Para organizar datos como lista enlazada usando struct list_head tienes que declarar raíz de la lista y declarar entrada de lista para vinculación. Tanto las entradas raíz como las secundarias son del mismo tipo (struct list_head ). children entrada de struct task_struct la entrada es un root . sibling entrada de struct task_struct es un list entry . Para ver las diferencias, debe leer el código, donde children y sibling son usados. Uso de list_for_each para children significa qué children es un root . Uso de list_entry para sibling significa qué sibling es un list entry .
Puede leer más sobre las listas de núcleos de Linux aquí.
Pregunta :¿Cuál es la razón por la que estamos pasando "hermano" aquí, que eventualmente es una lista diferente con un desplazamiento diferente?
Respuesta:
Si la lista se creó de esta manera:
list_add(&subtask->sibling, ¤t->children);
Que
list_for_each(list, ¤t->children)
Inicializará los punteros de lista a sibling , entonces tienes que usar subling como parámetro para list_entry. Así es cómo kernel de linux enumera la API diseñada.
Pero, si la lista fue creada en otro (incorrecto ) manera:
list_add(&subtask->children, ¤t->sibling);
Entonces tienes que iterar la lista este (incorrecto ) manera:
list_for_each(list, ¤t->sibling)
Y ahora tienes que usar children como parámetro para list_entry .
Espero que esto ayude.
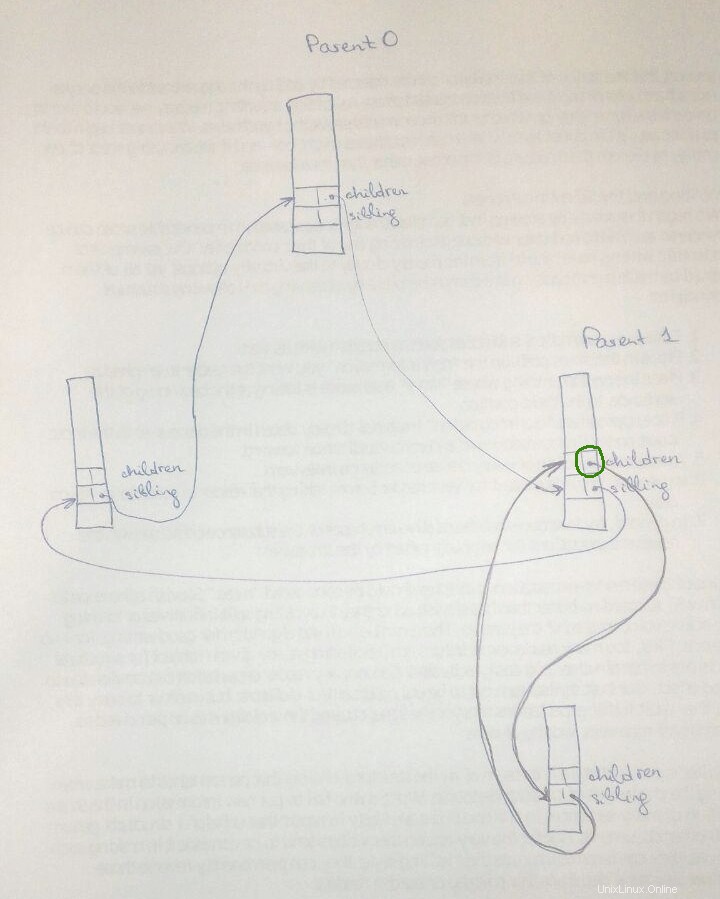
La siguiente es la representación pictórica que podría ayudar a alguien en el futuro. El cuadro superior representa a un padre y los dos cuadros inferiores son sus hijos

Aquí hay una imagen además de las respuestas anteriores. El mismo proceso puede ser tanto un padre como un hijo (como Padre1 en la imagen), y debemos distinguir entre estos dos roles.
Intuitivamente, si children de Parent0 apuntaría a children de Parent1, luego Parent0.children.next->next (círculo verde en la imagen), que es lo mismo que Parent1.children.next , apuntaría a un elemento secundario de Parent1 en lugar de al siguiente elemento secundario de Parent0.