
En este tutorial, le mostraremos cómo instalar Apache Spark en Debian 10. Para aquellos de ustedes que no lo sabían, Apache Spark es un sistema informático de clúster rápido y de propósito general. Proporciona API de alto nivel en Java, Scala y Python, y también un motor optimizado que admite gráficos de ejecución generales. También admite un amplio conjunto de herramientas de alto nivel que incluyen Spark SQL para SQL y procesamiento de información estructurada, MLlib para aprendizaje automático. , GraphX para el procesamiento de gráficos y Spark Streaming.
Este artículo asume que tiene al menos conocimientos básicos de Linux, sabe cómo usar el shell y, lo que es más importante, aloja su sitio en su propio VPS. La instalación es bastante simple y asume que se están ejecutando en la cuenta raíz, si no, es posible que deba agregar 'sudo ' a los comandos para obtener privilegios de root. Le mostraré paso a paso la instalación de Apache Spark en Debian 10 (Buster).
Requisitos previos
- Un servidor que ejecuta uno de los siguientes sistemas operativos:Debian 10 (Buster).
- Se recomienda que utilice una instalación de sistema operativo nueva para evitar posibles problemas.
- Un
non-root sudo usero acceder alroot user. Recomendamos actuar como unnon-root sudo user, sin embargo, puede dañar su sistema si no tiene cuidado al actuar como root.
Instalar Apache Spark en Debian 10 Buster
Paso 1. Antes de ejecutar el tutorial a continuación, es importante asegurarse de que su sistema esté actualizado ejecutando el siguiente apt comandos en la terminal:
sudo apt update
Paso 2. Instalación de Java.
Apache Spark requiere Java para ejecutarse, asegurémonos de tener Java instalado en nuestro sistema Debian:
sudo apt install default-jdk
Verifique la versión de Java usando el comando:
java -version
Paso 3. Instalación de Scala.
Ahora instalamos el paquete Scala en los sistemas Debian:
sudo apt install scala
Verifique la versión de Scala:
scala -version
Paso 4. Instalación de Apache Spark en Debian.
Ahora podemos descargar el binario de Apache Spark:
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
A continuación, extraiga el tarball de Spark:
tar xvf spark-3.1.1-bin-hadoop2.7.tgz sudo mv spark-3.1.1-bin-hadoop2.7/ /opt/spark
Una vez hecho esto, configure el entorno de Spark:
nano ~/.bashrc
Al final del archivo, agregue las siguientes líneas:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Guarde los cambios y cierre el editor. Para aplicar los cambios, ejecute:
source ~/.bashrc
Ahora inicie Apache Spark con estos comandos, uno de los cuales es el maestro del clúster:
start-master.sh
Para ver la interfaz de usuario de Spark Web como se muestra a continuación, abra un navegador web e ingrese la dirección IP del host local en el puerto 8080:
http://127.0.0.1:8080/
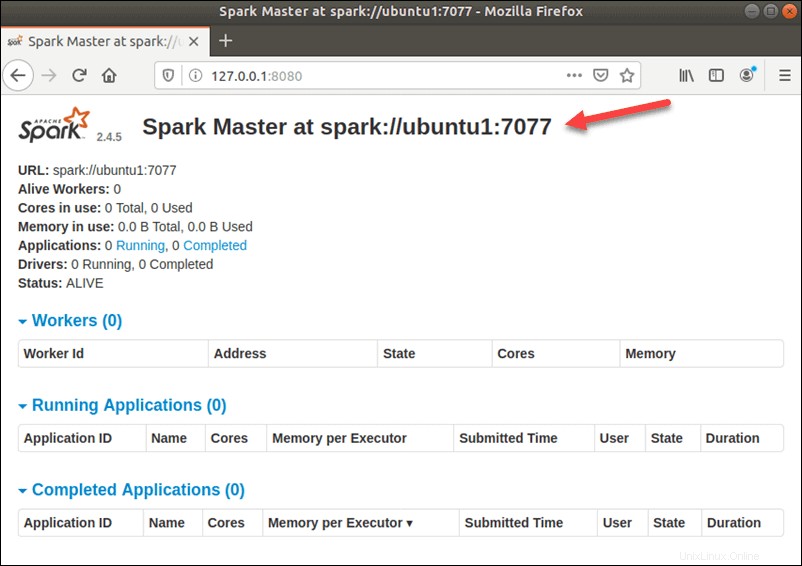
En esta configuración independiente de un solo servidor, iniciaremos un servidor esclavo junto con el servidor maestro. El start-slave.sh se usa un comando para iniciar el proceso Spark Worker:
start-slave.sh spark://ubuntu1:7077
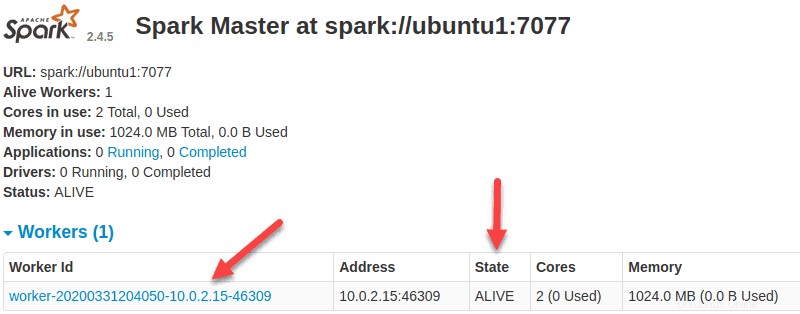
Ahora que un trabajador está en funcionamiento, si vuelve a cargar la interfaz de usuario web de Spark Master, debería verlo en la lista:
Una vez finalizada la configuración, inicie el servidor maestro y esclavo, pruebe si Spark Shell funciona:
spark-shell
¡Felicitaciones! Ha instalado Spark con éxito. Gracias por usar este tutorial para instalar la última versión de Apache Spark en el sistema Debian. Para obtener ayuda adicional o información útil, le recomendamos que consulte el Apache oficial Sitio web de Spark.