Introducción
Cada industria importante está implementando Apache Hadoop como el marco estándar para procesar y almacenar grandes datos. Hadoop está diseñado para implementarse en una red de cientos o incluso miles de servidores dedicados. Todas estas máquinas trabajan juntas para manejar el volumen masivo y la variedad de conjuntos de datos entrantes.
La implementación de los servicios de Hadoop en un solo nodo es una excelente manera de familiarizarse con los comandos y conceptos básicos de Hadoop.
Esta guía fácil de seguir lo ayuda a instalar Hadoop en Ubuntu 18.04 o Ubuntu 20.04.

Requisitos previos
- Acceso a una ventana de terminal/línea de comando
- Sudo o raíz privilegios en máquinas locales/remotas
Instalar OpenJDK en Ubuntu
El marco Hadoop está escrito en Java y sus servicios requieren un Java Runtime Environment (JRE) y un Java Development Kit (JDK) compatibles. Use el siguiente comando para actualizar su sistema antes de iniciar una nueva instalación:
sudo apt updatePor el momento, Apache Hadoop 3.x es totalmente compatible con Java 8 . El paquete OpenJDK 8 en Ubuntu contiene tanto el entorno de tiempo de ejecución como el kit de desarrollo.
Escriba el siguiente comando en su terminal para instalar OpenJDK 8:
sudo apt install openjdk-8-jdk -yLa versión OpenJDK u Oracle Java puede afectar la forma en que interactúan los elementos de un ecosistema Hadoop. Para instalar una versión específica de Java, consulte nuestra guía detallada sobre cómo instalar Java en Ubuntu.
Una vez que se complete el proceso de instalación, verifique la versión actual de Java:
java -version; javac -versionEl resultado le informa qué edición de Java está en uso.

Configurar un usuario no raíz para el entorno de Hadoop
Es recomendable crear un usuario no root, específicamente para el entorno Hadoop. Un usuario distinto mejora la seguridad y lo ayuda a administrar su clúster de manera más eficiente. Para garantizar el buen funcionamiento de los servicios de Hadoop, el usuario debe poder establecer una conexión SSH sin contraseña con el host local.
Instalar OpenSSH en Ubuntu
Instale el servidor y el cliente OpenSSH usando el siguiente comando:
sudo apt install openssh-server openssh-client -yEn el siguiente ejemplo, el resultado confirma que la última versión ya está instalada.

Si ha instalado OpenSSH por primera vez, aproveche esta oportunidad para implementar estas recomendaciones vitales de seguridad de SSH.
Crear usuario de Hadoop
Utilice el adduser comando para crear un nuevo usuario de Hadoop:
sudo adduser hdoopEl nombre de usuario, en este ejemplo, es hdoop . Eres libre de usar cualquier nombre de usuario y contraseña que creas conveniente. Cambie al usuario recién creado e ingrese la contraseña correspondiente:
su - hdoopEl usuario ahora debe poder acceder al host local mediante SSH sin que se le solicite una contraseña.
Habilitar SSH sin contraseña para el usuario de Hadoop
Genere un par de claves SSH y defina la ubicación en la que se almacenará en:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsaEl sistema procede a generar y guardar el par de claves SSH.
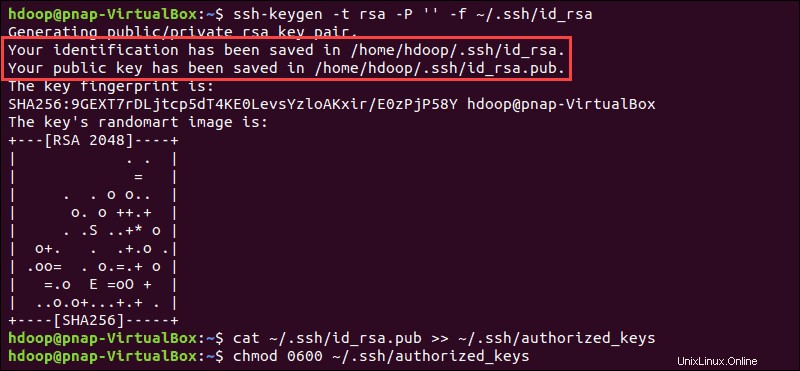
Usa el cat comando para almacenar la clave pública como authorized_keys en el ssh directorio:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Establezca los permisos para su usuario con chmod comando:
chmod 0600 ~/.ssh/authorized_keysEl nuevo usuario ahora puede usar SSH sin necesidad de ingresar una contraseña cada vez. Verifique que todo esté configurado correctamente usando hdoop usuario a SSH a localhost:
ssh localhostDespués de un aviso inicial, el usuario de Hadoop ahora puede establecer una conexión SSH al host local sin problemas.
Descargar e instalar Hadoop en Ubuntu
Visite la página oficial del proyecto Apache Hadoop y seleccione la versión de Hadoop que desea implementar.
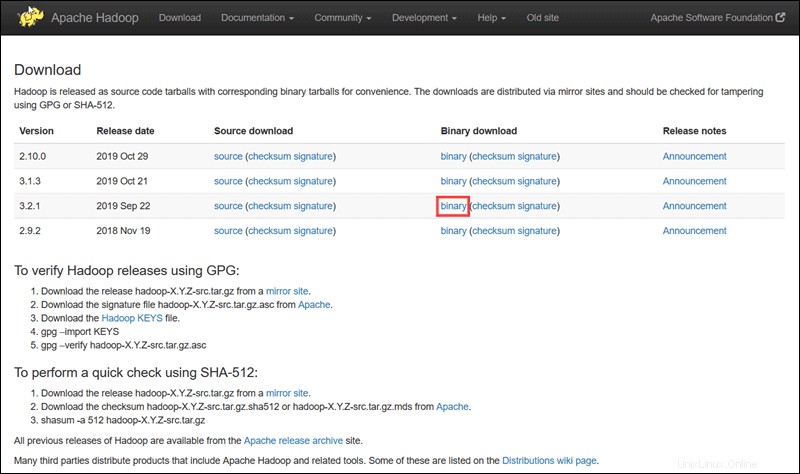
Los pasos descritos en este tutorial usan la descarga binaria para Hadoop versión 3.2.1 .
Seleccione su opción preferida y verá un enlace espejo que le permitirá descargar el paquete tar de Hadoop. .
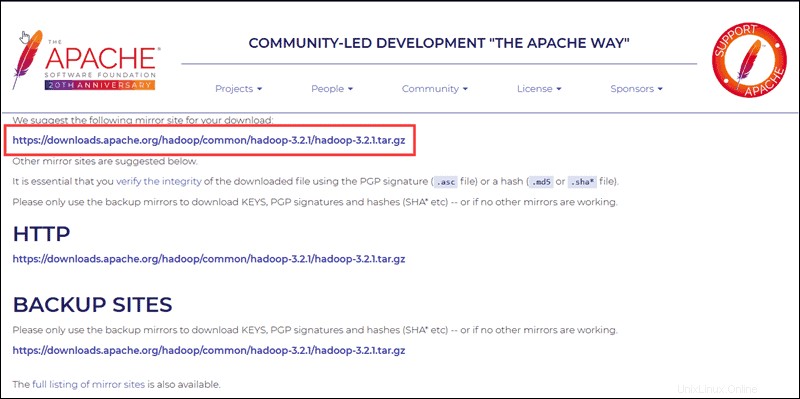
Use el enlace espejo provisto y descargue el paquete Hadoop con wget comando:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz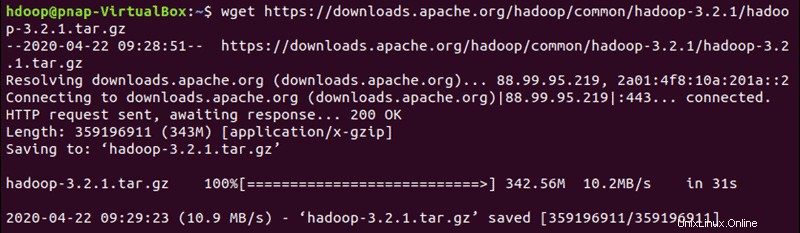
Una vez que se complete la descarga, extraiga los archivos para iniciar la instalación de Hadoop:
tar xzf hadoop-3.2.1.tar.gzLos archivos binarios de Hadoop ahora se encuentran dentro de hadoop-3.2.1 directorio.
Implementación de Hadoop de un solo nodo (modo pseudodistribuido)
Hadoop sobresale cuando se implementa en un modo totalmente distribuido en un gran grupo de servidores en red. Sin embargo, si es nuevo en Hadoop y desea explorar comandos básicos o probar aplicaciones, puede configurar Hadoop en un solo nodo.
Esta configuración, también llamada modo pseudo-distribuido , permite que cada demonio de Hadoop se ejecute como un único proceso de Java. Un entorno Hadoop se configura editando un conjunto de archivos de configuración:
- bashrc
- hadoop-env.sh
- sitio-principal.xml
- sitio hdfs.xml
- mapeado-sitio-xml
- sitio-hilo.xml
Configurar variables de entorno de Hadoop (bashrc)
Edite el .bashrc archivo de configuración de shell usando un editor de texto de su elección (estaremos usando nano):
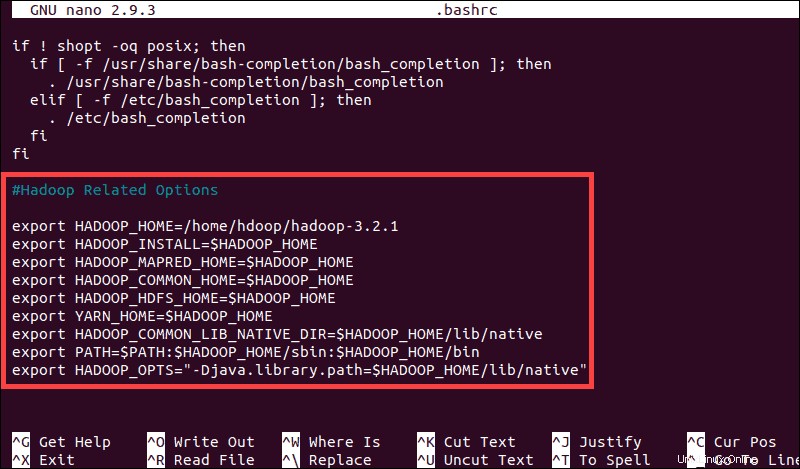
sudo nano .bashrcDefina las variables de entorno de Hadoop agregando el siguiente contenido al final del archivo:
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
Una vez que agregue las variables, guarde y salga de .bashrc archivo.
Es fundamental aplicar los cambios al entorno de ejecución actual mediante el siguiente comando:
source ~/.bashrcEditar archivo hadoop-env.sh
hadoop-env.sh El archivo sirve como un archivo maestro para configurar los ajustes de proyectos relacionados con YARN, HDFS, MapReduce y Hadoop.
Al configurar un clúster Hadoop de nodo único , debe definir qué implementación de Java se utilizará. Use el $HADOOP_HOME creado anteriormente variable para acceder a hadoop-env.sh archivo:
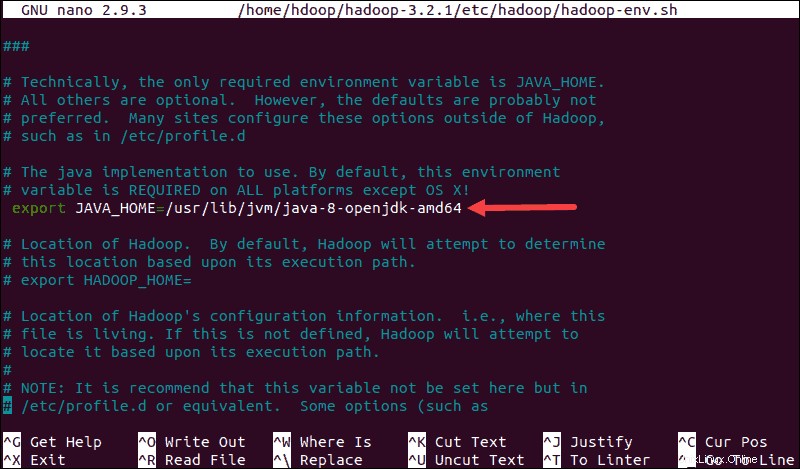
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Descomente el $JAVA_HOME variable (es decir, elimine el # sign) y agregue la ruta completa a la instalación de OpenJDK en su sistema. Si ha instalado la misma versión que se presentó en la primera parte de este tutorial, agregue la siguiente línea:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64La ruta debe coincidir con la ubicación de la instalación de Java en su sistema.
Si necesita ayuda para ubicar la ruta correcta de Java, ejecute el siguiente comando en la ventana de su terminal:
which javacLa salida resultante proporciona la ruta al directorio binario de Java.

Use la ruta provista para encontrar el directorio OpenJDK con el siguiente comando:
readlink -f /usr/bin/javac
La sección de la ruta justo antes de /bin/javac el directorio debe asignarse a $JAVA_HOME variables.

Editar archivo core-site.xml
El sitio-principal.xml El archivo define las propiedades principales de HDFS y Hadoop.
Para configurar Hadoop en modo pseudodistribuido, debe especificar la URL para su NameNode, y el directorio temporal que Hadoop usa para el proceso de mapa y reducción.
Abra el core-site.xml archivo en un editor de texto:
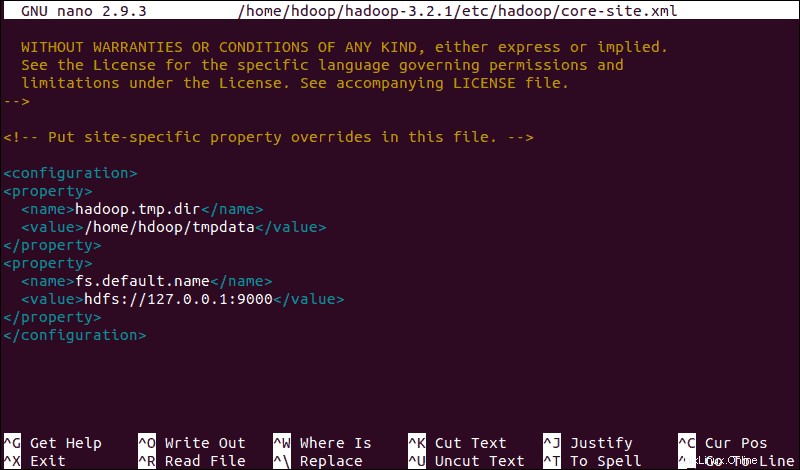
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlAgregue la siguiente configuración para anular los valores predeterminados para el directorio temporal y agregue su URL de HDFS para reemplazar la configuración predeterminada del sistema de archivos local:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>Este ejemplo utiliza valores específicos del sistema local. Debe utilizar valores que coincidan con los requisitos de su sistema. Los datos deben ser coherentes durante todo el proceso de configuración.
No olvide crear un directorio de Linux en la ubicación que especificó para sus datos temporales.
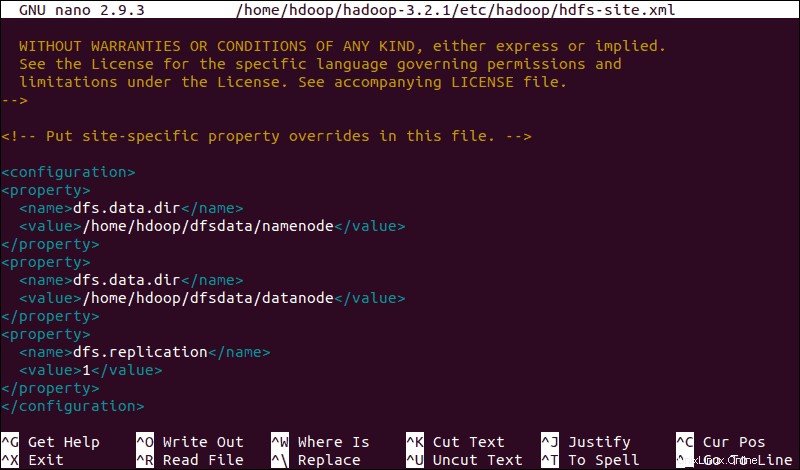
Editar archivo hdfs-site.xml
Las propiedades en el hdfs-site.xml El archivo rige la ubicación para almacenar los metadatos del nodo, el archivo fsimage y el archivo de registro de edición. Configure el archivo definiendo el NameNode y directorios de almacenamiento de DataNode .
Además, el dfs.replication predeterminado valor de 3 debe cambiarse a 1 para que coincida con la configuración de un solo nodo.
Use el siguiente comando para abrir hdfs-site.xml archivo para editar:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlAgregue la siguiente configuración al archivo y, si es necesario, ajuste los directorios NameNode y DataNode a sus ubicaciones personalizadas:
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Si es necesario, cree los directorios específicos que definió para dfs.data.dir valor.
Editar archivo mapred-site.xml
Use el siguiente comando para acceder a mapred-site.xml archivo y definir valores de MapReduce :
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Agregue la siguiente configuración para cambiar el valor predeterminado del nombre del marco MapReduce a yarn :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>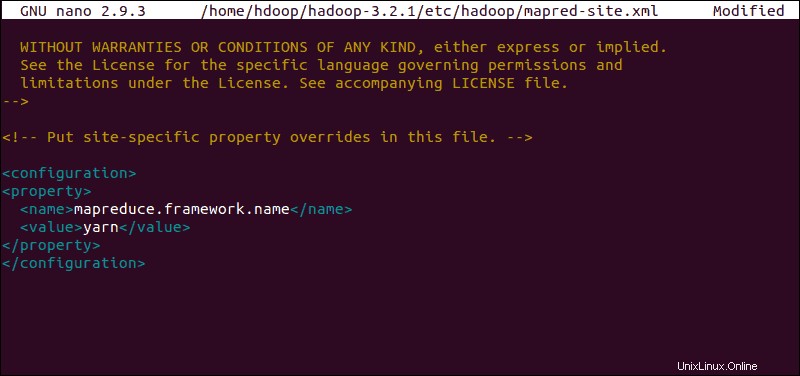
Editar archivo yarn-site.xml
El sitio-hilo.xml El archivo se usa para definir configuraciones relevantes para YARN . Contiene configuraciones para el Administrador de nodos, Administrador de recursos, Contenedores, y maestro de aplicaciones .
Abra el yarn-site.xml archivo en un editor de texto:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlAgregue la siguiente configuración al archivo:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>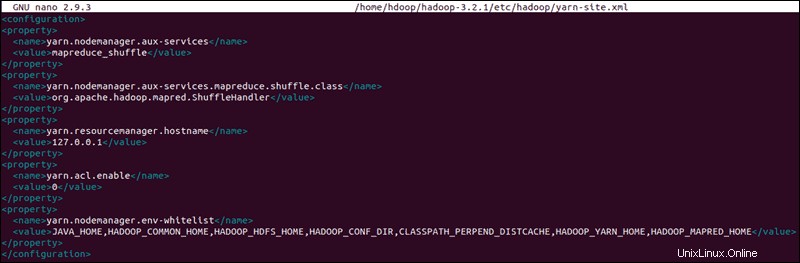
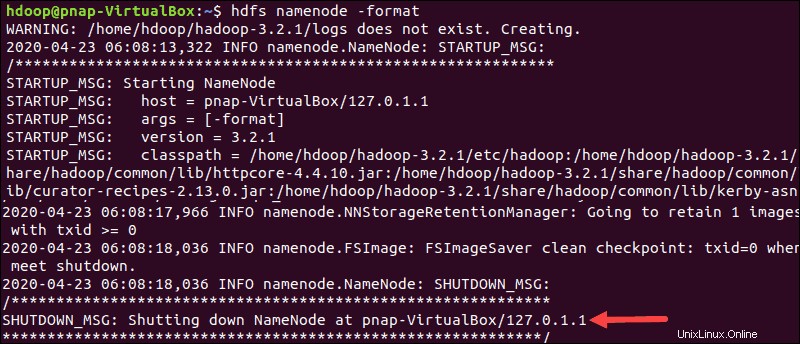
Dar formato al nodo de nombre HDFS
Es importante formatear el NameNode antes de iniciar los servicios de Hadoop por primera vez:
hdfs namenode -formatLa notificación de cierre significa el final del proceso de formateo de NameNode.
Iniciar clúster de Hadoop
Vaya a hadoop-3.2.1/sbin directorio y ejecute los siguientes comandos para iniciar NameNode y DataNode:
./start-dfs.shEl sistema tarda unos minutos en iniciar los nodos necesarios.

Una vez que el nodo de nombre, los nodos de datos y el nodo de nombre secundario estén en funcionamiento, inicie el recurso YARN y los administradores de nodos escribiendo:
./start-yarn.shAl igual que con el comando anterior, la salida le informa que los procesos se están iniciando.

Escriba este comando simple para verificar si todos los demonios están activos y ejecutándose como procesos Java:
jpsSi todo funciona según lo previsto, la lista resultante de procesos Java en ejecución contiene todos los demonios HDFS y YARN.

Acceder a la interfaz de usuario de Hadoop desde el navegador
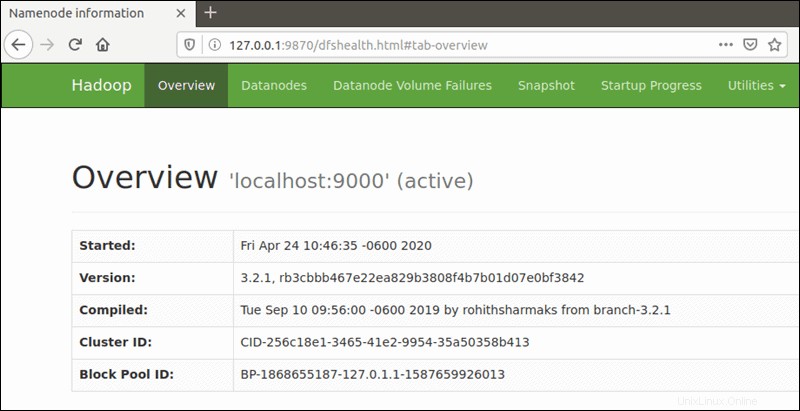
Use su navegador preferido y navegue a su URL o IP localhost. El número de puerto predeterminado 9870 le da acceso a la interfaz de usuario de Hadoop NameNode:
http://localhost:9870La interfaz de usuario de NameNode proporciona una descripción completa de todo el clúster.
El puerto predeterminado 9864 se utiliza para acceder a DataNodes individuales directamente desde su navegador:
http://localhost:9864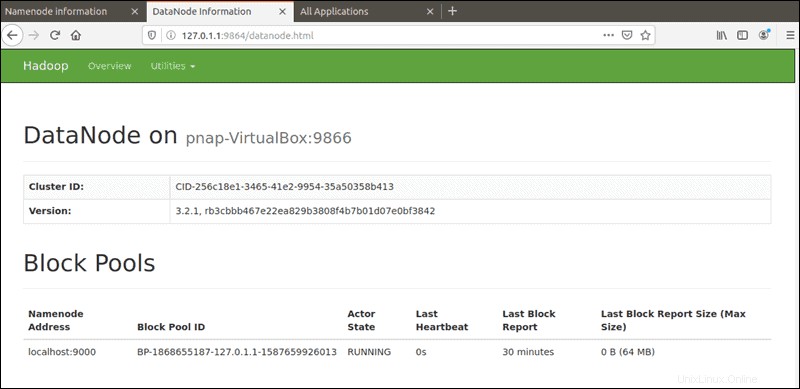
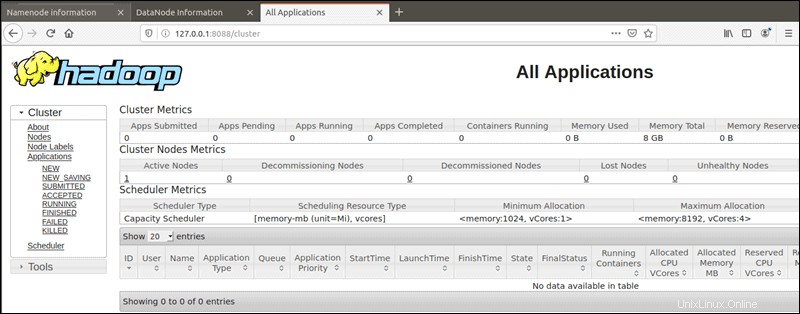
Se puede acceder al administrador de recursos de YARN en el puerto 8088 :
http://localhost:8088El Administrador de recursos es una herramienta invaluable que le permite monitorear todos los procesos en ejecución en su clúster de Hadoop.