
En este tutorial, le mostraremos cómo instalar Apache Spark en Debian 11. Para aquellos de ustedes que no lo sabían, Apache Spark es una aplicación gratuita, de código abierto y de propósito general. marco para la computación en clúster. Está especialmente diseñado para la velocidad y se utiliza en el aprendizaje automático para transmitir el procesamiento a consultas SQL complejas. Es compatible con varias API para la transmisión, el procesamiento de gráficos, incluidos Java, Python, Scala y R. Spark se instala principalmente en clústeres de Hadoop, pero también puede instalar y configurar Spark en modo independiente.
Este artículo asume que tiene al menos conocimientos básicos de Linux, sabe cómo usar el shell y, lo que es más importante, aloja su sitio en su propio VPS. La instalación es bastante simple y asume que se están ejecutando en la cuenta raíz, si no, es posible que deba agregar 'sudo ' a los comandos para obtener privilegios de root. Le mostraré la instalación paso a paso de Apache Spark en Debian 11 (Bullseye).
Requisitos previos
- Un servidor que ejecuta uno de los siguientes sistemas operativos:Debian 11 (Bullseye).
- Se recomienda que utilice una instalación de sistema operativo nueva para evitar posibles problemas.
- Un
non-root sudo usero acceder alroot user. Recomendamos actuar como unnon-root sudo user, sin embargo, puede dañar su sistema si no tiene cuidado al actuar como root.
Instalar Apache Spark en Debian 11 Bullseye
Paso 1. Antes de instalar cualquier software, es importante asegurarse de que su sistema esté actualizado ejecutando el siguiente apt comandos en la terminal:
sudo apt update sudo apt upgrade
Paso 2. Instalación de Java.
Ejecute el siguiente comando a continuación para instalar Java y otras dependencias:
sudo apt install default-jdk scala git
Verifique la instalación de Java usando el comando:
java --version
Paso 3. Instalación de Apache Spark en Debian 11.
Ahora descargamos la última versión de Apache Spark desde la página oficial usando wget comando:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Luego, extraiga el archivo descargado:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Después de eso, edite el ~/.bashrc y agregue la variable de ruta de Spark:
nano ~/.bashrc
Agregue la siguiente línea:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Guarde y cierre el archivo, luego active la variable de entorno Spark usando el siguiente comando a continuación:
source ~/.bashrc
Paso 3. Inicie el servidor maestro Apache Spark.
En este punto, Apache Spark está instalado. Ahora, iniciemos su servidor maestro independiente ejecutando su script:
start-master.sh
De forma predeterminada, Apache Spark escucha en el puerto 8080. Puede verificarlo con el siguiente comando:
ss -tunelp | grep 8080
Paso 4. Acceso a la interfaz web de Apache Spark.
Una vez configurado correctamente, ahora acceda a la interfaz web de Apache Spark usando la URL http://your-server-ip-address:8080 . Debería ver el servicio maestro y esclavo de Apache Spark en la siguiente pantalla:
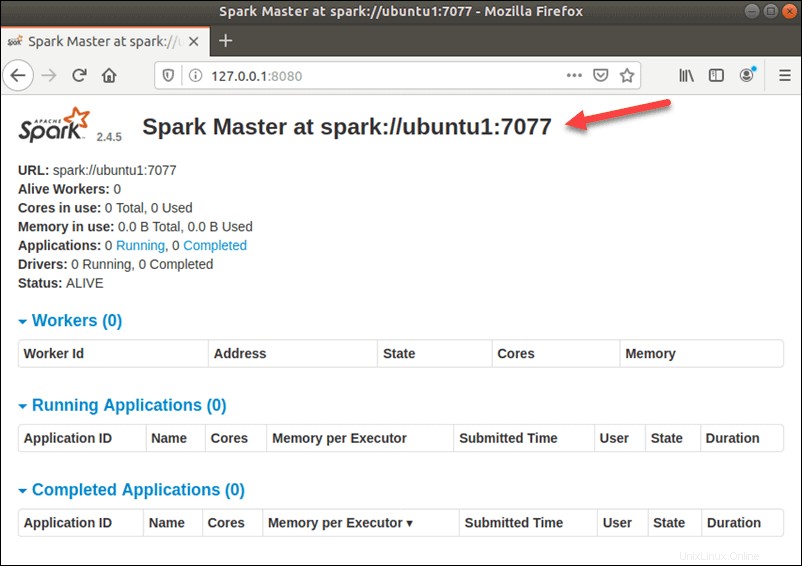
En esta configuración independiente de un solo servidor, iniciaremos un servidor esclavo junto con el servidor maestro. El start-slave.sh el comando se usa para iniciar el proceso Spark Worker:
start-slave.sh spark://ubuntu1:7077
Ahora que un trabajador está en funcionamiento, si vuelve a cargar la interfaz de usuario web de Spark Master, debería verlo en la lista:
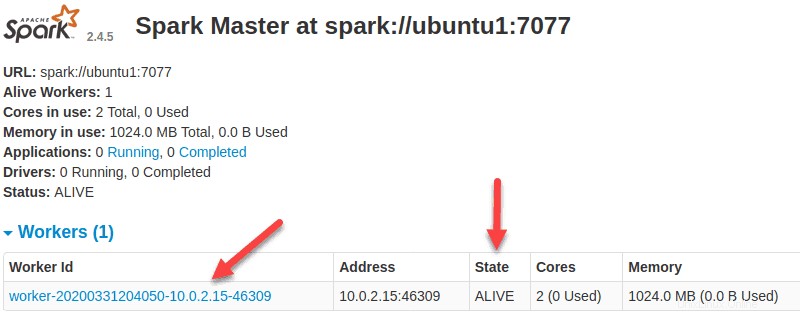
Una vez finalizada la configuración, inicie el servidor maestro y esclavo, pruebe si Spark Shell funciona:
spark-shell
Obtendrá la siguiente interfaz:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala> ¡Felicitaciones! Ha instalado Apache Spark correctamente. Gracias por usar este tutorial para instalar la última versión de Apache Spark en Debian 11 Bullseye. Para obtener ayuda adicional o información útil, le recomendamos que consulte la Sitio web de Apache Spark.