Si tiene datos que no son adecuados para la base de datos relacional, es probable que esté buscando una solución NoSQL. Las opciones de NoSQL son diversas, Aerospike, MongoDB, Redis y muchos otros intentan resolver el problema de Big Data de diferentes maneras. En este artículo nos concentraremos en la replicación con cassandra. Esta base de datos en realidad obtuvo el nombre de la mitología griega, Cassandra era la vidente que siempre predijo correctamente el futuro, pero todos no le creyeron. Por lo tanto, los creadores de esta base de datos predicen que NoSQL reemplazará en el futuro a las bases de datos relacionales, pero no esperan que la gente de RDBMS les crea.
Requisitos
Para seguir este artículo, debe tener 3 nodos configurados uno por uno utilizando nuestra guía de configuración anterior de Cassandra. Debe tener los tres nodos en funcionamiento y tres ventanas de terminal con sesión ssh en cada una. Después de eso, comenzamos a conectar los nodos de Cassandra en un clúster.
Creación de un clúster
Ingresado como usuario de Cassandra, debe editar la configuración de Cassandra en cada uno de los tres nodos. El archivo se llama cassandra.yaml
nano ~/conf/cassandra.yamlEsto debe configurarse en los 3 servidores. La línea de semillas puede ingresarse en un servidor y luego copiarse, pero las direcciones IP de cada servidor deben ingresarse como genuinas.
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "your-server-ip,your-server-ip-2,your-server-ip-3"
listen_address: your-server-ip
rpc_address: your-server-ipPara configurar entpoint snitch, pegue este oneliner en los tres nodos:
sed -i 's/endpoint_snitch: SimpleSnitch/endpoint_snitch: GossipingPropertyFileSnitch/g' ~/conf/cassandra.yamlY use este comando para agregar una línea de arranque al final del archivo.
echo 'auto_bootstrap: false' >> ~/conf/cassandra.yamlEl soplón que configuramos tiene un nombre de centro de datos incompatible, dc1 en lugar de datacenter1, así que arreglemos eso en los tres nodos:
sed -i 's/dc=dc1/dc=datacenter1/g' ~/conf/cassandra-rackdc.propertiesReinicie los tres nodos si es necesario, y después de eso, el estado de sh bin/nodetool debería mostrarle algo como esto:
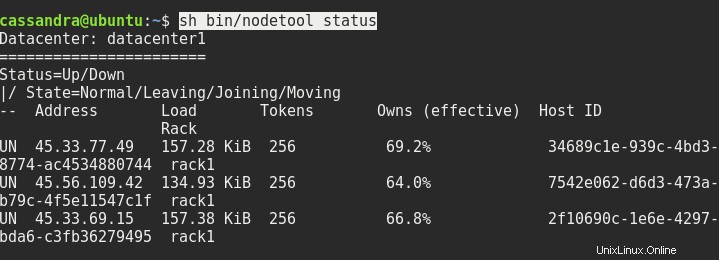
Lo siguiente que debemos hacer es conectarnos a la consola desde uno de los nodos al otro nodo. Necesitamos escribir la dirección del servidor y el puerto 9042 después de cqlsh así:
cqlsh ip.addr.of.node 9042El inicio de sesión del host local solo con cqlsh no funcionará.
Configuración de replicación
Si te preguntas por qué cambiamos la configuración predeterminada del soplón, ahora te lo explicaré. En general, hay dos estrategias de replicación con Cassandra. SimpleStrategy y NetworkTopologyStrategy. Primero usa el soplón predeterminado, el segundo usa el soplón que hemos configurado. Necesitamos esta estrategia avanzada si queremos escalar fácilmente el clúster. Con esta estrategia, puede agregar más nodos en otro centro de datos y expandir el clúster por todo el mundo.
Así que dentro de la consola cqlsh necesitamos escribir esto:
CREATE KEYSPACE linoxide WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1' : 3};Creará un nuevo espacio de claves llamado linoxide, con la replicación configurada con NetworkTopologyStrategy y hará 3 réplicas en datacenter1.
Ok, veamos entonces lo que creamos. El comando está en negrita, se emite el resto.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | replication
--------------------+----------------+---------------------------------------------------------------------------------------
linoxide | True | {'class': 'org.apache.cassandra.locator.NetworkTopologyStrategy', 'datacenter1': '3'}
system_auth | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'}
system_schema | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_distributed | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '3'}
system | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_traces | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '2'}Salgamos de cqlsh y ejecutemos el comando nodetool una vez más, para ver el cambio en el clúster.
nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 45.33.77.49 250.7 KiB 256 100.0% 34689c1e-939c-4bd3-8774-ac4534880744 rack1
UN 45.56.109.42 188.02 KiB 256 100.0% 7542e062-d6d3-473a-b79c-4f5e11547c1f rack1
UN 45.33.69.15 236.58 KiB 256 100.0% 2f10690c-1e6e-4297-bda6-c3fb36279495 rack1Observe que cada nodo ahora tiene el 100 % de los datos, frente al 66 % anterior. Eso se debe al factor de replicación 3 que configuramos, ahora tenemos una copia de los datos en cada nodo.
Conclusión
Entonces, hemos configurado el clúster de Cassandra con replicación. Desde aquí, puede agregar más nodos, bastidores y centros de datos, puede importar una cantidad arbitraria de datos y cambiar el factor de replicación en todos o algunos de los centros de datos. Para conocer las formas de hacerlo, puede consultar la documentación oficial de Cassandra. Espero que esta guía le haya ayudado a sumergirse en el futuro de la tecnología de bases de datos y que haya decidido creerle a Cassandra. Gracias por leer y que tenga un buen día.