¿Necesita una plataforma de transmisión para manejar grandes cantidades de datos? Sin duda, ha oído hablar de Apache Kafka en Linux. Apache Kafka es perfecto para el procesamiento de datos en tiempo real y se está volviendo cada vez más popular. Instalar Apache Kafka en Linux puede ser un poco complicado, pero no se preocupe, este tutorial lo tiene cubierto.
En este tutorial, aprenderá a instalar y configurar Apache Kafka, para que pueda comenzar a procesar sus datos como un profesional, haciendo que su negocio sea más eficiente y productivo.
¡Siga leyendo y comience a transmitir datos con Apache Kafka hoy mismo!
Requisitos
Este tutorial será una demostración práctica. Si desea seguirnos, asegúrese de tener lo siguiente.
- Una máquina con Linux:esta demostración usa Debian 10, pero cualquier distribución de Linux funcionará.
- Una cuenta de usuario no raíz con privilegios sudo, necesaria para ejecutar Kafka, y llamada
kafkaen este tutorial. - Un usuario sudo exclusivo para Kafka:este tutorial utiliza un usuario sudo llamado kafka.
- Java:Java es una parte integral de la instalación de Apache Kafka.
- Git:este tutorial usa Git para descargar los archivos de la unidad Apache Kafka.
Instalando Apache Kafka
Antes de transmitir datos, primero deberá instalar Apache Kafka en su máquina. Dado que tiene una cuenta dedicada para Kafka, puede instalar Kafka sin preocuparse por romper su sistema.
1. Ejecute el mkdir Comando a continuación para crear /home/kafka/Downloads directorio. Puede nombrar el directorio como prefiera, pero el directorio se llama Descargas para esta demostración. Este directorio almacenará los binarios de Kafka. Esta acción garantiza que todos sus archivos para Kafka estén disponibles para el kafka usuario.
mkdir Downloads
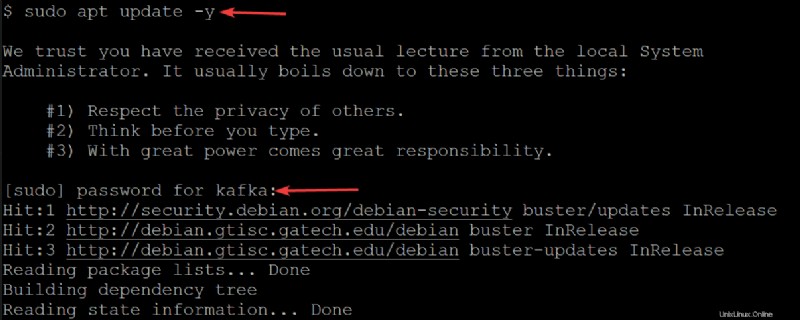
2. A continuación, ejecute el siguiente apt update comando para actualizar el índice de paquetes de su sistema.
sudo apt update -yIntroduzca la contraseña de su usuario de kafka cuando se le solicite.
3. Ejecute el curl Comando a continuación para descargar los binarios de Kafka desde el sitio web de Apache Foundation para generar (-o ) a un archivo binario (kafka.tgz ) en tu ~/Downloads directorio. Utilizará este archivo binario para instalar Kafka.
Asegúrese de reemplazar kafka/3.1.0/kafka_2.13-3.1.0.tgz con la última versión de los archivos binarios de Kafka. Al escribir estas líneas, la versión actual de Kafka es 3.1.0.
curl "https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz" -o ~/Downloads/kafka.tgz
4. Ahora, ejecuta el tar Comando a continuación para extraer (-x ) los binarios de Kafka (~/Downloads/kafka.tgz ) en el kafka creado automáticamente directorio. Las opciones en el tar comando realice lo siguiente:
Las opciones en el tar comando realice lo siguiente:
-v– Le dice altarComando para enumerar todos los archivos a medida que se extraen.
-z– Le dice altarComando para gzip el archivo mientras se descomprime. Este comportamiento no es necesario en este caso, pero es una excelente opción, especialmente si necesita un archivo comprimido/comprimido rápido para moverse.
-f– Le dice altarcomando qué archivo comprimido extraer.
-strip 1-Instruye altarcomando para eliminar el primer nivel de directorios de su lista de nombres de archivos. Como resultado, cree automáticamente un subdirectorio llamado kafka que contiene todos los archivos extraídos del~/Downloads/kafka.tgzarchivo.
tar -xvzf ~/Downloads/kafka.tgz --strip 1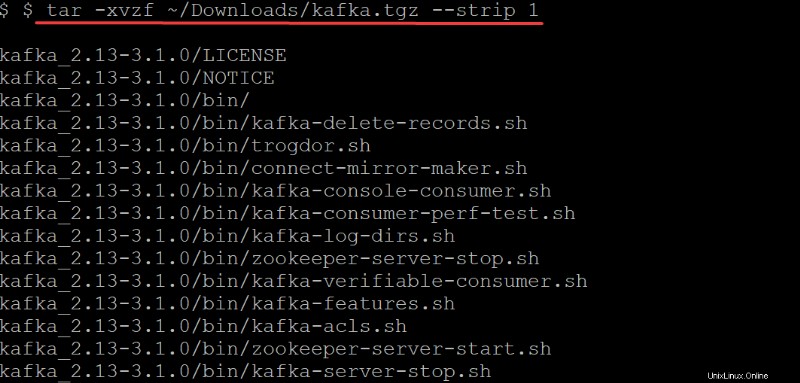
Configurando el Servidor Apache Kafka
En este punto, ha descargado e instalado los archivos binarios de Kafka en su ~/Downloads directorio. Todavía no puede usar el servidor de Kafka ya que, de forma predeterminada, Kafka no le permite eliminar ni modificar ningún tema, una categoría necesaria para organizar los mensajes de registro.
Para configurar su servidor Kafka, deberá editar el archivo de configuración de Kafka (/etc/kafka/server.properties).
1. Abra el archivo de configuración de Kafka (/etc/kafka/server.properties ) en su editor de texto preferido.
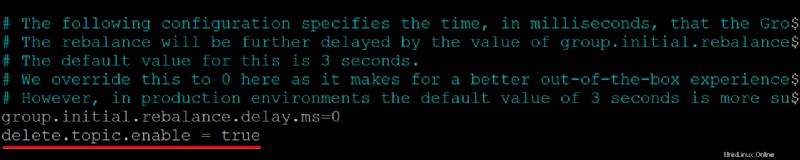
2. A continuación, agregue delete.topic.enable =true línea en la parte inferior de /kafka/config/server.properties contenido del archivo, guarde los cambios y cierre el editor.
Esta propiedad de configuración le otorga permiso para eliminar o modificar temas, así que asegúrese de saber lo que está haciendo antes de eliminar temas. Al eliminar un tema, también se eliminan las particiones de ese tema. Ya no se podrá acceder a los datos almacenados en esas particiones una vez que desaparezcan.
Asegúrese de que no haya espacios al comienzo de cada línea, de lo contrario, el archivo no se reconocerá y su servidor Kafka no funcionará.
3. Ejecute el git comando a continuación a clone el ata-kafka proyecto a su máquina local para que pueda modificarlo para usarlo como un archivo de unidad para su servicio Kafka.
sudo git clone https://github.com/Adam-the-Automator/apache-kafka.git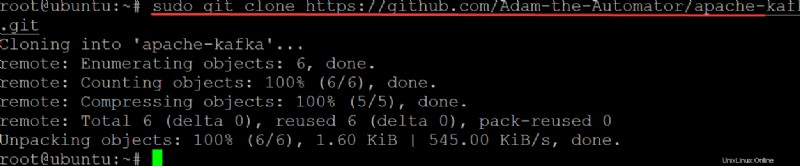
Ahora, ejecute los siguientes comandos para pasar al apache-kafka directorio y enumere los archivos dentro.
cd apache-kafka
lsAhora que estás en el ata-kafka directorio, puede ver que tiene dos archivos dentro:kafka.service y zookeeper.service, como se muestra a continuación.

5. Abra el zookeeper.servicio archivo en su editor de texto preferido. Utilizará este archivo como referencia para crear el kafka.service expediente.
Personalice cada sección a continuación en el zookeeper.service archivo, según sea necesario. Pero esta demostración usa este archivo tal cual, sin modificaciones.
- El
[Unit]sección configura las propiedades de inicio para esta unidad. Esta sección le dice a systemd qué usar al iniciar el servicio zookeeper.
- La sección [Servicio] define cómo, cuándo y dónde iniciar el servicio Kafka utilizando kafka-server-start.sh guion. Esta sección también define información básica como el nombre, la descripción y los argumentos de la línea de comandos (lo que sigue a ExecStart=).
- El
[Install]establece el nivel de ejecución para iniciar el servicio al ingresar al modo multiusuario.
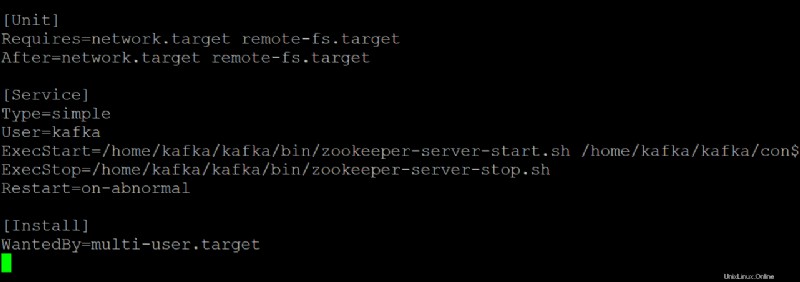
6. Abra el kafka.service archivo en su editor de texto preferido y configure cómo se ve su servidor Kafka cuando se ejecuta como un servicio systemd.
Esta demostración utiliza los valores predeterminados que se encuentran en kafka.service archivo, pero puede personalizar el archivo según sea necesario. Tenga en cuenta que este archivo hace referencia al zookeeper.service archivo, que podrías modificar en algún momento.
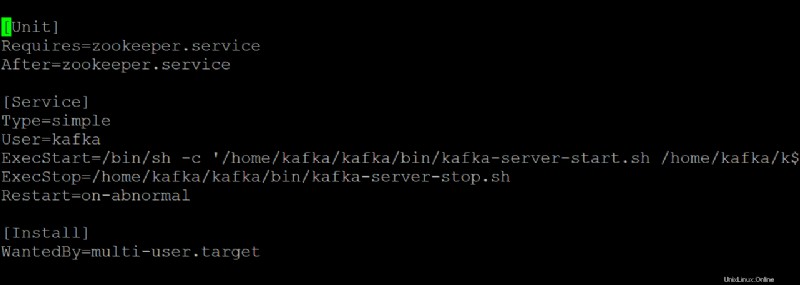
7. Ejecute el siguiente comando para start el kafka Servicio.
sudo systemctl start kafkaRecuerde detener e iniciar su servidor Kafka como un servicio. Si no lo hace, el proceso permanecerá en la memoria y solo podrá detenerlo eliminándolo. Este comportamiento puede provocar la pérdida de datos si tiene temas que se están escribiendo o actualizando a medida que se cierra el proceso.
Desde que creó kafka.service y zookeeper.servicio archivos, también puede ejecutar cualquiera de los siguientes comandos para detener o reiniciar su servidor Kafka basado en systemd.
sudo systemctl stop kafka
sudo systemctl restart kafka
8. Ahora, ejecuta el journalctl Comando a continuación para verificar que el servicio se haya iniciado correctamente.
Este comando enumera todos los registros del servicio kafka.
sudo journalctl -u kafkaSi configuró todo correctamente, verá un mensaje que dice Started kafka.service, como se muestra a continuación. ¡Felicidades! Ahora tiene un servidor Kafka completamente funcional que se ejecutará como servicios systemd.

Restricción del usuario Kafka
En este punto, el servicio de Kafka se ejecuta como el usuario de Kafka. El usuario de kafka es un usuario de nivel de sistema y no debe estar expuesto a los usuarios que se conectan a Kafka.
Cualquier cliente que se conecte a Kafka a través de este agente tendrá acceso de nivel raíz en la máquina del agente, lo cual no se recomienda. Para mitigar el riesgo, eliminará el usuario kafka del archivo sudoers y deshabilitará la contraseña para el usuario kafka.
1. Ejecute el exit Comando a continuación para volver a su cuenta de usuario normal.
exit
2. A continuación, ejecute el sudo deluser kafka sudo y presiona Entrar para confirmar que desea eliminar el kafka usuario de sudoers.
sudo deluser kafka sudo
3. Ejecute el siguiente comando para deshabilitar la contraseña para el usuario kafka. Si lo hace, mejora aún más la seguridad de su instalación de Kafka.
sudo passwd kafka -l
4. Ahora, vuelva a ejecutar el siguiente comando para eliminar al usuario kafka de la lista de sudoers.
sudo deluser kafka sudo
5. Ejecute el siguiente su comando para establecer que solo los usuarios autorizados, como los usuarios root, pueden ejecutar comandos como kafka usuario.
sudo su - kafka
6. A continuación, ejecute el siguiente comando para crear un nuevo tema de Kafka llamado ATA para verificar que su servidor Kafka se está ejecutando correctamente.
Los temas de Kafka son fuentes de mensajes hacia/desde el servidor, lo que ayuda a eliminar las complicaciones de tener datos desordenados y desorganizados en los servidores de Kafka.
cd /usr/local/kafka-server && bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic ATA
7. Ejecute el siguiente comando para crear un productor de Kafka usando el kafka-console-producer.sh guion. Los productores de Kafka escriben datos en temas.
echo "Hello World, this sample provided by ATA" | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ATA > /dev/null
8. Finalmente, ejecute el siguiente comando para crear un consumidor kafka usando el kafka-console-consumer.sh guion. Este comando consume todos los mensajes en el tema kafka (--topic ATA ) y luego imprime el valor del mensaje.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ATA --from-beginningVerá el mensaje en el resultado a continuación porque el consumidor de la consola Kafka imprime sus mensajes desde el tema ATA Kafka, como se muestra a continuación. El script del consumidor continúa ejecutándose en este punto, esperando más mensajes.
Puede abrir otra terminal para agregar más mensajes a su tema y presionar Ctrl+C para detener el script del consumidor una vez que termine la prueba.

Conclusión
A lo largo de este tutorial, ha aprendido a instalar y configurar Apache Kafka en su máquina. También se ha referido al consumo de mensajes de un tema de Kafka producido por el productor de Kafka, lo que da como resultado una gestión eficaz del registro de eventos.
Ahora, ¿por qué no aprovechar este nuevo conocimiento instalando Kafka con Flume para distribuir y administrar mejor sus mensajes? También puede explorar la API Streams de Kafka y crear aplicaciones que lean y escriban datos en Kafka. Al hacerlo, transforma los datos según sea necesario antes de escribirlos en otro sistema como HDFS, HBase o Elasticsearch.