Hadoop es un marco de software gratuito, de código abierto y basado en Java que se utiliza para el almacenamiento y procesamiento de grandes conjuntos de datos en clústeres de máquinas. Utiliza HDFS para almacenar sus datos y procesar estos datos usando MapReduce. Es un ecosistema de herramientas de Big Data que se utilizan principalmente para la extracción de datos y el aprendizaje automático.
Apache Hadoop 3.3 viene con mejoras notables y muchas correcciones de errores con respecto a las versiones anteriores. Tiene cuatro componentes principales, como Hadoop Common, HDFS, YARN y MapReduce.
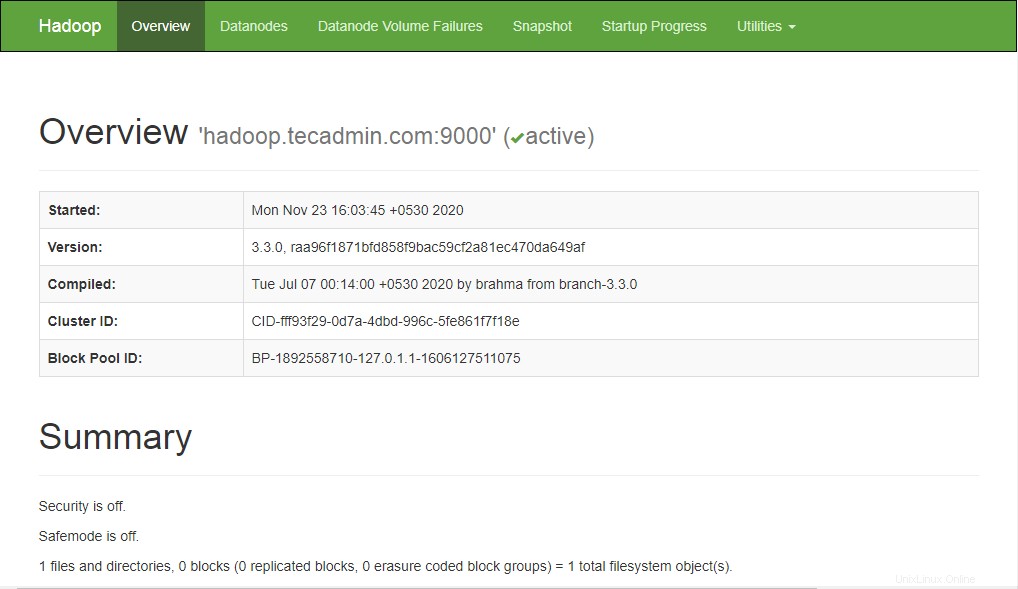
Este tutorial le explicará cómo instalar y configurar Apache Hadoop en el sistema Ubuntu 20.04 LTS Linux.
Paso 1:Instalación de Java
Hadoop está escrito en Java y solo es compatible con la versión 8 de Java. La versión 3.3 de Hadoop y la más reciente también son compatibles con el tiempo de ejecución de Java 11 y con Java 8.
Puede instalar OpenJDK 11 desde los repositorios apt predeterminados:
sudo apt updatesudo apt install openjdk-11-jdk
Una vez instalado, verifique la versión instalada de Java con el siguiente comando:
java -version
Deberías obtener el siguiente resultado:
openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
Paso 2:crear un usuario de Hadoop
Es una buena idea crear un usuario separado para ejecutar Hadoop por razones de seguridad.
Ejecute el siguiente comando para crear un nuevo usuario con el nombre hadoop:
sudo adduser hadoop
Proporcione y confirme la nueva contraseña como se muestra a continuación:
Adding user `hadoop' ...
Adding new group `hadoop' (1002) ...
Adding new user `hadoop' (1002) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
Paso 3:configurar la autenticación basada en clave SSH
A continuación, deberá configurar la autenticación SSH sin contraseña para el sistema local.
Primero, cambie el usuario a hadoop con el siguiente comando:
su - hadoop
A continuación, ejecute el siguiente comando para generar pares de claves públicas y privadas:
ssh-keygen -t rsa
Se le pedirá que introduzca el nombre del archivo. Simplemente presione Entrar para completar el proceso:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:QSa2syeISwP0hD+UXxxi0j9MSOrjKDGIbkfbM3ejyIk [email protected] The key's randomart image is: +---[RSA 3072]----+ | ..o++=.+ | |..oo++.O | |. oo. B . | |o..+ o * . | |= ++o o S | |.++o+ o | |.+.+ + . o | |o . o * o . | | E + . | +----[SHA256]-----+
A continuación, agregue las claves públicas generadas desde id_rsa.pub a authorized_keys y establezca el permiso adecuado:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 640 ~/.ssh/authorized_keys
A continuación, verifique la autenticación SSH sin contraseña con el siguiente comando:
ssh localhost
Se le pedirá que autentique los hosts agregando claves RSA a los hosts conocidos. Escriba sí y presione Entrar para autenticar el servidor local:
The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is SHA256:JFqDVbM3zTPhUPgD5oMJ4ClviH6tzIRZ2GD3BdNqGMQ. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Paso 4:Instalación de Hadoop
Primero, cambie el usuario a hadoop con el siguiente comando:
su - hadoop
A continuación, descargue la última versión de Hadoop con el comando wget:
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
Una vez descargado, extraiga el archivo descargado:
tar -xvzf hadoop-3.3.0.tar.gz
A continuación, cambie el nombre del directorio extraído a hadoop:
mv hadoop-3.3.0 hadoop
A continuación, deberá configurar las variables de entorno Hadoop y Java en su sistema.
Abra el ~/.bashrc archivo en su editor de texto favorito:
nano ~/.bashrc
Agregue las siguientes líneas al archivo. Puede encontrar la ubicación de JAVA_HOME ejecutando dirname $(dirname $(readlink -f $(which java))) command on terminal.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Save and close the file. Then, activate the environment variables with the following command:
source ~/.bashrc
A continuación, abra el archivo de variables de entorno de Hadoop:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Nuevamente configure JAVA_HOME en el entorno Hadoop.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Guarde y cierre el archivo cuando haya terminado.
Paso 5:Configuración de Hadoop
Primero, deberá crear los directorios namenode y datanode dentro del directorio de inicio de Hadoop:
Ejecute el siguiente comando para crear ambos directorios:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
A continuación, edite el core-site.xml archivo y actualización con el nombre de host de su sistema:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Cambie el siguiente nombre según el nombre de host de su sistema:
XHTML
| 1234567891011121314151617 |
| 123456 |
| 123456 |