Yo mismo escribí un perl one-liner, que hace precisamente eso, y también imprime el carácter original. (Espera el archivo de STDIN)
perl -C7 -ne 'for(split(//)){print sprintf("U+%04X", ord)." ".$_."\n"}'
Sin embargo, debería haber una mejor manera que esta.
Necesitaba el punto de código para algunos emoticonos comunes y se me ocurrió esto:
echo -n "" | # -n ignore trailing newline \
iconv -f utf8 -t utf32be | # UTF-32 big-endian happens to be the code point \
xxd -p | # -p just give me the plain hex \
sed -r 's/^0+/0x/' | # remove leading 0's, replace with 0x \
xargs printf 'U+%04X\n' # pretty print the code point
que imprime
U+1F60A
que es el punto de código para "CARA SONRIENTE CON OJOS SONRIENTES".
Inspirada en la respuesta de Neftas, aquí hay una solución un poco más simple que funciona con cadenas, en lugar de un solo carácter:
iconv -f utf8 -t utf32le | hexdump -v -e '8/4 "0x%04x " "\n"' | sed -re"s/0x / /g"
# ^
# The number `8` above determines the number of columns in the output. Modify as needed.
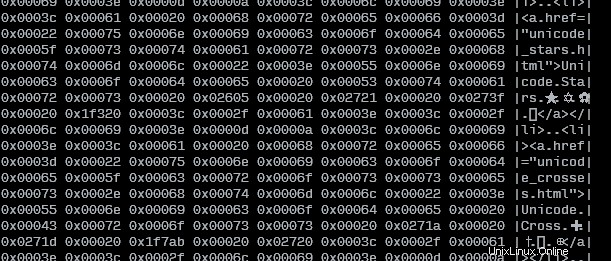
También hice un script Bash que lee desde stdin, o desde un archivo, y que muestra el texto original junto con los valores Unicode:
COLWIDTH=8
SHOWTEXT=true
tmpfile=$(mktemp)
cp "${1:-/dev/stdin}" "$tmpfile"
left=$(set -o pipefail; iconv -f utf8 -t utf32le "$tmpfile" | hexdump -v -e $COLWIDTH'/4 "0x%05x " "\n"' | sed -re"s/0x / /g")
if [ $? -gt 0 ]; then
echo "ERROR: Could not convert input" >&2
elif $SHOWTEXT; then
right=$(tr [:space:] . < "$tmpfile" | sed -re "s/.{$COLWIDTH}/|&|\n/g" | sed -re "s/^.{1,$((COLWIDTH+1))}\$/|&|/g")
pr -mts" " <(echo "$left") <(echo "$right")
else
echo "$left"
fi
rm "$tmpfile"