Para trabajar con éxito con el editor sed de Linux y el comando awk en sus scripts de shell, debe comprender las expresiones regulares o, en resumen, regex. Dado que hay muchos motores para expresiones regulares, usaremos la expresión regular de shell y veremos el poder de bash al trabajar con expresiones regulares.
Primero, necesitamos entender qué es regex; luego veremos cómo usarlo.
¿Qué es la expresión regular
Para algunas personas, cuando ven las expresiones regulares por primera vez, dicen ¡qué son estos vómitos ASCII!
Bueno, una expresión regular o regex, en general, es un patrón de texto que defines que un programa de Linux como sed o awk usa para filtrar texto.
Vimos algunos de esos patrones al presentar los comandos básicos de Linux y vimos cómo el comando ls usa caracteres comodín para filtrar la salida.
Tipos de expresiones regulares
Muchas aplicaciones diferentes usan diferentes tipos de expresiones regulares en Linux, como la expresión regular incluida en lenguajes de programación (Java, Perl, Python) y programas de Linux como (sed, awk, grep) y muchas otras aplicaciones.
Un patrón regex usa un motor de expresión regular que traduce esos patrones.
Linux tiene dos motores de expresiones regulares:
- La expresión regular básica (BRE) motor.
- La expresión regular extendida (ERE) motor.
La mayoría de los programas de Linux funcionan bien con las especificaciones del motor BRE, pero algunas herramientas como sed comprenden algunas de las reglas del motor BRE.
El motor POSIX ERE viene con algunos lenguajes de programación. Proporciona más patrones, como dígitos y palabras coincidentes. El comando awk usa el motor ERE para procesar sus patrones de expresiones regulares.
Dado que hay muchas implementaciones de expresiones regulares, es difícil escribir patrones que funcionen en todos los motores. Por lo tanto, nos centraremos en la expresión regular más común y demostraremos cómo usarla en sed y awk.
Definir patrones BRE
Puede definir un patrón para que coincida con texto como este:
$ echo "Testing regex using sed" | sed -n '/regex/p'
$ echo "Testing regex using awk" | awk '/regex/{print $0}'

Puede notar que a la expresión regular no le importa dónde ocurre el patrón o cuántas veces en el flujo de datos.
La primera regla que debe saber es que los patrones de expresiones regulares distinguen entre mayúsculas y minúsculas.
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}' $ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'

La primera expresión regular tiene éxito porque la palabra "Geeks" existe en mayúsculas, mientras que la segunda línea falla porque usa letras minúsculas.
Puedes usar espacios o números en tu patrón como este:
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'

Caracteres especiales
Los patrones de expresiones regulares usan algunos caracteres especiales. Y no puedes incluirlos en tus patrones, y si lo haces, no obtendrás el resultado esperado.
Estos caracteres especiales son reconocidos por expresiones regulares:
.*[]^${}\+?|() Debe escapar de estos caracteres especiales usando el carácter de barra invertida (\).
Por ejemplo, si desea hacer coincidir un signo de dólar ($), escápelo con un carácter de barra invertida como este:
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile
Si necesita hacer coincidir la barra invertida (\), debe escapar de esta manera:
$ echo "\ is a special character" | awk '/\\/{print $0}'

Aunque la barra inclinada no es un carácter especial, aún recibe un error si lo usa directamente.
$ echo "3 / 2" | awk '///{print $0}'

Así que necesitas escapar así:
$ echo "3 / 2" | awk '/\//{print $0}'

Personajes ancla
Para ubicar el comienzo de una línea en un texto, use el carácter de intercalación (^).
Puedes usarlo así:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

El carácter de intercalación (^) coincide con el inicio del texto:
$ awk '/^this/{print $0}' myfile

¿Qué pasa si lo usas en medio del texto?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

Está impreso como si fuera un carácter normal.
Cuando usas awk, tienes que escapar así:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

Se trata de mirar el principio del texto, ¿y mirar el final?
El signo de dólar ($) comprueba el final de una línea:
$ echo "Testing regex again" | awk '/again$/{print $0}'

Puede usar tanto el símbolo de intercalación como el signo de dólar en la misma línea de esta manera:
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
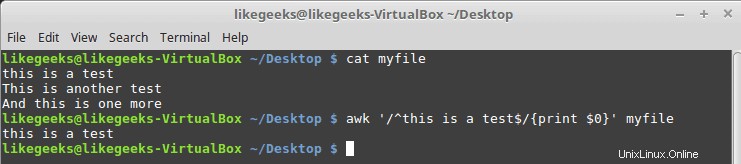
Como puede ver, imprime solo la línea que tiene el patrón coincidente.
Puede filtrar líneas en blanco con el siguiente patrón:
$ awk '!/^$/{print $0}' myfile ¡Aquí introducimos la negación que puedes hacer con el signo de exclamación!
El patrón busca líneas vacías donde no haya nada entre el principio y el final de la línea y niega que para imprimir solo las líneas tengan texto.
El carácter de punto
Usamos el carácter de punto para hacer coincidir cualquier carácter excepto la nueva línea (\n).
Mira el siguiente ejemplo para hacerte una idea:
$ cat myfile this is a test This is another test And this is one more start with this
$ awk '/.st/{print $0}' myfile
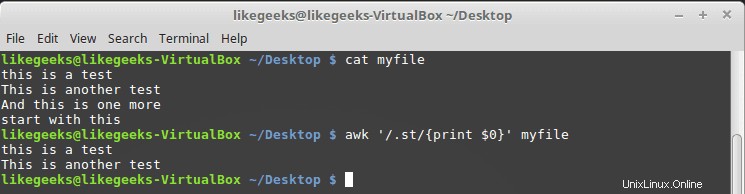
Puede ver en el resultado que imprime solo las dos primeras líneas porque contienen el patrón st mientras que la tercera línea no tiene ese patrón, y la cuarta línea comienza con st, por lo que tampoco coincide con nuestro patrón.
Clases de personajes
Puede hacer coincidir cualquier carácter con el carácter especial de punto, pero si solo hace coincidir un conjunto de caracteres, puede usar una clase de carácter.
La clase de carácter coincide con un conjunto de caracteres si alguno de ellos se encuentra, el patrón coincide.
Podemos definir las clases de caracteres usando corchetes [] así:
$ awk '/[oi]th/{print $0}' myfile
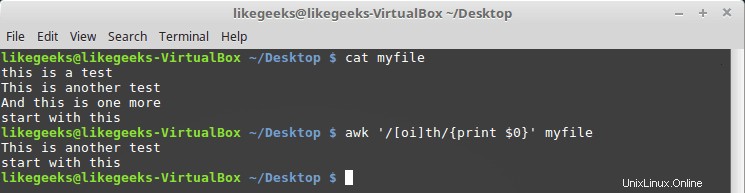
Aquí buscamos cualquier carácter th que tenga el carácter o o i antes.
Esto resulta útil cuando busca palabras que pueden contener mayúsculas o minúsculas y no está seguro de ello.
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}' $ echo "Testing regex" | awk '/[Tt]esting regex/{print $0}'

Por supuesto, no se limita a los personajes; Puedes usar números o lo que quieras. Puedes emplearlo como quieras siempre que tengas la idea.
Negación de clases de caracteres
¿Qué pasa con la búsqueda de un personaje que no está en la clase de personaje?
Para lograrlo, preceda el rango de clases de caracteres con un signo de intercalación como este:
$ awk '/[^oi]th/{print $0}' myfile
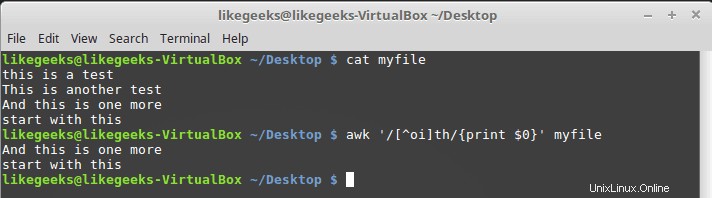
Así que cualquier cosa es aceptable excepto la o y la i.
Uso de rangos
Para especificar un rango de caracteres, puede usar el símbolo (-) como este:
$ awk '/[e-p]st/{print $0}' myfile
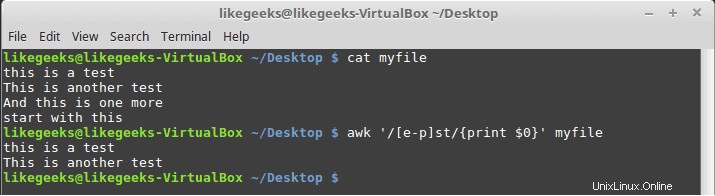
Esto hace coincidir todos los caracteres entre e y p seguidos de st como se muestra.
También puede usar rangos para números:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'

Puede usar rangos múltiples y separados como este:
$ awk '/[a-fm-z]st/{print $0}' myfile
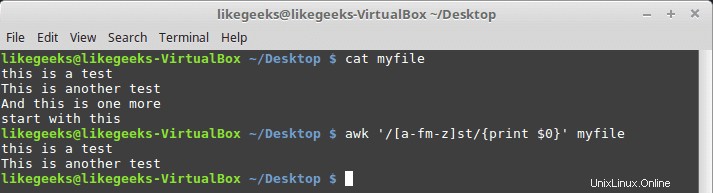
El patrón aquí significa de la a a la f, y de la m a la z deben aparecer antes del texto st.
Clases de personajes especiales
La siguiente lista incluye las clases de caracteres especiales que puede utilizar:
| [[:numero:]] | Patrón para 0–9, A–Z o a–z. |
| [[:en blanco:]] | Patrón para espacio o tabulación solamente. |
| [[:dígito:]] | Patrón de 0 a 9. |
| [[:inferior:]] | Patrón solo para minúsculas a–z. |
| [[:imprimir:]] | Patrón para cualquier carácter imprimible. |
| [[:punto:]] | Patrón para cualquier carácter de puntuación. |
| [[:espacio:]] | Patrón para cualquier carácter de espacio en blanco:espacio, tabulador, NL, FF, VT, CR. |
| [[:superior:]] | Patrón solo para mayúsculas de la A a la Z. |
Puedes usarlos así:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

El asterisco
El asterisco significa que el carácter debe existir cero o más veces.
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

Este símbolo de patrón es útil para verificar errores ortográficos o variaciones de idioma.
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green color" | awk '/colou*r/{print $0}'

Aquí, en estos ejemplos, ya sea que lo escriba color o el color coincidirá, porque el asterisco significa si el carácter "u" existió muchas veces o cero tiempo que coincidirá.
Para hacer coincidir cualquier número de cualquier carácter, puede usar el punto con el asterisco así:
$ awk '/this.*test/{print $0}' myfile
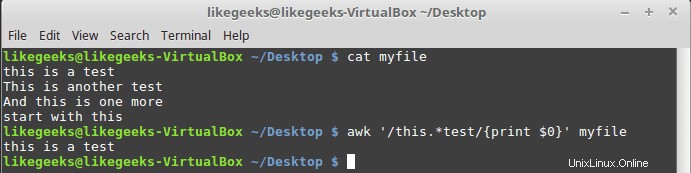
No importa cuántas palabras entre las palabras "esto" y "prueba", se imprimirá cualquier línea que coincida.
Puede usar el carácter de asterisco con la clase de carácter.
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'
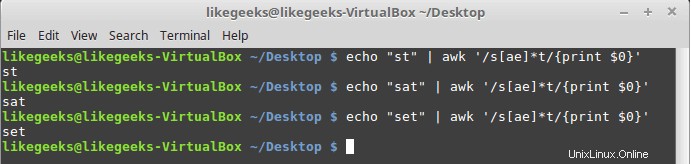
Los tres ejemplos coinciden porque el asterisco significa que si encuentra cero veces o más cualquier carácter "a" o "e", imprímalo.
Expresiones regulares extendidas
Los siguientes son algunos de los patrones que pertenecen a Posix ERE:
El signo de interrogación
El signo de interrogación significa que el carácter anterior puede existir una vez o ninguno.
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}'
Podemos usar el signo de interrogación en combinación con una clase de carácter:
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "taest" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}'
Si existe alguno de los elementos de la clase de carácter, se pasa la coincidencia de patrón. De lo contrario, el patrón fallará.
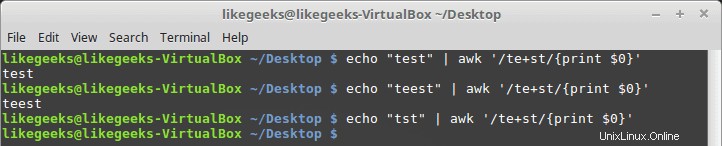
El signo más
El signo más significa que el carácter antes del signo más debe existir una o más veces, pero debe existir al menos una vez.
$ echo "test" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
Si no se encuentra el carácter "e", falla.
Puedes usarlo con clases de personajes como esta:
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'
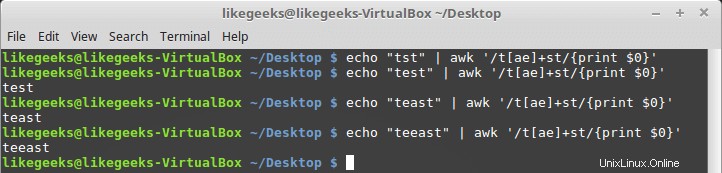
si existe algún carácter de la clase de carácter, tiene éxito.
llaves
Las llaves le permiten especificar el número de existencia de un patrón, tiene dos formatos:
n:la expresión regular aparece exactamente n veces.
n,m:la expresión regular aparece al menos n veces, pero no más de m veces.
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

En versiones anteriores de awk, debe usar la opción –re-interval para el comando awk para que lea llaves, pero en versiones más nuevas, no lo necesita.
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'

En este ejemplo, si el carácter "e" existe una o dos veces, tiene éxito; de lo contrario, falla.
Puedes usarlo con clases de personajes como esta:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
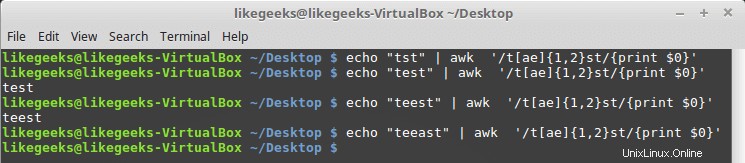
Si hay una o dos instancias de la letra "a" o "e", el patrón pasa; de lo contrario, falla.
Símbolo de tubería
El símbolo de la tubería hace un O lógico entre 2 patrones. Si uno de los patrones existe, tiene éxito; de lo contrario, falla, aquí hay un ejemplo:
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "Testing regular expressions" | awk '/regex|regular expressions/{print $0}' $ echo "This is something else" | awk '/regex|regular expressions/{print $0}'
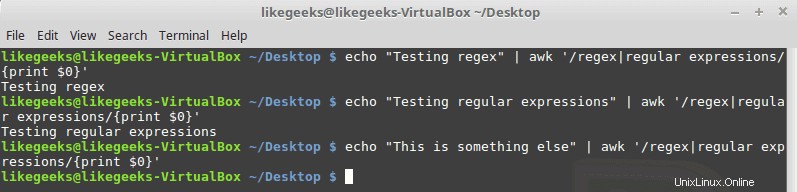
No escriba ningún espacio entre el patrón y el símbolo de tubería.
Expresiones de agrupación
Puede agrupar expresiones para que los motores de expresiones regulares las consideren una sola pieza.
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
La agrupación de los "Geeks" hace que el motor de expresiones regulares lo trate como una sola pieza, por lo que si existen "LikeGeeks" o la palabra "Me gusta", tiene éxito.
Ejemplos prácticos
Vimos algunas demostraciones simples del uso de patrones de expresiones regulares. Es hora de poner eso en práctica, solo para practicar.
Contar archivos de directorio
Veamos un script bash que cuenta los archivos ejecutables en una carpeta desde la variable de entorno PATH.
$ echo $PATH
Para obtener una lista de directorios, debe reemplazar cada dos puntos con un espacio.
$ echo $PATH | sed 's/:/ /g'
Ahora iteremos a través de cada directorio usando el bucle for como este:
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath; do done
Genial!!
Puede obtener los archivos en cada directorio usando el comando ls y guardarlos en una variable.
#!/bin/bash path_dir=$(echo $PATH | sed 's/:/ /g') total=0 for folder in $path_dir; do files=$(ls $folder) for file in $files; do total=$(($total + 1)) done echo "$folder - $total" total=0 done
Puede notar que algunos directorios no existen, no hay problema con esto, está bien.
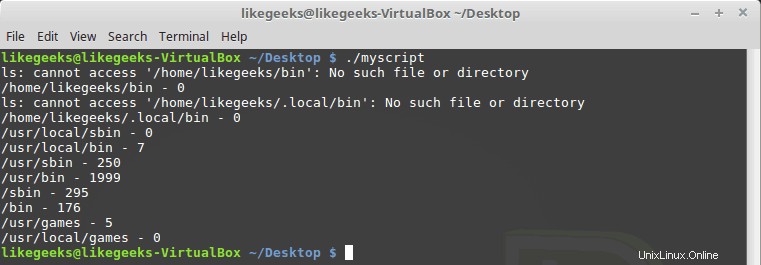
¡¡Enfriar!! Este es el poder de las expresiones regulares:estas pocas líneas de código cuentan todos los archivos en todos los directorios. Por supuesto, hay un comando de Linux para hacer eso muy fácilmente, pero aquí discutimos cómo emplear expresiones regulares en algo que puede usar. Puedes pensar en algunas ideas más útiles.
Validación de la dirección de correo electrónico
Hay un montón de sitios web que ofrecen patrones de expresiones regulares listos para usar para todo, incluido el correo electrónico, el número de teléfono y mucho más. Esto es útil, pero queremos entender cómo funciona.
ejemplo@unixlinux.online
El nombre de usuario puede usar cualquier carácter alfanumérico combinado con punto, guión, signo más, guión bajo.
El nombre de host puede usar cualquier carácter alfanumérico combinado con un punto y un guión bajo.
Para el nombre de usuario, el siguiente patrón se ajusta a todos los nombres de usuario:
^([a-zA-Z0-9_\-\.\+]+)@
El signo más significa que deben existir uno o más caracteres seguidos del signo @.
Entonces el patrón de nombre de host debería ser así:
([a-zA-Z0-9_\-\.]+)
Existen reglas especiales para los TLD o dominios de nivel superior, y deben tener no menos de 2 y cinco caracteres como máximo. El siguiente es el patrón de expresiones regulares para el dominio de nivel superior.
\.([a-zA-Z]{2,5})$ Ahora los ponemos todos juntos:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ Probemos esa expresión regular contra un correo electrónico:
$ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

Impresionante!!
Este fue solo el comienzo del mundo de expresiones regulares que nunca termina. Espero que entiendas estos vómitos ASCII 🙂 y los uses de manera más profesional.
Espero que les guste la publicación.
Gracias.