comando curl.
- J:esta opción le dice a la opción -O, --remote-name que use el nombre de archivo de disposición de contenido especificado por el servidor en lugar de extraer un nombre de archivo de la URL.
- L:si el servidor informa que la página solicitada se ha movido a una ubicación diferente (indicada con un encabezado Ubicación:y un código de respuesta 3XX), esta opción hará que curl rehaga la solicitud en el nuevo lugar.
- O:Con esta opción, no necesita especificar el nombre del archivo de salida para la descarga.
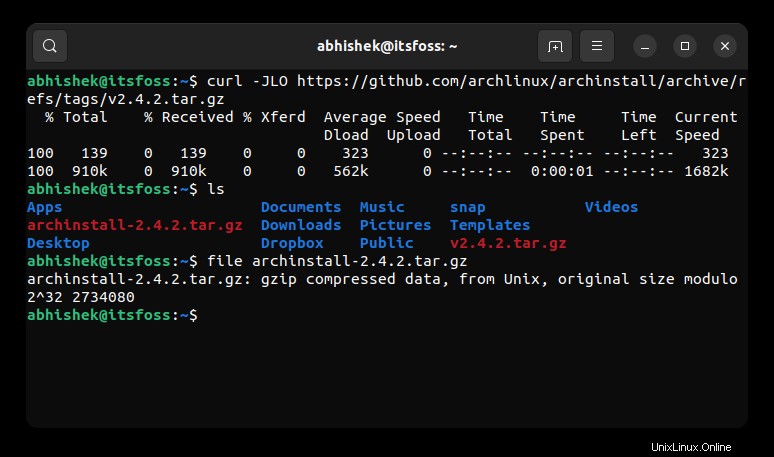
Como puede ver en la captura de pantalla a continuación, pude descargar el archivo correcto esta vez con la opción curl -JLO.
Consejo extra:¿Necesita iniciar sesión?
Esto funciona para los archivos públicos. Pero si intenta descargar archivos desde repositorios privados o GitLab, es posible que vea un mensaje sobre la redirección a la página de inicio de sesión.
<html><body>You are being <a href="https://gitlab.com/users/sign_in">redirected</a>.</body></html>
En tales casos, proporcione el token API con la opción -H.
Espero que este pequeño consejo rápido te ayude a descargar correctamente los archivos comprimidos con Curl. Avíseme si todavía tiene problemas con las descargas de curl.