Introducción
En la terminología de Hive, las tablas externas son tablas que no se administran con Hive. Su propósito es facilitar la importación de datos desde un archivo externo al metastore.
Los datos de la tabla externa se almacenan externamente, mientras que Hive metastore solo contiene el esquema de metadatos. En consecuencia, eliminar una tabla externa no afecta los datos.
En este tutorial, aprenderá a crear, consultar y soltar una tabla externa en Hive.

Requisitos previos
- Ubuntu 18.04 LTS o posterior
- Acceso a la línea de comandos con privilegios sudo
- Apache Hadoop instalado y funcionando
- Apache Hive instalado y funcionando
Creación de una tabla externa en Hive:explicación de la sintaxis
Al crear una tabla externa en Hive, debe proporcionar la siguiente información:
- Nombre de la tabla – El
create external tablecomando crea la tabla. Si ya existe una tabla con el mismo nombre en el sistema, esto generará un error. Para evitar esto, agregueif not existsa la declaración. Los nombres de las tablas no distinguen entre mayúsculas y minúsculas. - Nombres y tipos de columnas – Al igual que los nombres de las tablas, los nombres de las columnas no distinguen entre mayúsculas y minúsculas. Los tipos de columna son valores como
int,char,string, etc. - Formato de fila – Las filas usan formatos SerDe (Serializador/Deserializador) nativos o personalizados. Native SerDe se utilizará si el formato de fila no está definido o si se especifica como delimitado.
- Carácter de terminación de campo – Este es un
charescriba el carácter que separa los valores de la tabla en una fila. - Formato de almacenamiento – Puede especificar formatos de almacenamiento como archivo de texto, archivo de secuencia, archivo json, etc.
- Ubicación – Esta es la ubicación del directorio HDFS del archivo que contiene los datos de la tabla.
La sintaxis correcta para proporcionar esta información a Hive es:
create external table if not exists [external-table-name] (
[column1-name] [column1-type], [column2-name] [column2-type], …)
comment '[comment]'
row format [format-type]
fields terminated by '[termination-character]'
stored as [storage-type]
location '[location]';Crear una tabla externa de Hive:ejemplo
A modo de ejemplo práctico, este tutorial le mostrará cómo importar datos de un archivo CSV a una tabla externa.
Paso 1:preparar el archivo de datos
1. Cree un archivo CSV titulado "países.csv":
sudo nano countries.csv2. Para cada país de la lista, escriba un número de fila, el nombre del país, su ciudad capital y su población en millones:
1,USA,Washington,328
2,France,Paris,67
3,Spain,Madrid,47
4,Russia,Moscow,145
5,Indonesia,Jakarta,267
6,Nigeria,Abuja,196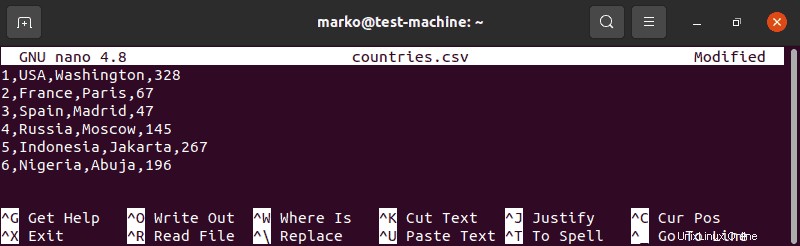
3. Guarde el archivo y tome nota de su ubicación.
Paso 2:Importe el archivo a HDFS
1. Cree un directorio HDFS. Utilizará este directorio como una ubicación HDFS del archivo que creó.
hdfs dfs -mkdir [hdfs-directory-name]2. Importe el archivo CSV a HDFS:
hdfs dfs -put [original-file-location] [hdfs-directory-name]
3. Usa el -ls comando para verificar que el archivo está en la carpeta HDFS:
hdfs dfs -ls [hdfs-directory-name]
La salida muestra todos los archivos actualmente en el directorio.
Paso 3:Crear una tabla externa
1. Después de importar el archivo de datos a HDFS, inicie Hive y use la sintaxis explicada anteriormente para crear una tabla externa.
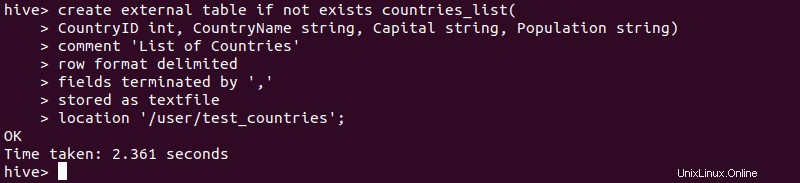
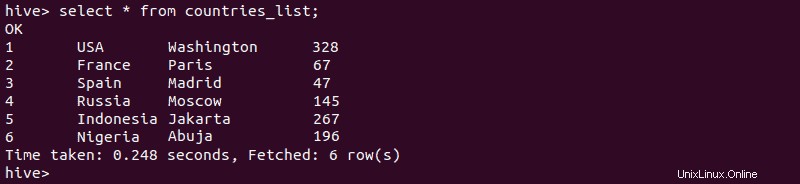
2. Para verificar que la creación de la tabla externa fue exitosa, escriba:
select * from [external-table-name];El resultado debe enumerar los datos del archivo CSV que importó a la tabla:
3. Si desea crear una tabla administrada utilizando los datos de una tabla externa, escriba:
create table if not exists [managed-table-name](
[column1-name] [column1-type], [column2-name] [var2-name], …)
comment '[comment]';
4. A continuación, importe los datos de la tabla externa:
insert overwrite table [managed-table-name] select * from [external-table-name];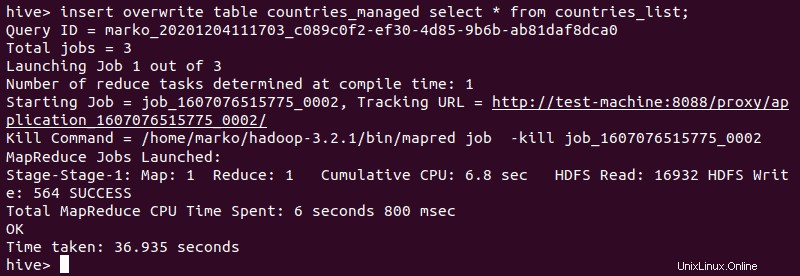
5. Verifique que los datos se hayan insertado correctamente en la tabla administrada.
select * from [managed-table-name];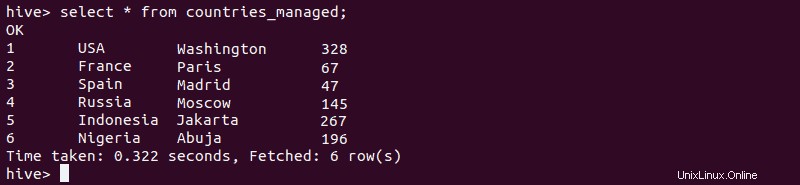
Cómo consultar una tabla externa de Hive
Para mostrar todos los datos almacenados en una tabla, utilizará el select * from comando seguido del nombre de la tabla. Hive ofrece una amplia lista de comandos de consulta que le permiten restringir sus búsquedas y ordenar los datos según sus preferencias.
Por ejemplo, puede usar el where comando después de select * from para especificar una condición:
select * from [table_name] where [condition];Hive generará solo las filas que satisfagan la condición dada en la consulta:

En lugar del asterisco carácter que significa "todos los datos", puede utilizar determinantes más específicos. Reemplazar el asterisco con un nombre de columna (como CountryName , del ejemplo anterior) le mostrará solo los datos de la columna elegida.
Aquí hay algunas otras funciones de consulta útiles y su sintaxis:
| Función | Sintaxis |
|---|---|
| Consultar una tabla según múltiples condiciones | select * from [table_name] where [condition1] and [condition2]; |
| Datos de la tabla de pedidos | select [column1_name], [column2_name] from [table_name] order by [column_name]; |
| Ordenar los datos de la tabla en orden descendente | select [column1_name], [column2_name] from [table_name] order by [column_name] desc; |
| Mostrar el número de filas | select count(*) from [table_name]; |

