Tu pregunta me intrigó y me dejé llevar. Esta solución generará un buen archivo PDF con un índice en el que se puede hacer clic y un código resaltado en color. Encontrará todos los archivos en el directorio y subdirectorios actuales y creará una sección en el archivo PDF para cada uno de ellos (consulte las notas a continuación para saber cómo hacer que su comando de búsqueda sea más específico).
Requiere que tenga instalado lo siguiente (las instrucciones de instalación son para sistemas basados en Debian, pero deberían estar disponibles en los repositorios de su distribución):
-
pdflatex,colorylistingssudo apt-get install texlive-latex-extra latex-xcolor texlive-latex-recommendedEsto también debería instalar un sistema LaTeX básico si no tiene uno instalado.
Una vez que estén instalados, use este script para crear un documento LaTeX con su código fuente. El truco está en usar el listings (parte de texlive-latex-recommended ) y color (instalado por latex-xcolor ) Paquetes LaTeX. El \usepackage[..]{hyperref} es lo que hace que se pueda hacer clic en los listados de la tabla de contenido.
#!/usr/bin/env bash
tex_file=$(mktemp) ## Random temp file name
cat<<EOF >$tex_file ## Print the tex file header
\documentclass{article}
\usepackage{listings}
\usepackage[usenames,dvipsnames]{color} %% Allow color names
\lstdefinestyle{customasm}{
belowcaptionskip=1\baselineskip,
xleftmargin=\parindent,
language=C++, %% Change this to whatever you write in
breaklines=true, %% Wrap long lines
basicstyle=\footnotesize\ttfamily,
commentstyle=\itshape\color{Gray},
stringstyle=\color{Black},
keywordstyle=\bfseries\color{OliveGreen},
identifierstyle=\color{blue},
xleftmargin=-8em,
}
\usepackage[colorlinks=true,linkcolor=blue]{hyperref}
\begin{document}
\tableofcontents
EOF
find . -type f ! -regex ".*/\..*" ! -name ".*" ! -name "*~" ! -name 'src2pdf'|
sed 's/^\..//' | ## Change ./foo/bar.src to foo/bar.src
while read i; do ## Loop through each file
name=${i//_/\\_} ## escape underscores
echo "\newpage" >> $tex_file ## start each section on a new page
echo "\section{$i}" >> $tex_file ## Create a section for each filename
## This command will include the file in the PDF
echo "\lstinputlisting[style=customasm]{$i}" >>$tex_file
done &&
echo "\end{document}" >> $tex_file &&
pdflatex $tex_file -output-directory . &&
pdflatex $tex_file -output-directory . ## This needs to be run twice
## for the TOC to be generated
Ejecute el script en el directorio que contiene los archivos fuente
bash src2pdf
Eso creará un archivo llamado all.pdf en el directorio actual. Intenté esto con un par de archivos de origen aleatorios que encontré en mi sistema (específicamente, dos archivos del origen de vlc-2.0.0 ) y esta es una captura de pantalla de las dos primeras páginas del PDF resultante:
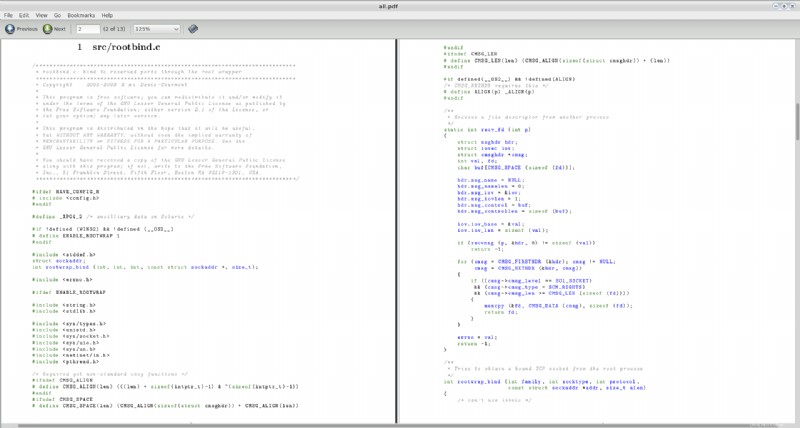
Un par de comentarios:
- La secuencia de comandos no funcionará si los nombres de los archivos de código fuente contienen espacios. Dado que estamos hablando del código fuente, asumiré que no.
- Agregué
! -name "*~"para evitar archivos de copia de seguridad. -
Te recomiendo que uses un
findmás específico comando para encontrar sus archivos, de lo contrario, cualquier archivo aleatorio se incluirá en el PDF. Si todos sus archivos tienen extensiones específicas (.cy.hpor ejemplo), debe reemplazar elfinden el script con algo como estofind . -name "*\.c" -o -name "\.h" | sed 's/^\..//' | - Juega con el
listingsopciones, puede modificar esto para que sea exactamente como lo desea.
(de StackOverflow)
for i in *.src; do echo "$i"; echo "---"; cat "$i"; echo ; done > result.txt
Esto resultará en un resultado.txt que contiene:
- Nombre de archivo
- separador (---)
- Contenido del archivo .src
- Repita desde arriba hasta que todos los archivos *.src estén listos
Si su código fuente tiene una extensión diferente, simplemente cámbielo según sea necesario. También puede editar el bit de eco para agregar la información necesaria (tal vez repetir "nombre de archivo $1" o cambiar el separador, o agregar un separador de fin de archivo).
el enlace tiene otros métodos, así que use el método que más le guste. Creo que este es el más flexible, aunque viene con una ligera curva de aprendizaje.
El código se ejecutará perfectamente desde un terminal bash (recién probado en VirtualBox Ubuntu)
Si no le importa el nombre del archivo y solo le importa el contenido de los archivos combinados:
cat *.src > result.txt
funcionará perfectamente bien.
Otro método sugerido fue:
grep "" *.src > result.txt
Lo cual prefijará cada línea con el nombre del archivo, lo que puede ser bueno para algunas personas, personalmente creo que es demasiada información, por lo que mi primera sugerencia es el bucle for anterior.
Gracias a los del foro de StackOverflow.
EDITAR:Me acabo de dar cuenta de que está buscando específicamente HTML o PDF como resultado final, algunas soluciones que he visto son imprimir el archivo de texto en PostScript y luego convertirlo en PDF. Algunos códigos que he visto:
groff -Tps result.txt > res.ps
entonces
ps2pdf res.ps res.pdf
(Requiere que tengas script fantasma)
Espero que esto ayude.
Sé que llego demasiado tarde, pero alguien que busque una solución podría encontrar esto útil.
Basado en la respuesta de @terdon, he creado un script BASH que hace el trabajo:https://github.com/eljuanchosf/source-code-to-pdf