La minería de datos es el proceso de analizar grandes cantidades de datos para obtener información útil. Tiene aplicaciones increíblemente diversas en los campos de la investigación académica y los negocios. Los investigadores utilizan la minería de datos para inferir nuevas soluciones a los problemas de investigación computacional, mientras que las corporaciones dependen de ella para ganar ventaja en los ingresos comerciales. Empresas como Amazon utilizan diferentes técnicas de minería de datos para mejorar su motor de recomendación de productos, mientras que los gigantes de búsqueda como Google y Microsoft las aprovechan para clasificar los resultados de sus motores de búsqueda de manera efectiva. Gracias a la creciente demanda de Data Science en general, en las últimas décadas se ha enviado una gran cantidad de software robusto de minería de datos para Linux. Quédese con nosotros para saber más sobre los 20 mejores software de minería de datos de Linux.
Software de minería de datos enriquecido
La minería de datos cubre muchos temas de ciencia de datos, incluida la recopilación de datos, el análisis estadístico, los conceptos de inteligencia artificial y, por supuesto, la programación. Debido a su dominio masivo, las herramientas de minería de datos vienen en diferentes sabores, desarrolladas para realizar diferentes cosas. Por lo tanto, nuestros expertos han elegido una gama versátil de software de minería de datos para Linux que, si se usa de manera creativa, puede satisfacer perfectamente los requisitos de los ingenieros de datos modernos.
1. Minero rápido
El pináculo del software moderno de minería de datos de Linux, Rapid Miner está muy por encima de los demás cuando se trata de hablar sobre plataformas confiables de minería de datos. Conocido anteriormente como YALE, es un paquete de minería de datos potente y flexible que presenta una cantidad sustancial de funciones sólidas para mejorar sus habilidades de minería al siguiente nivel. Rapid Miner está desarrollado sobre el lenguaje de programación Java y hace precisamente lo que su nombre indica:mejorar sus proyectos de minería de datos.
Características de Rapid Miner
- Rapid Miner viene con una interfaz GUI mínima pero intuitiva, con una versión de línea de comandos adicional para los geeks de terminales.
- Este entorno visual robusto y flexible para el análisis predictivo permite a los usuarios analizar grandes datos sin programación explícita.
- Hay disponible una enorme lista de extensiones flexibles que le permiten funcionalidades adicionales a las que obtiene durante la primera instalación.
- Puede integrar este poderoso software de minería de datos para Linux muy fácilmente en proyectos de minería de datos personalizados.
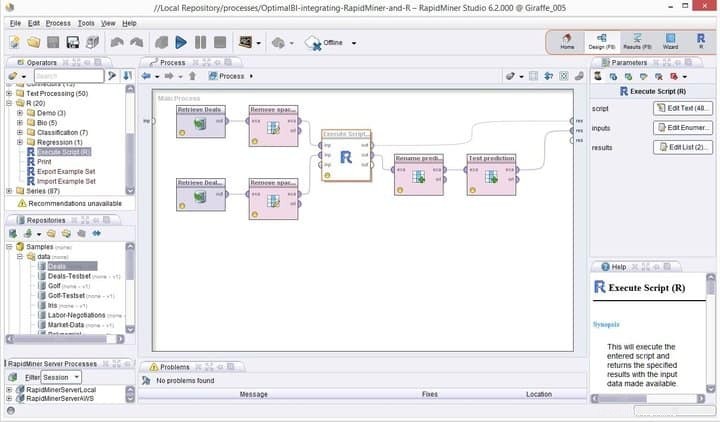
2. R
R puede ser un nombre familiar para los graduados de informática con conocimientos adecuados de programación. Pero tiene mucho más valor para un científico de datos. En pocas palabras, R es un entorno completo para el análisis estadístico de datos y gráficos. Es una plataforma de minería de datos altamente flexible que ofrece poderosas técnicas analíticas como modelado, pruebas estadísticas, análisis de series de tiempo, clasificación, agrupamiento, entre muchas otras. Si eres un profesional con habilidades de programación superiores, R podría convertirse en la mejor arma de tu arsenal.
Características de R
- R ofrece una solución robusta y eficaz para almacenar y manejar grandes cantidades de datos corporativos.
- Una gran cantidad de herramientas integradas y coherentes de análisis de datos garantizan que los ingenieros puedan aprovechar R para una amplia gama de proyectos de minería de datos.
- Es fácil depurar problemas dentro de los proyectos de minería de datos existentes debido a las sólidas capacidades de reproducción de errores de R.
- R se utiliza ampliamente para proyectos de minería de datos a gran escala y cuenta con una enorme lista de soluciones preconstruidas por entusiastas del código abierto.
3. Naranja
Si es un científico de datos con experiencia en CS, es posible que ya esté familiarizado con Orange. Para el resto de ustedes, considérenlo como un sólido software de minería de datos para Linux construido sobre Python. En general, Orange ofrece un conjunto flexible y gratificante de bibliotecas de Python capaces de manejar las técnicas modernas de extracción de datos, como clasificación, modelado, regresión, agrupamiento junto con herramientas para la visualización y el preprocesamiento de datos.
Características de Orange
- Su poderosa herramienta de programación visual llamada Orange Canvas permite a los principiantes crear soluciones rápidas de extracción de datos utilizando sus productivas capacidades de gestión de flujo de trabajo.
- Viene con un sólido conjunto de herramientas de visualización premium para árboles de decisión, subconjuntos de atributos, embolsado, impulso y mucho más.
- Según sus requisitos, Orange tiene la licencia GNU GPL, lo que permite a los programadores modificar o personalizar este software gratuito de extracción de datos.
- Puede elegir Orange ahora mismo e integrarlo con sus proyectos de minería de datos existentes para obtener capacidades adicionales, incluidos más de 100 widgets prediseñados.
4. MOA
MOA, abreviatura de Massive Online Analysis, hace exactamente lo que dice su nombre. Es un innovador software de minería de datos para Linux con un énfasis principal en la minería de grandes flujos de datos. MOA tiene como objetivo equipar a los aspirantes a científicos de datos con una plataforma de minería de datos poderosa pero flexible que les permitirá probar varios algoritmos de minería de datos de manera efectiva en flujos de datos en constante evolución. MOA viene con una sólida colección de métodos estándar de aprendizaje automático, incluidos sistemas de clasificación, regresión, agrupación, detección de valores atípicos y recomendación.
Características de MOA
- MOA ofrece tres opciones de interfaz diferentes, incluida una interfaz GUI, una basada en consola y una API flexible basada en Java para la integración en línea.
- Incluye algoritmos flexibles de detección de cambios para determinar la mayor cantidad de información posible a partir de flujos de datos en tiempo real.
- Este software de minería de datos de código abierto es adecuado para aquellos que desean aprovechar los datos en tiempo real para sus procesos de minería.
- MOA presenta una licencia GNU GPL de código abierto y, por lo tanto, no requiere formalidades legales para la personalización o modificación.
5. RAÍZ
Puede confiar en una plataforma de minería de datos desarrollada por el CERN, ¿no es así? ROOT es un software de minería de datos de Linux inmensamente poderoso para resolver desafíos del mundo real que involucran cantidades masivas de datos físicos de alta energía. Pronto ganó popularidad entre los científicos de datos que trabajan en diferentes áreas y actualmente se usa ampliamente para la extracción de datos y el análisis de datos astronómicos. Si eres un graduado de ciencias con un profundo interés en la física de partículas, esta es la verdadera plataforma para ti.
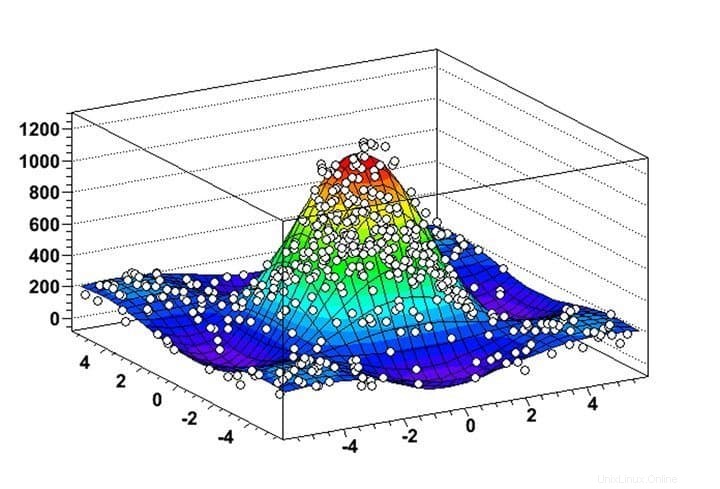
Características de ROOT
- ROOT permite una visualización inmensamente útil de distribuciones de datos y algoritmos de minería a través de sus funciones de histogramas y gráficos altamente flexibles.
- Puede analizar objetos 2D como líneas, polígonos, flechas, diagramas e histogramas junto con objetos gráficos 3D en este software de minería de datos para Linux.
- ROOT proporciona varias herramientas computacionales de cuatro vectores y capacidades de manipulación de imágenes para el análisis práctico de conjuntos de datos del mundo real.
- El software está escrito principalmente en C++ pero utiliza Python y R para maximizar sus funcionalidades de minería de datos.
6. Fusión de datos
Uno de los mejores software de minería de datos de Linux para investigadores e ingenieros por igual, DataMelt ofrece un conjunto completo de funcionalidades potentes pero flexibles para analizar grandes conjuntos de datos. Podría decirse que se encuentra entre las plataformas de minería de datos más convenientes para los principiantes que buscan impulsar sus carreras en ciencia de datos. Anteriormente conocido como SCaVis, este enigmático software de minería de datos une enormes paquetes de software de código abierto en una interfaz coherente.
Características de DataMelt
- DataMelt implementa una cantidad sustancial de sus herramientas de manipulación y trazado de datos en Java y utiliza Jython con fines de secuencias de comandos.
- Se han utilizado poderosas macros de Python para permitir que los científicos de datos visualicen datos, histogramas y estructuras 3D del mundo real.
- El entorno de desarrollo integrado (IDE) incorporado utiliza bibliotecas JAIDA FreeHEP flexibles y permite el resaltado de sintaxis, la finalización de código, el analizador de programas y un shell Jython.
- La licencia de código abierto de este software de minería de datos para Linux permite a los científicos de datos ampliar el software según lo requieran.
7. Sonajero
Rattle (la herramienta analítica de R para aprender fácilmente) es un software de minería de datos gratuito que proporciona una interfaz poderosa para las funcionalidades de clasificación binaria y minería de datos de R. También proporciona una práctica suite de inteligencia comercial conocida como RStat para corporaciones y profesionales de la ciencia de datos. Rattle permite a los usuarios importar conjuntos de datos desde archivos CSV u ODBC y explorarlos para modelar sus soluciones de minería de datos.
Características de Rattle
- Rattle permite a los científicos de datos desarrollar y analizar modelos de datos complejos y exportarlos como PMML (lenguaje de marcado de modelado predictivo) o como puntuaciones.
- Es un software completo de minería de datos de Linux que puede ser utilizado fácilmente para la minería de datos a gran escala por parte de corporaciones, gobiernos e instituciones de investigación por igual.
- Los datos se pueden cargar desde una gran cantidad de fuentes, incluidos archivos CSV, TXT, Excel, ARFF, ODBC y RData, además de Corpus y scripts.
- Las técnicas de aprendizaje automático que presenta esta plataforma de minería de datos incluyen árboles de decisión, bosques aleatorios, máquinas de vectores de soporte, regresión logística, redes neuronales y otras.
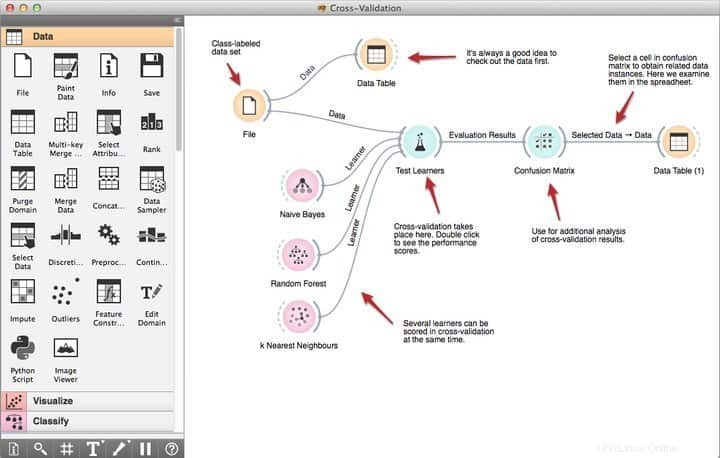
8. ELKI
ELKI es un software de minería de datos de Linux inmensamente poderoso escrito en el lenguaje de programación Java. Su objetivo es hacer que la minería de datos sea accesible para las personas que no tienen certificaciones profesionales en ciencia de datos. Es una de las plataformas de minería de datos más utilizadas en las fundaciones de investigación y enseñanza debido a su impresionante colección de funciones sólidas de minería de datos. ELKI viene con soporte integrado para casi todos los algoritmos populares de minería de datos, incluidos el agrupamiento, la clasificación, la gestión de índices de bases de datos y la detección de valores atípicos.
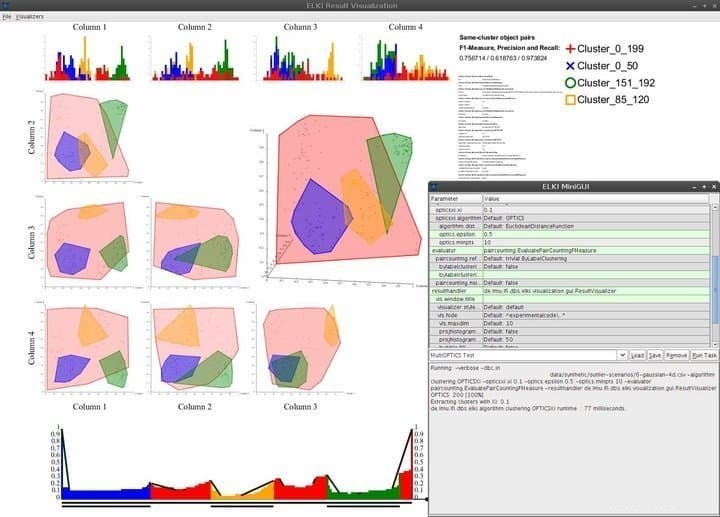
Características de ELKI
- ELKI viene con una interfaz de usuario minimalista pero elegante que brinda casi las habilidades de navegación necesarias.
- Las capacidades de visualización incluyen, entre otras, histogramas, curvas ROC, gráficos OPTICS, coordenadas paralelas, celdas de Voronoi, formas alfa y más.
- ELKI emplea varias estrategias de división de árbol R y carga masiva para estructurar índices de manera efectiva.
- Este software de minería de datos para Linux permite que los científicos de datos exploren y evalúen datos geográficos mediante sólidas funciones de detección de valores atípicos espaciales.
9. CUCHILLO
Podría decirse que KNIME es uno de los software de minería de datos de código abierto más innovadores que pudimos probar. Proporciona una plataforma de minería de datos muy completa y flexible, que cuenta con características coherentes para tareas de integración, procesamiento, análisis, informes y evaluación de datos. KNIME permite la creación de flujos de trabajo visuales llamados canalizaciones para permitir que los científicos de datos investiguen conjuntos de datos complejos en tiempo real. El software en sí es altamente escalable y puede integrarse en proyectos futuros sin ningún obstáculo.
Características de KNIME
- La interfaz GUI de este software gratuito de extracción de datos es muy intuitiva y abarca las capacidades de navegación específicas requeridas en la extracción de datos moderna.
- KNIME se asienta sobre el entorno de desarrollo interactivo de Eclipse y aprovecha sus sólidas API para otorgar extensibilidad a los entusiastas del código abierto.
- Se incluye una práctica interfaz de usuario basada en consola para permitir ejecuciones por lotes a través de scripts automatizados.
- KNIME es compatible con una amplia gama de técnicas de minería de datos, incluidas la agrupación, la inducción de reglas, las reglas de asociación, las redes bayesianas, las redes neuronales y muchas más.
10. Weka
Weka, abreviatura de Waikato Environment for Knowledge Analysis, es un atractivo software de minería de datos para Linux. Ofrece un amplio conjunto de software de aprendizaje automático escrito en Java, incluidos algoritmos para técnicas de minería de datos convencionales, como árboles de decisión, máquinas de vectores de soporte, clasificadores basados en instancias, agrupamiento, redes de Bayes, redes neuronales y muchos más. Weka viene con capacidades de integración bidireccional con MOA y, por lo tanto, se puede usar mucho en áreas donde el procesamiento de flujos de datos en tiempo real es obligatorio.
Características de Weka
- Las potentes capacidades de procesamiento y visualización de datos de Weka hacen que la evaluación de conjuntos de datos a gran escala sea mucho más sencilla que la mayoría de los programas de minería de datos gratuitos.
- La interfaz gráfica de usuario (GUI) integrada es muy intuitiva y hace que la aplicación de los algoritmos de aprendizaje automático sea relativamente cómoda.
- La API flexible hace que la integración de Weka en proyectos de minería de datos existentes o futuros sea completamente sencilla.
- Weka’s robust environment allows rewarding data preprocessing abilities to make the most out of industrial or research data.
11. KEEL
KEEL stands for Knowledge Extraction based on Evolutionary Learning, and as the name implies, it is a Linux data mining software for assessing evolutionary algorithms. It is a powerful data mining platform that provides advanced functionalities to help engineers bring new data mining solutions while providing researchers with a mesmerizing platform for scientific undertakings. KEEL is written using the powerful interpreted programming language Java and ships with an open-source GNU GPL license.
Features of KEEL
- The user interface of KEEL is simple in visual, yet it provides all the navigational power required to manage the software effectively.
- It comes with a pre-built set of extensive evolutionary algorithms to predict models, preprocessing methods, and postprocessing procedures.
- KEEL offers over 100 different algorithms for data transformation, discretization, feature selection, noise filtering, and many more.
- It’s among those few data mining software for Linux that comes with extremely accurate data reduction methodologies, alongside functions for extracting rules based on patterns.
12. Apache Mahout
Apache Mahout is one of the most used data mining platforms by professional data scientists due to its substantial empowering features. It is primarily an open source collection of frequently used machine learning techniques and their implementations to help cluster, classify, and frequent pattern recognition in large-scale datasets. Many notable tech giants leverage Apache Mahout for real-time data mining, including Adobe, AOL, Drupal, and Twitter, due to the flexibility it offers.
Features of Apache Mahout
- This data mining software for Linux integrates to the Apache Hadoop stack very well, thus offering an excellent platform for people looking for distributed data mining solutions.
- Data scientists can leverage Mahout on top of Apache Spark as the back-end for implementing flexible and highly scalable data mining projects.
- Mahout comes with native support for CPU/GPU/CUDA acceleration, thus allowing you to leverage the maximum processing power you could get.
13. Sisense
Sisense is arguably among the best data mining software for Linux beginners. It provides data scientists with the specific features they require for diving into massive datasets and discover crucial insights like customer’s shopping habits, search rankings, and other business analytics. Sisense offers a compelling dashboard, making it reasonably straightforward to explore and visualize large amounts of unprocessed data. If you’re coming into data mining from a non-technical background, Sisense might be the best data mining platform for you.
Features of Sisense
- Sisense allows data science professionals to connect with any number of data sources – both structured and unstructured.
- The user interface is very intuitive, and the dashboard provides a highly interactive workflow for visualizing large-scale disparate data sources.
- Sisense can be readily employed in enterprises, government institutions, healthcare management, supply chains, manufacturing, and other types of corporations.
- Sisense allows for a handy drag-and-drop feature empowering data scientists in managing their projects with superior productivity.
14. Databionic
The Databionic ESOM tools offer a plethora of rewarding and flexible data mining techniques such as clustering, visualization, and classification with Emergent Self-Organizing Maps (ESOM) that enable data scientists to analyze large-scale data for business analytics. Developed in Germany, Databionic provides almost every necessary functionalities you’d look for in a modern-day Linux data mining software. It comes under a free and open source GNU GPL license and encourages professionals to tweak the software as they see fit.
Features of Databionic
- This data mining software for Linux is written using the Java programming language and offers maximum portability and extensibility.
- A compelling set of pre-built initialization methods and training algorithms are shipped with Databionic to ease your data mining projects.
- Databionic enables you to effectively visualize high-dimensional and disparate datasets with U-Matrix, P-Matrix, Component Planes, and SDH.
- Users can quickly build personalized ESOM classifiers for automating their data mining tasks with Databionic.
15. Anaconda
Anaconda is an extremely innovative, powerful, and open source data mining software powered by Python, the holy grail of data science programming languages. Industry leaders, including CISCO, Bloomberg, and BMW, utilize this awe-inspiring data mining platform to stay on top of their fellow competitors and curate new analytics solutions. Anaconda is often a mandatory requirement for companies hiring data scientists due to its extensive usage in the field.
Features of Anaconda
- Anaconda allows data scientists to harness the might of data science, machine learning, and AI – all from a single platform and deploy projects with a single click of the mouse.
- This free data mining software comes with an extensive set of pre-built data science packages for Python, R, and Scala.
- Anaconda ships with a BSD license, allowing developers to leverage it to build robust data mining solutions without any legal hassle.
- It is relatively simple to integrate this modern-day data mining software for Linux with other data science software in your arsenal.
16. Shogun
Shogun is, as the developers call it – a unified and efficient machine learning library aimed at solving real-world problems involving big data, and of course – data mining. It is one of the best data mining software for Linux that provides top-notch functionalities and makes sure they can be leveraged as the users want them to. If you’re looking for robust open source data mining software, Shogun might be the perfect tool for you.
Features of Shogun
- Shogun features an extensive range of data mining features, including but not limited to classification, regression, dimensionality reduction, support vector machines, and such.
- It offers a full-fledged implementation of powerful hidden Markov models for enhancing your data mining capabilities right out of the box.
- The user interface is fully hackable and can integrate with futuristic projects too well, thanks to its robust APIs.
- Shogun performs relatively much better than regular Linux data mining software, owing to its gratitude to C++.
17. GNU Octave
GNU Octave is an extremely powerful yet user-friendly scientific computing solution that features a robust high-level programming language similar to MATLAB in many ways. It has widespread usage in the areas of numerical computing and syncs perfectly with most MATLAB implementations. Data scientists can leverage this mesmerizing data science platform for analyzing diverse ranges of real-time data and dig out potentially rewarding insights from them.
Features of GNU Octave
- GNU Octave aims primarily at solving linear and nonlinear numerical problems and runs seamlessly on Linux, macOS, BSD, and Windows.
- The syntax of its high-level programming language is very identical to MATLAB and can operate on both vectors and matrices.
- The powerful mathematics-oriented data visualization capabilities of this Linux data mining software helps in analyzing large amounts of data without requiring external tools.
- The software comes with a GUI interface and a command-line variant for enhancing productivity to the highest level.
18. Apache UIMA
Apache UIMA is highly modular informatics management and analysis system that has gained immense popularity among data scientists due to its compelling data mining functionalities. UIMA stands for Unstructured Information Management Architecture and, as the name already suggests, is an analytic tool for exploring unstructured data. This data mining software for Linux provides a select set of flexible features to discover useful insights from large volumes of disparate data.
Features of Apache UIMA
- It is a Java-based data mining framework for analyzing and evaluating massive datasets involving real-time unstructured data.
- UIMA is hugely scalable and can be used as network services and processing pipelines.
- This Linux data mining software facilitates the analysis of multimedia contents such as audio and video data.
- The software suite comes under an Apache license and is thus free to use and modify by users.
19. Turi Create
Turi is arguably among the most excellent data mining software for Linux we’ve tested during our compilation of this guide. Known previously as Graphlab Create, Turi offers a plethora of robust data science functionalities to build highly modular, scalable data mining solutions. Turi boasts a wide range of diverse, high-performance, distributed computation features and can greatly simplify the development of custom data-mining programs.
Features of Turi Create
- This Linux data mining software is based on graphs and focuses more on tasks than algorithms.
- Although the software doesn’t require any external graphic processing unit (GPU), using one can significantly boost performance.
- Apart from standard text and image data, Turi has built-in support for audio, video, and sensor data.
- It is written using the C++ programming language and is one of the fastest data mining software we’ve tested.
20. ROSETTA
Marketed by the devs as a rough set toolkit for analysis of data, ROSETTA is a general-purpose tool for discernibility-based modeling, with very compelling use cases in the field of data mining. It is a powerful framework for analyzing tabular data and offers some very robust knowledge discovery functionalities. You can utilize ROSETTA in preprocessing large-scale datasets, computing attribute sets, generating rules, and many more.
Features of ROSETTA
- This data mining software for Linux comes with an incredibly intuitive GUI interface with very productive navigational abilities in place.
- Users can integrate this data mining platform with database management systems (DBMSs) via ODBC relatively easily.
- ROSETTA comes with in-built support for both unsupervised and supervised machine learning models.
- The robust set of advanced filtering methods make postprocessing reasonably simple.
Pensamientos finales
Due to its diverse application in real life, data mining software for Linux tends to vary in flavor and functionality. Some of the most popular data mining tools include Rapid Miner, R, Orange, ELKI, MOA, Weka, ROOT, and DataMelt. So, when selecting the right Linux data mining software, you’ve to choose programs that meet your requirements. Hopefully, we could provide you the essential insights on some of the most widely used data mining tools. You should now be able to select the one that does the job for you perfectly. Thanks for your patience, and don’t forget to check us out for regular posts on exciting Linux software and tutorials.