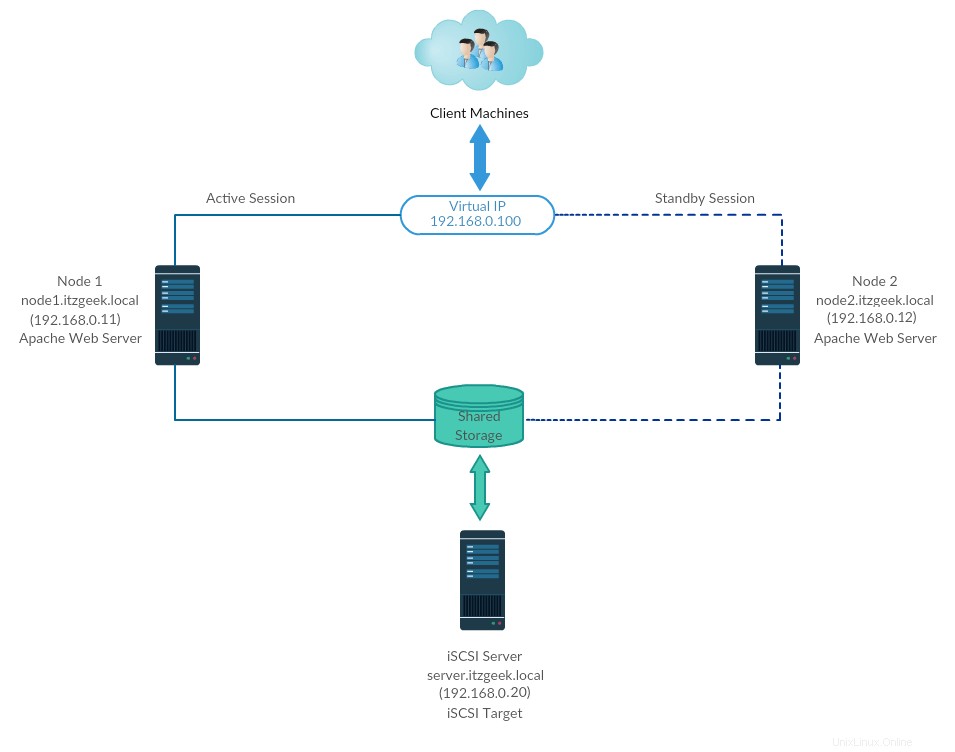
El clúster de alta disponibilidad, también conocido como clúster de conmutación por error o clúster activo-pasivo, es uno de los tipos de clúster más utilizados en un entorno de producción para tener una disponibilidad continua de los servicios, incluso si uno de los nodos del clúster falla.
En términos técnicos, si el servidor que ejecuta la aplicación falla por algún motivo (p. ej., falla de hardware), el software del clúster (marcapasos) reiniciará la aplicación en el nodo de trabajo.
La conmutación por error no es solo reiniciar una aplicación; es una serie de operaciones asociadas con él, como montar sistemas de archivos, configurar redes e iniciar aplicaciones dependientes.
Aquí, configuraremos un clúster de conmutación por error con Pacemaker para hacer que el servidor Apache (web) sea una aplicación de alta disponibilidad.
Aquí, configuraremos el servidor web Apache, el sistema de archivos y las redes como recursos para nuestro clúster.
Para un recurso del sistema de archivos, estaríamos usando almacenamiento compartido proveniente del almacenamiento iSCSI.
| Nombre de host | Dirección IP | SO | Propósito |
|---|
| node1.itzgeek.local | 192.168.0.11 | CentOS 8 | Nodo de clúster 1 |
| node2.itzgeek.local | 192.168.0.12 | Nodo de clúster 2 |
| storage.itzgeek.local | 192.168.0.20 | Almacenamiento compartido iSCSI |
| 192.168.0.100 | IP de clúster virtual (Apache) |
Todos se ejecutan en VMware Workstation.
Almacenamiento compartido
El almacenamiento compartido es uno de los recursos críticos en el clúster de alta disponibilidad, ya que almacena los datos de una aplicación en ejecución. Todos los nodos de un clúster tendrán acceso al almacenamiento compartido para los datos más recientes.
El almacenamiento SAN es el almacenamiento compartido ampliamente utilizado en un entorno de producción. Debido a limitaciones de recursos, para esta demostración, configuraremos un clúster con almacenamiento iSCSI con fines demostrativos.
Paquetes de instalación
servidor iSCSI
[root@storage ~]# dnf install -y targetcli lvm2
Nodos de clúster
dnf install -y iscsi-initiator-utils lvm2
Configurar disco compartido
Hagamos una lista de los discos disponibles en el servidor iSCSI usando el siguiente comando.
[root@storage ~]# fdisk -l | grep -i sd
Output:
Disk /dev/sda: 100 GiB, 107374182400 bytes, 209715200 sectors
/dev/sda1 * 2048 2099199 2097152 1G 83 Linux
/dev/sda2 2099200 209715199 207616000 99G 8e Linux LVM
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
En el resultado anterior, puede ver que mi sistema tiene un disco duro de 10 GB (/dev/sdb).
Aquí, crearemos un LVM en el servidor iSCSI para usarlo como almacenamiento compartido para nuestros nodos de clúster.
[root@storage ~]# pvcreate /dev/sdb
[root@storage ~]# vgcreate vg_iscsi /dev/sdb
[root@storage ~]# lvcreate -l 100%FREE -n lv_iscsi vg_iscsi
Crear almacenamiento compartido
Obtenga los detalles del iniciador de los nodos.
cat /etc/iscsi/initiatorname.iscsi
Nodo 1:
InitiatorName=iqn.1994-05.com.redhat:121c93cbad3a
Nodo 2:
InitiatorName=iqn.1994-05.com.redhat:827e5e8fecb
Ingrese el siguiente comando para obtener una CLI de iSCSI para un aviso interactivo.
[root@storage ~]# targetcli
Output:
Warning: Could not load preferences file /root/.targetcli/prefs.bin.
targetcli shell version 2.1.fb49
Copyright 2011-2013 by Datera, Inc and others.
For help on commands, type 'help'.
/> cd /backstores/block
/backstores/block> create iscsi_shared_storage /dev/vg_iscsi/lv_iscsi
Created block storage object iscsi_shared_storage using /dev/vg_iscsi/lv_iscsi.
/backstores/block> cd /iscsi
/iscsi> create
Created target iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18.
Created TPG 1.
Global pref auto_add_default_portal=true
Created default portal listening on all IPs (0.0.0.0), port 3260.
/iscsi> cd iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18/tpg1/acls << Change as per the output of previous command
/iscsi/iqn.20...e18/tpg1/acls> create iqn.1994-05.com.redhat:121c93cbad3a << Node 1
Created Node ACL for iqn.1994-05.com.redhat:121c93cbad3a
/iscsi/iqn.20...e18/tpg1/acls> create iqn.1994-05.com.redhat:827e5e8fecb << Node 2
Created Node ACL for iqn.1994-05.com.redhat:827e5e8fecb
/iscsi/iqn.20...e18/tpg1/acls> cd /iscsi/iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18/tpg1/luns
/iscsi/iqn.20...e18/tpg1/luns> create /backstores/block/iscsi_shared_storage
Created LUN 0.
Created LUN 0->0 mapping in node ACL iqn.1994-05.com.redhat:827e5e8fecb
Created LUN 0->0 mapping in node ACL iqn.1994-05.com.redhat:121c93cbad3a
/iscsi/iqn.20...e18/tpg1/luns> cd /
/> ls
o- / ......................................................................................................................... [...]
o- backstores .............................................................................................................. [...]
| o- block .................................................................................................. [Storage Objects: 1]
| | o- iscsi_shared_storage .............................................. [/dev/vg_iscsi/lv_iscsi (10.0GiB) write-thru activated]
| | o- alua ................................................................................................... [ALUA Groups: 1]
| | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized]
| o- fileio ................................................................................................. [Storage Objects: 0]
| o- pscsi .................................................................................................. [Storage Objects: 0]
| o- ramdisk ................................................................................................ [Storage Objects: 0]
o- iscsi ............................................................................................................ [Targets: 1]
| o- iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18 ......................................................... [TPGs: 1]
| o- tpg1 ............................................................................................... [no-gen-acls, no-auth]
| o- acls .......................................................................................................... [ACLs: 2]
| | o- iqn.1994-05.com.redhat:121c93cbad3a .................................................................. [Mapped LUNs: 1]
| | | o- mapped_lun0 .................................................................. [lun0 block/iscsi_shared_storage (rw)]
| | o- iqn.1994-05.com.redhat:827e5e8fecb ................................................................... [Mapped LUNs: 1]
| | o- mapped_lun0 .................................................................. [lun0 block/iscsi_shared_storage (rw)]
| o- luns .......................................................................................................... [LUNs: 1]
| | o- lun0 ......................................... [block/iscsi_shared_storage (/dev/vg_iscsi/lv_iscsi) (default_tg_pt_gp)]
| o- portals .................................................................................................... [Portals: 1]
| o- 0.0.0.0:3260 ..................................................................................................... [OK]
o- loopback ......................................................................................................... [Targets: 0]
/> saveconfig
Configuration saved to /etc/target/saveconfig.json
/> exit
Global pref auto_save_on_exit=true
Last 10 configs saved in /etc/target/backup/.
Configuration saved to /etc/target/saveconfig.json
Habilite y reinicie el servicio de Target.
[root@storage ~]# systemctl enable target
[root@storage ~]# systemctl restart target
Configure el firewall para permitir el tráfico iSCSI.
[root@storage ~]# firewall-cmd --permanent --add-port=3260/tcp
[root@storage ~]# firewall-cmd --reload
Descubrir almacenamiento compartido
En ambos nodos del clúster, descubra el objetivo con el siguiente comando.
iscsiadm -m discovery -t st -p 192.168.0.20
Output:
192.168.0.20:3260,1 qn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18
Ahora, inicie sesión en el almacenamiento de destino con el siguiente comando.
iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18 -p 192.168.0.20 -l
Output:
Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18, portal: 192.168.0.20,3260]
Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.storage.x8664:sn.eac9425e5e18, portal: 192.168.0.20,3260] successful.
Reinicie y habilite el servicio de iniciador.
systemctl restart iscsid
systemctl enable iscsid
Configurar nodos de clúster
Almacenamiento compartido
Vaya a todos los nodos de su clúster y verifique si el nuevo disco del servidor iSCSI está visible o no.
En mis nodos, /dev/sdb es el disco compartido del almacenamiento iSCSI.
fdisk -l | grep -i sd
Output:
Disk /dev/sda: 100 GiB, 107374182400 bytes, 209715200 sectors
/dev/sda1 * 2048 2099199 2097152 1G 83 Linux
/dev/sda2 2099200 209715199 207616000 99G 8e Linux LVM
Disk /dev/sdb: 10 GiB, 10733223936 bytes, 20963328 sectors
En cualquiera de sus nodos (Ej., nodo1), cree un sistema de archivos para que el servidor web Apache contenga los archivos del sitio web. Crearemos un sistema de archivos con LVM.
[root@node1 ~]# pvcreate /dev/sdb
[root@node1 ~]# vgcreate vg_apache /dev/sdb
[root@node1 ~]# lvcreate -n lv_apache -l 100%FREE vg_apache
[root@node1 ~]# mkfs.ext4 /dev/vg_apache/lv_apache
Ahora, vaya a otro nodo y ejecute los siguientes comandos para detectar el nuevo sistema de archivos.
[root@node2 ~]# pvscan
[root@node2 ~]# vgscan
[root@node2 ~]# lvscan
Finalmente, verifique el LVM que creamos en node1 está disponible para usted en otro nodo (Ej. nodo2) usando los siguientes comandos.
ls -al /dev/vg_apache/lv_apache
y
[root@node2 ~]# lvdisplay /dev/vg_apache/lv_apache
Output: _You should see /dev/vg_apache/lv_apache on node2.itzgeek.local_
--- Logical volume ---
LV Path /dev/vg_apache/lv_apache
LV Name lv_apache
VG Name vg_apache
LV UUID gXeaoB-VlN1-zWSW-2VnZ-RpmW-iDeC-kQOxZE
LV Write Access read/write
LV Creation host, time node1.itzgeek.local, 2020-03-30 08:08:17 -0400
LV Status NOT available
LV Size 9.96 GiB
Current LE 2551
Segments 1
Allocation inherit
Read ahead sectors auto
Si el sistema no muestra el volumen lógico o no se encuentra el archivo del dispositivo, considere reiniciar el segundo nodo. Entrada de host
Haga una entrada de host sobre cada nodo en todos los nodos. El clúster utilizará el nombre de host para comunicarse entre sí.
vi /etc/hosts
Las entradas de host serán algo como lo que se muestra a continuación.
192.168.0.11 node1.itzgeek.local node1
192.168.0.12 node2.itzgeek.local node2
Paquetes de instalación
Los paquetes de clúster están disponibles en el repositorio de alta disponibilidad. Por lo tanto, configure el repositorio de alta disponibilidad en su sistema.
CentOS 8
dnf config-manager --set-enabled HighAvailability
RHEL 8
Habilite la suscripción a Red Hat en RHEL 8 y luego habilite un repositorio de alta disponibilidad para descargar paquetes de clúster desde Red Hat.
subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms
Instale paquetes de clúster (marcapasos) con todos los agentes de cerca disponibles en todos los nodos usando el siguiente comando.
dnf install -y pcs fence-agents-all pcp-zeroconf
Agregue una regla de firewall para permitir que todas las aplicaciones de alta disponibilidad tengan una comunicación adecuada entre los nodos. Puede omitir este paso si el sistema no tiene activado el cortafuegos.
firewall-cmd --permanent --add-service=high-availability
firewall-cmd --add-service=high-availability
firewall-cmd --reload
Establezca una contraseña para el usuario hacluster.
Esta cuenta de usuario es una cuenta de administración de clúster. Le sugerimos que establezca la misma contraseña para todos los nodos.
passwd hacluster
Inicie el servicio de clúster y permita que se inicie automáticamente al iniciar el sistema.
systemctl start pcsd
systemctl enable pcsd
Recuerde:debe ejecutar los comandos anteriores en todos los nodos de su clúster.
Crear un clúster de alta disponibilidad
Autorice los nodos usando el siguiente comando. Ejecute el siguiente comando en cualquiera de los nodos para autorizar los nodos.
[root@node1 ~]# pcs host auth node1.itzgeek.local node2.itzgeek.local
Output:
Username: hacluster
Password: << Enter Password
node1.itzgeek.local: Authorized
node2.itzgeek.local: Authorized
Cree un clúster. Cambie el nombre del clúster itzgeek_cluster según sus requisitos.
[root@node1 ~]# pcs cluster setup itzgeek_cluster --start node1.itzgeek.local node2.itzgeek.local
Output:
No addresses specified for host 'node1.itzgeek.local', using 'node1.itzgeek.local'
No addresses specified for host 'node2.itzgeek.local', using 'node2.itzgeek.local'
Destroying cluster on hosts: 'node1.itzgeek.local', 'node2.itzgeek.local'...
node1.itzgeek.local: Successfully destroyed cluster
node2.itzgeek.local: Successfully destroyed cluster
Requesting remove 'pcsd settings' from 'node1.itzgeek.local', 'node2.itzgeek.local'
node1.itzgeek.local: successful removal of the file 'pcsd settings'
node2.itzgeek.local: successful removal of the file 'pcsd settings'
Sending 'corosync authkey', 'pacemaker authkey' to 'node1.itzgeek.local', 'node2.itzgeek.local'
node1.itzgeek.local: successful distribution of the file 'corosync authkey'
node1.itzgeek.local: successful distribution of the file 'pacemaker authkey'
node2.itzgeek.local: successful distribution of the file 'corosync authkey'
node2.itzgeek.local: successful distribution of the file 'pacemaker authkey'
Sending 'corosync.conf' to 'node1.itzgeek.local', 'node2.itzgeek.local'
node1.itzgeek.local: successful distribution of the file 'corosync.conf'
node2.itzgeek.local: successful distribution of the file 'corosync.conf'
Cluster has been successfully set up.
Starting cluster on hosts: 'node1.itzgeek.local', 'node2.itzgeek.local'...
Habilite el clúster para que se inicie al iniciar el sistema.
[root@node1 ~]# pcs cluster enable --all
Output:
node1.itzgeek.local: Cluster Enabled
node2.itzgeek.local: Cluster Enabled
Utilice el siguiente comando para obtener el estado del clúster.
[root@node1 ~]# pcs cluster status
Output:
Cluster Status:
Stack: corosync
Current DC: node1.itzgeek.local (version 2.0.2-3.el8_1.2-744a30d655) - partition with quorum
Last updated: Mon Mar 30 08:28:08 2020
Last change: Mon Mar 30 08:27:25 2020 by hacluster via crmd on node1.itzgeek.local
2 nodes configured
0 resources configured
PCSD Status:
node1.itzgeek.local: Online
node2.itzgeek.local: Online
Ejecute el siguiente comando para obtener información detallada sobre el clúster, que incluye sus recursos, el estado del marcapasos y los detalles de los nodos.
[root@node1 ~]# pcs status
Output:
Cluster name: itzgeek_cluster
WARNINGS:
No stonith devices and stonith-enabled is not false
Stack: corosync
Current DC: node1.itzgeek.local (version 2.0.2-3.el8_1.2-744a30d655) - partition with quorum
Last updated: Mon Mar 30 08:33:37 2020
Last change: Mon Mar 30 08:27:25 2020 by hacluster via crmd on node1.itzgeek.local
2 nodes configured
0 resources configured
Online: [ node1.itzgeek.local node2.itzgeek.local ]
No resources
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Dispositivos de esgrima
El dispositivo de vallado es un dispositivo de hardware que ayuda a desconectar el nodo problemático reiniciando el nodo/desconectando el acceso al almacenamiento compartido. Este clúster de demostración se ejecuta sobre VMware y no tiene ningún dispositivo de valla externo para configurar. Sin embargo, puede seguir esta guía para configurar un dispositivo de cercado.
Ya que no estamos usando cercas, desactívelas (STONITH). Debe deshabilitar el cercado para iniciar los recursos del clúster, pero no se recomienda deshabilitar STONITH en el entorno de producción.
[root@node1 ~]# pcs property set stonith-enabled=false
Recursos del clúster
Preparar recursos
Servidor Web Apache
Instale el servidor web Apache en ambos nodos.
dnf install -y httpd
Edite el archivo de configuración.
vi /etc/httpd/conf/httpd.conf
Agregue el contenido a continuación al final del archivo en ambos nodos del clúster.
<Location /server-status>
SetHandler server-status
Require local
</Location>
Edite la configuración logrotate del servidor web Apache para indicar que no use systemd ya que el recurso del clúster no usa systemd para recargar el servicio.
Cambie la siguiente línea.
DE:
/bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
PARA:
/usr/sbin/httpd -f /etc/httpd/conf/httpd.conf -c "PidFile /var/run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
Ahora, usaremos el almacenamiento compartido para almacenar el archivo de contenido web (HTML). Realice la siguiente operación en cualquiera de los nodos.
[root@node1 ~]# mount /dev/vg_apache/lv_apache /var/www/
[root@node1 ~]# mkdir /var/www/html
[root@node1 ~]# mkdir /var/www/cgi-bin
[root@node1 ~]# mkdir /var/www/error
[root@node1 ~]# restorecon -R /var/www
[root@node1 ~]# cat <<-END >/var/www/html/index.html
<html>
<body>Hello, Welcome!. This Page Is Served By Red Hat Hight Availability Cluster</body>
</html>
END
[root@node1 ~]# umount /var/www
Permita el servicio de Apache en el firewall en ambos nodos.
firewall-cmd --permanent --add-service=http
firewall-cmd --reload
Crear recursos
Cree un recurso de sistema de archivos para el servidor Apache. Utilice el almacenamiento procedente del servidor iSCSI.
[root@node1 ~]# pcs resource create httpd_fs Filesystem device="/dev/mapper/vg_apache-lv_apache" directory="/var/www" fstype="ext4" --group apache
Output:
Assumed agent name 'ocf:`heartbeat`:Filesystem' (deduced from 'Filesystem')
Cree un recurso de dirección IP. Esta dirección IP actuará como una dirección IP virtual para Apache, y los clientes usarán esta dirección IP para acceder al contenido web en lugar de la IP de un nodo individual.
[root@node1 ~]# pcs resource create httpd_vip IPaddr2 ip=192.168.0.100 cidr_netmask=24 --group apache
Output:
Assumed agent name 'ocf:`heartbeat`:IPaddr2' (deduced from 'IPaddr2')
Cree un recurso Apache para monitorear el estado del servidor Apache que moverá el recurso a otro nodo en caso de falla.
[root@node1 ~]# pcs resource create httpd_ser apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apache
Output:
Assumed agent name 'ocf:`heartbeat`:apache' (deduced from 'apache')
Verifique el estado del clúster.
[root@node1 ~]# pcs status
Output:
Cluster name: itzgeek_cluster
Stack: corosync
Current DC: node1.itzgeek.local (version 2.0.2-3.el8_1.2-744a30d655) - partition with quorum
Last updated: Mon Mar 30 09:02:07 2020
Last change: Mon Mar 30 09:01:46 2020 by root via cibadmin on node1.itzgeek.local
2 nodes configured
3 resources configured
Online: [ node1.itzgeek.local node2.itzgeek.local ]
Full list of resources:
Resource Group: apache
httpd_fs (ocf:💓Filesystem): Started node1.itzgeek.local
httpd_vip (ocf:💓IPaddr2): Started node1.itzgeek.local
httpd_ser (ocf:💓apache): Started node1.itzgeek.local
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
Verificar clúster de alta disponibilidad
Una vez que el clúster esté en funcionamiento, apunte un navegador web a la dirección IP virtual de Apache. Debería obtener una página web como la siguiente.
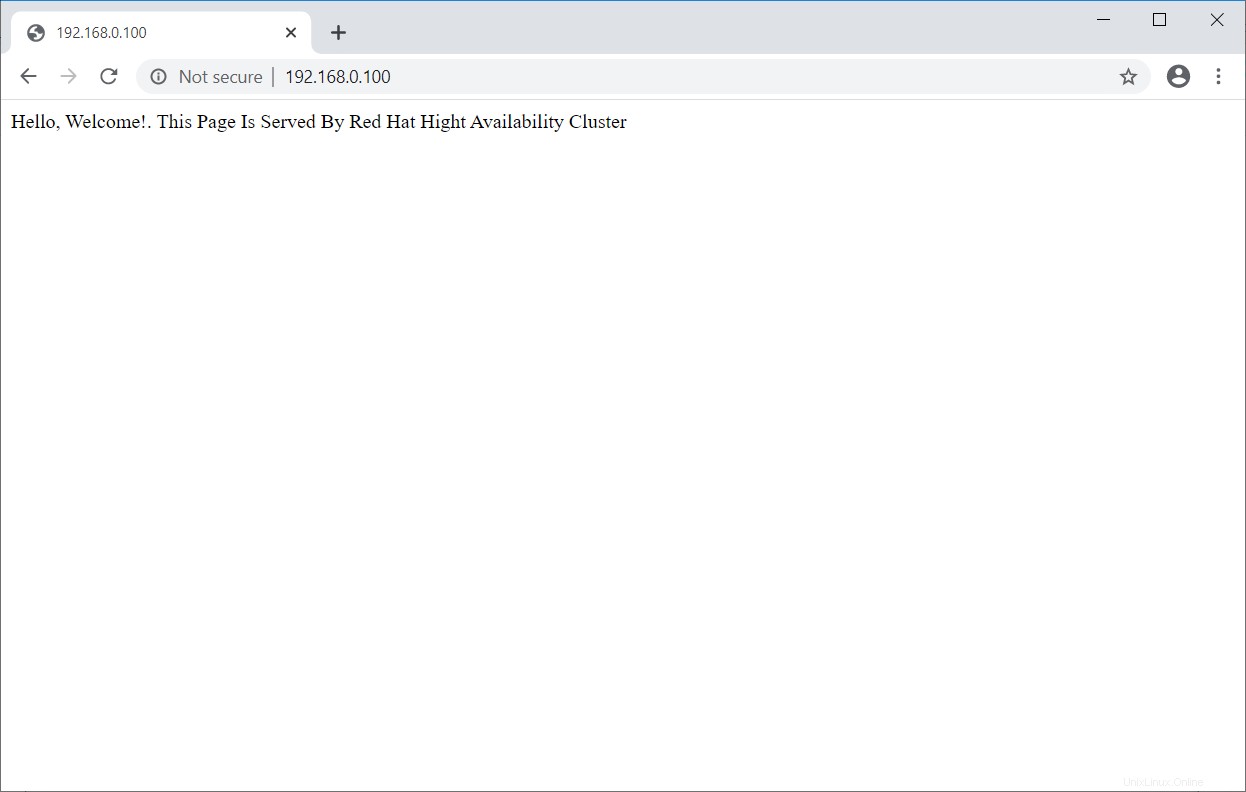
Prueba de clúster de alta disponibilidad
Verifiquemos la conmutación por error de los recursos poniendo el nodo activo (donde se ejecutan todos los recursos) en modo de espera.
[root@node1 ~]# pcs node standby node1.itzgeek.local
Comandos de clúster importantes
Listar los recursos del clúster:
pcs resource status
Reiniciar recurso de clúster:
pcs resource restart <resource_name>
Mover el recurso fuera de un nodo:
pcs resource move <resource_group> <destination_node_name>
Poner el clúster en mantenimiento:
pcs property set maintenance-mode=true
Quitar el clúster del mantenimiento:
pcs property set maintenance-mode=false
Inicie el nodo del clúster:
pcs cluster start <node_name>
Detener el nodo del clúster:
pcs cluster stop <node_name>
Clúster de inicio:
pcs cluster start --all
Detener grupo:
pcs cluster stop --all
Destruir clúster:
pcs cluster destroy <cluster_name>
Interfaz de usuario web del clúster
La interfaz de usuario web de pcsd lo ayuda a crear, configurar y administrar clústeres de Pacemaker.
Se podrá acceder a la interfaz web una vez que inicie el servicio pcsd en el nodo y esté disponible en el número de puerto 2224.
https://node_name:2224
Inicie sesión con el usuario administrativo del clúster hacluster y su contraseña.
Dado que ya tenemos un grupo, haga clic en Agregar existente para agregar el grupo de Pacemaker existente. En caso de que desee configurar un nuevo clúster, puede leer la documentación oficial.
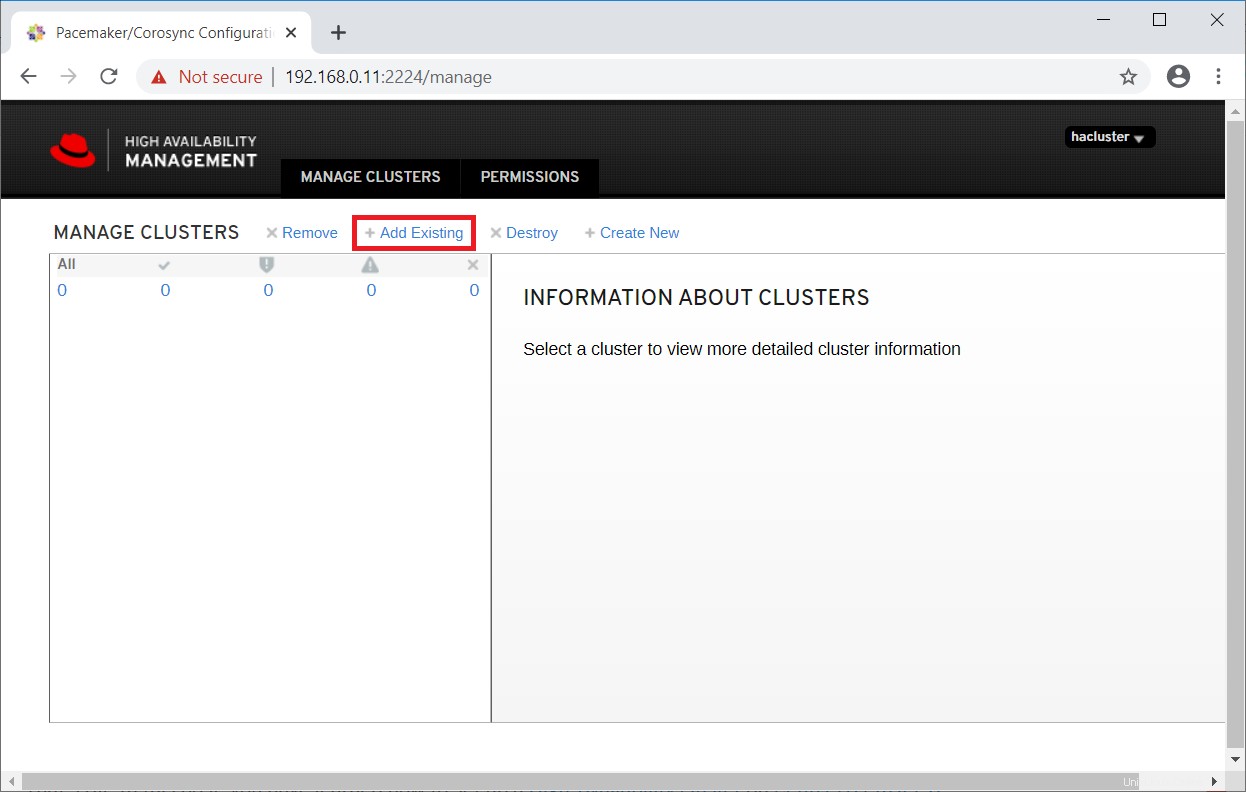
Ingrese cualquiera de un nodo de clúster para detectar un clúster existente.
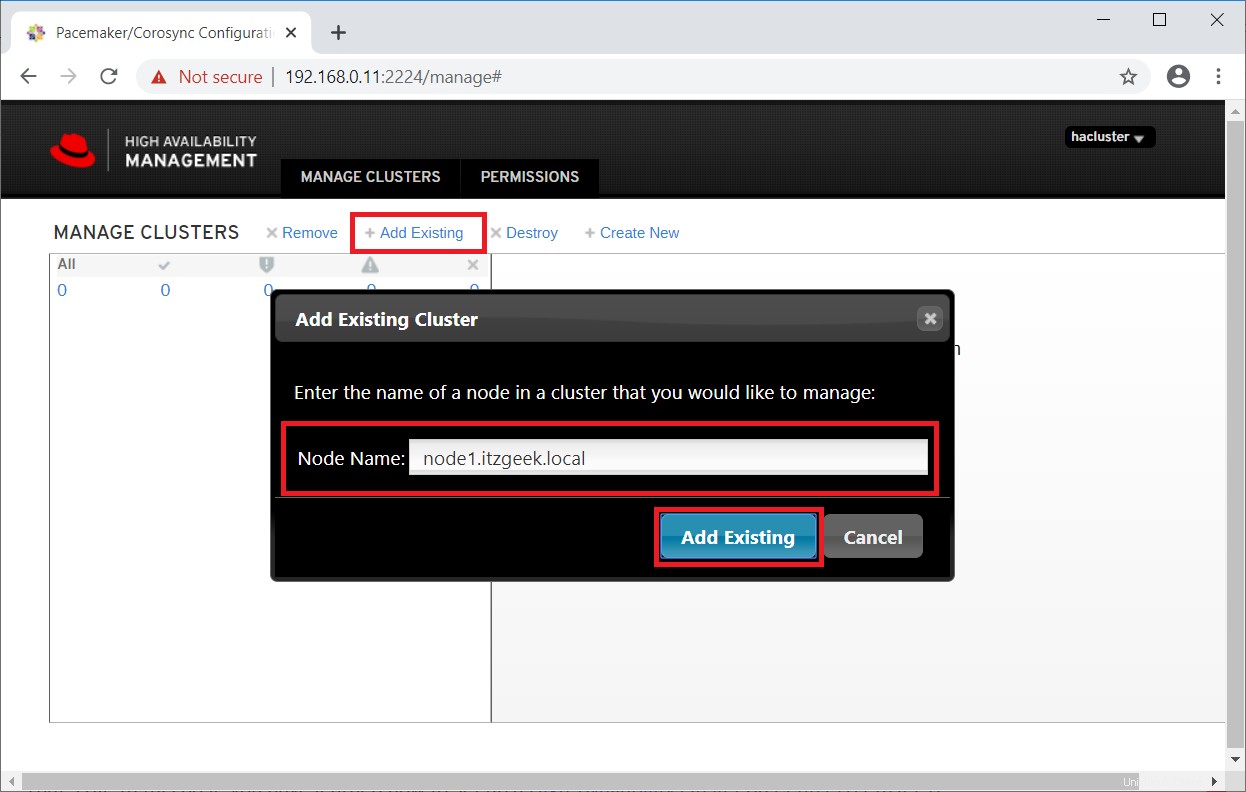
En uno o dos minutos, verá su clúster existente en la interfaz de usuario web.
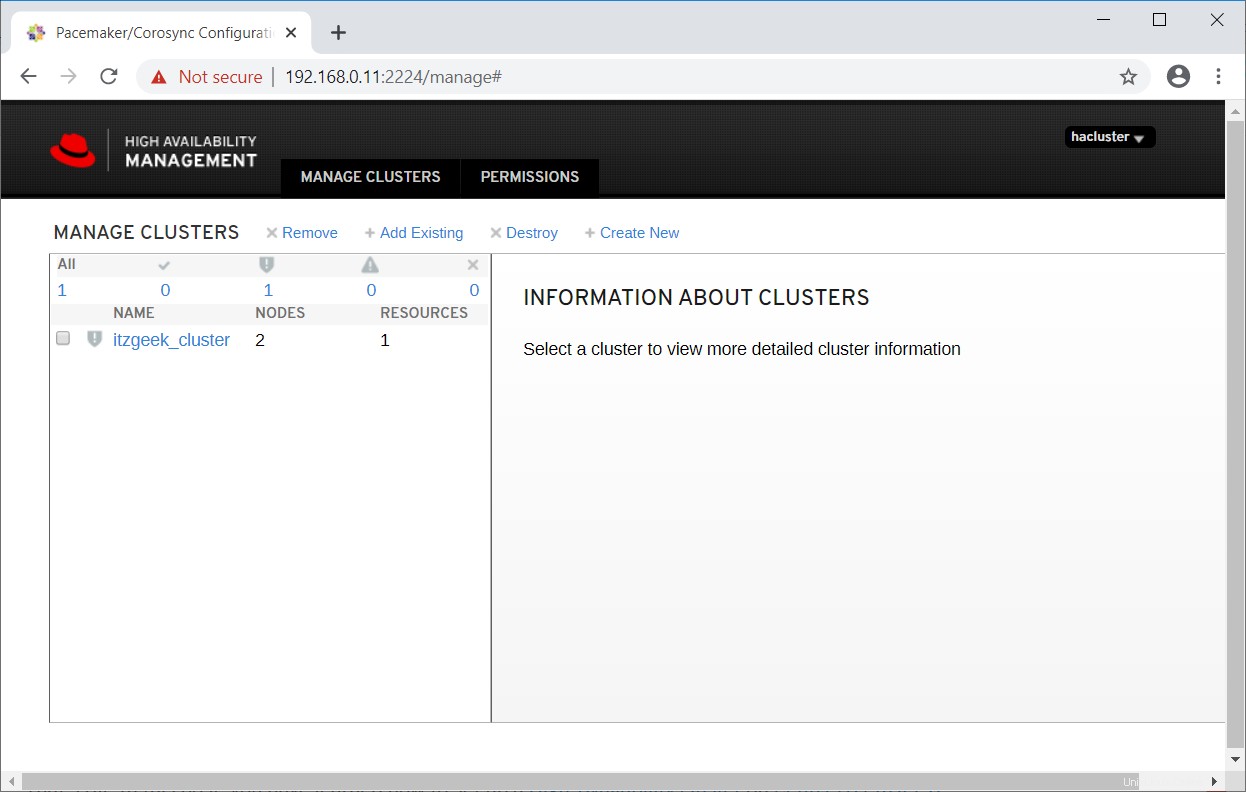
Seleccione el clúster para saber más sobre la información del clúster.
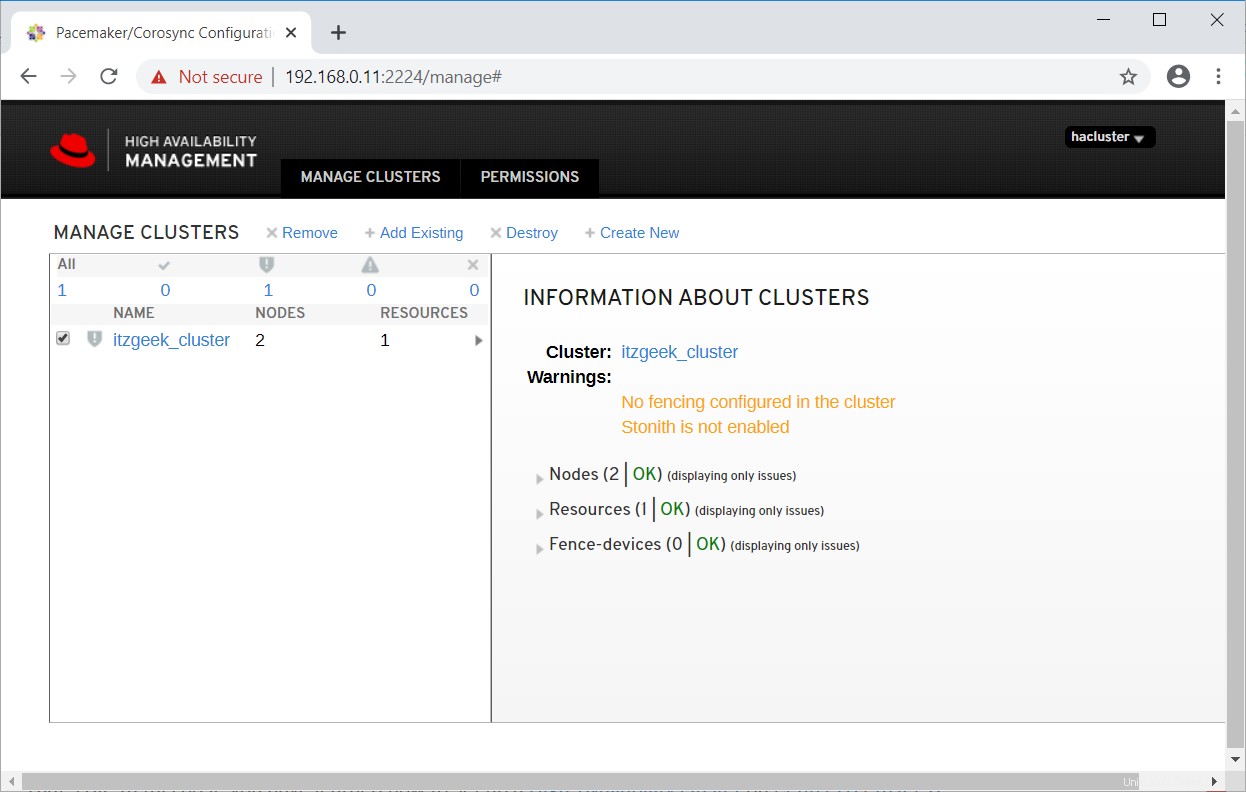
Haga clic en el nombre del clúster para ver los detalles del nodo.
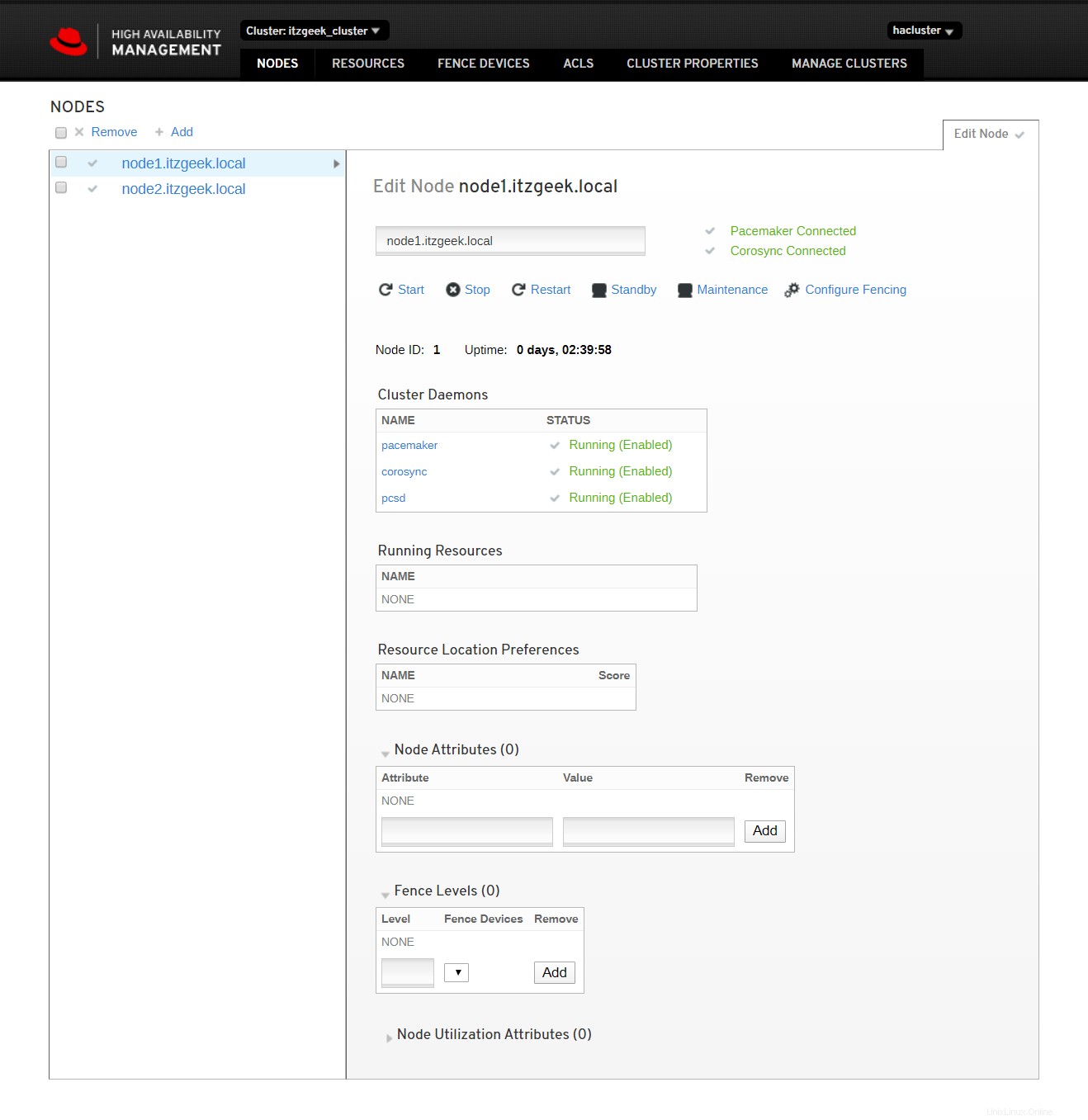
Haga clic en recursos del clúster para ver la lista de recursos y sus detalles.
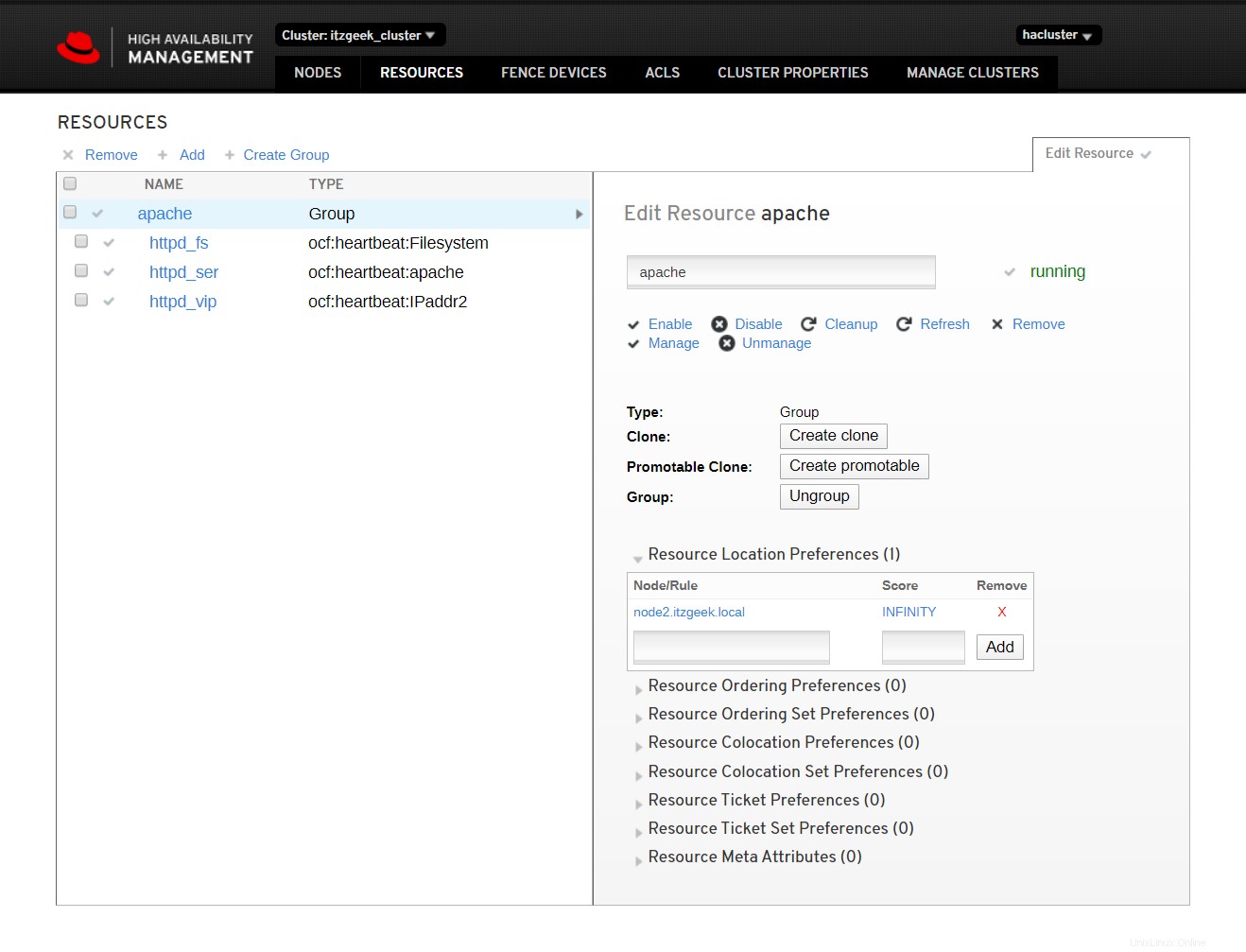
Referencia :Documentación de Red Hat.
Conclusión
Eso es todo. En esta publicación, ha aprendido a configurar un clúster de alta disponibilidad en CentOS 8/RHEL 8.