En realidad, es bastante simple, al menos si no necesita los detalles de implementación.
En primer lugar, en Linux todos los sistemas de archivos (ext2, ext3, btrfs, reiserfs, tmpfs, zfs, ...) están implementados en el kernel. Algunos pueden descargar el trabajo al código de la zona de usuario a través de FUSE, y algunos vienen solo en forma de un módulo de kernel (el ZFS nativo es un ejemplo notable de este último debido a las restricciones de licencia), pero de cualquier manera sigue siendo un componente del kernel. Este es un básico importante.
Cuando un programa quiere leer de un archivo, emitirá varias llamadas a la biblioteca del sistema que finalmente terminarán en el núcleo en forma de open() , read() , close() secuencia (posiblemente con seek() arrojado en buena medida). El núcleo toma la ruta y el nombre de archivo proporcionados y, a través del sistema de archivos y la capa de E/S del dispositivo, los traduce a solicitudes de lectura físicas (y en muchos casos también solicitudes de escritura; piense, por ejemplo, en actualizaciones temporales) a algún almacenamiento subyacente.
Sin embargo, no tiene que traducir esas solicitudes específicamente a físico, persistente almacenamiento . El contrato del núcleo es que emitir ese conjunto particular de llamadas al sistema proporcionará el contenido del archivo en cuestión . Dónde exactamente en nuestro reino físico existe el "archivo" es secundario a esto.
El /proc suele montarse lo que se conoce como procfs . Ese es un tipo de sistema de archivos especial, pero dado que es un sistema de archivos, realmente no es diferente de, p. un ext3 sistema de archivos montado en alguna parte. Entonces, la solicitud pasa al código del controlador del sistema de archivos procfs, que conoce todos estos archivos y directorios y devuelve información específica de las estructuras de datos del kernel .
La "capa de almacenamiento" en este caso son las estructuras de datos del núcleo y procfs proporciona una interfaz limpia y conveniente para acceder a ellos. Tenga en cuenta que montar procfs en /proc es simplemente convención; podría montarlo fácilmente en otro lugar. De hecho, eso se hace a veces, por ejemplo, en chroot jails cuando el proceso que se ejecuta allí necesita acceso a /proc por algún motivo.
Funciona de la misma manera si escribe un valor en algún archivo; a nivel del núcleo, eso se traduce en una serie de open() , seek() , write() , close() llamadas que nuevamente pasan al controlador del sistema de archivos; de nuevo, en este caso particular, el código procfs.
La razón particular por la que ves file devolviendo empty es que muchos de los archivos expuestos por procfs están expuestos con un tamaño de 0 bytes. El tamaño de 0 bytes es probablemente una optimización en el lado del kernel (muchos de los archivos en /proc son dinámicos y pueden variar fácilmente en longitud, posiblemente incluso de una lectura a la siguiente, y calcular la longitud de cada archivo en cada directorio leído sería potencialmente muy caro). Siguiendo los comentarios de esta respuesta, que puede verificar en su propio sistema ejecutando strace o una herramienta similar, file primero emite un stat() llame para detectar cualquier archivo especial, y luego aprovecha la oportunidad para, si el tamaño del archivo se informa como 0, abortar e informar que el archivo está vacío.
Este comportamiento está realmente documentado y se puede anular especificando -s o --special-files en el file invocación, aunque como se indica en la página del manual que puede tener efectos secundarios. La siguiente cita es de la página del manual del archivo BSD 5.11, fechada el 17 de octubre de 2011.
Normalmente, el archivo solo intenta leer y determinar el tipo de archivos de argumentos que los informes de stat(2) son archivos ordinarios. Esto evita problemas, porque la lectura de archivos especiales puede tener consecuencias peculiares. Especificando el -s La opción hace que file también lea archivos de argumentos que son archivos especiales de bloques o caracteres. Esto es útil para determinar los tipos de sistemas de archivos de los datos en particiones de disco sin procesar, que son archivos especiales de bloque. Esta opción también hace que el archivo ignore el tamaño del archivo según lo informado por stat(2) ya que en algunos sistemas informa un tamaño cero para las particiones de disco sin formato.
En este directorio, puede controlar cómo el kernel ve los dispositivos, ajustar la configuración del kernel, agregar dispositivos al kernel y eliminarlos nuevamente. En este directorio puede ver directamente el uso de la memoria y las estadísticas de E/S.
Puede ver qué discos están montados y qué sistemas de archivos se utilizan. En resumen, todos los aspectos de su sistema Linux se pueden examinar desde este directorio, si sabe qué buscar.
El /proc directorio no es un directorio normal. Si iniciara desde un CD de inicio y buscara ese directorio en su disco duro, lo vería vacío. Cuando lo miras bajo tu sistema de funcionamiento normal, puede ser bastante grande. Sin embargo, no parece estar usando espacio en el disco duro. Esto se debe a que es un sistema de archivos virtual.
Desde el /proc file system es un sistema de archivos virtual y reside en la memoria, un nuevo /proc El sistema de archivos se crea cada vez que su máquina Linux se reinicia.
En otras palabras, es solo un medio para echar un vistazo y hurgar fácilmente en las entrañas del sistema Linux a través de una interfaz de tipo archivo y directorio. Cuando miras un archivo en el /proc directorio, está mirando directamente un rango de memoria en el kernel de Linux y viendo lo que puede ver.
Las capas en el sistema de archivos
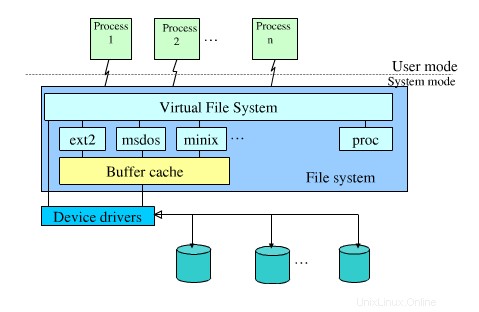
Ejemplos:
- Dentro de
/proc, hay un directorio para cada proceso en ejecución, nombrado con su ID de proceso. Estos directorios contienen archivos que tienen información útil sobre los procesos, como:exe:que es un enlace simbólico al archivo en el disco desde el que se inició el proceso.cwd:que es un enlace simbólico al directorio de trabajo del proceso.wchan:que, cuando se lee, devuelve el canal de espera en el que se encuentra el proceso.maps:que, cuando se lee, devuelve los mapas de memoria del proceso.
/proc/uptimedevuelve el tiempo de actividad como dos valores decimales en segundos, separados por un espacio:- la cantidad de tiempo desde que se inició el núcleo.
- la cantidad de tiempo que el núcleo ha estado inactivo.
/proc/interrupts:para obtener información relacionada con las interrupciones./proc/modules:para obtener una lista de módulos.
Para obtener información más detallada, consulte man proc o kernel.org.
Tienes razón, no son archivos reales.
En términos más simples, es una forma de comunicarse con el kernel utilizando los métodos normales de lectura y escritura de archivos, en lugar de llamar directamente al kernel. Está en línea con la filosofía de "todo es un archivo" de Unix.
Los archivos en /proc no existen físicamente en ninguna parte, pero el kernel reacciona a los archivos que lee y escribe allí, y en lugar de escribir en el almacenamiento, informa información o hace algo.
Del mismo modo, los archivos en /dev no son realmente archivos en el sentido tradicional (aunque en algunos sistemas los archivos en /dev pueden existir en el disco, no tendrán mucho más que el dispositivo al que se refieren) - le permiten hablar con un dispositivo usando la API de E/S de archivo Unix normal - o cualquier cosa que lo use, como shells