
En este tutorial, le mostraremos cómo instalar Apache Hadoop en CentOS 7. Para quienes no lo sabían, Apache Hadoop es un marco de software de código abierto escrito en Java para almacenamiento distribuido y procesos de distribución, maneja conjuntos de datos de gran tamaño distribuyéndolos a través de clústeres de computadoras. -servicio disponible en la parte superior de un grupo de computadoras, cada una de las cuales puede ser propensa a fallas.
Este artículo asume que tiene al menos conocimientos básicos de Linux, sabe cómo usar el shell y, lo que es más importante, aloja su sitio en su propio VPS. La instalación es bastante simple. mostrarle la instalación paso a paso de Apache Hadoop en CentOS 7.
Requisitos previos
- Un servidor que ejecute uno de los siguientes sistemas operativos:CentOS 7.
- Se recomienda que utilice una instalación de sistema operativo nueva para evitar posibles problemas.
- Acceso SSH al servidor (o simplemente abra Terminal si está en una computadora de escritorio).
- Un
non-root sudo usero acceder alroot user. Recomendamos actuar como unnon-root sudo user, sin embargo, puede dañar su sistema si no tiene cuidado al actuar como root.
Instalar Apache Hadoop en CentOS 7
Paso 1. Instalar Java.
Dado que Hadoop se basa en Java, asegúrese de tener Java JDK instalado en el sistema. Si no tiene Java instalado en su sistema, use el siguiente enlace para instalarlo primero.
- Instalar Java JDK 8 en CentOS 7
root@idroot.us ~# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
Paso 2. Instale Apache Hadoop.
Se recomienda crear un usuario normal para configurar apache Hadoop, cree un usuario usando el siguiente comando:
useradd hadoop passwd hadoop
Después de crear un usuario, también es necesario configurar ssh basado en clave para su propia cuenta. Para hacer esto, utilice los siguientes comandos:
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Descargue la última versión estable de Apache Hadoop, al momento de escribir este artículo es la versión 2.7.0:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Paso 3. Configurar Apache Hadoop.
Configure las variables de entorno utilizadas por Hadoop. Edite el archivo ~/.bashrc y agregue los siguientes valores al final del archivo:
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Aplicar variables ambientales a la sesión actualmente en ejecución:
source ~/.bashrc
Ahora edite $HADOOP_HOME/etc/hadoop/hadoop-env.sh archivo y establezca la variable de entorno JAVA_HOME:
export JAVA_HOME=/usr/jdk1.8.0_45/
Hadoop tiene muchos archivos de configuración, que deben configurarse según los requisitos de su infraestructura de Hadoop. Comencemos con la configuración básica de un clúster de nodo único de Hadoop:
cd $HADOOP_HOME/etc/hadoop
Editar core-site.xml :
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Editar hdfs-site.xml :
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value> </property> </configuration>
Editar mapred-site.xml :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Editar yarn-site.xml :
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Ahora formatee namenode usando el siguiente comando, no olvide verificar el directorio de almacenamiento:
hdfs namenode -format
Inicie todos los servicios de Hadoop usando el siguiente comando:
cd $HADOOP_HOME/sbin/ start-dfs.sh start-yarn.sh
Para verificar si todos los servicios se iniciaron correctamente, use 'jps ‘ comando:
jps
Paso 4. Acceso a Apache Hadoop.
Apache Hadoop estará disponible en el puerto HTTP 8088 y el puerto 50070 de forma predeterminada. Abra su navegador favorito y vaya a http://your-domain.com:50070 o http://server-ip:50070 . Si está utilizando un firewall, abra los puertos 8088 y 50070 para habilitar el acceso al panel de control.
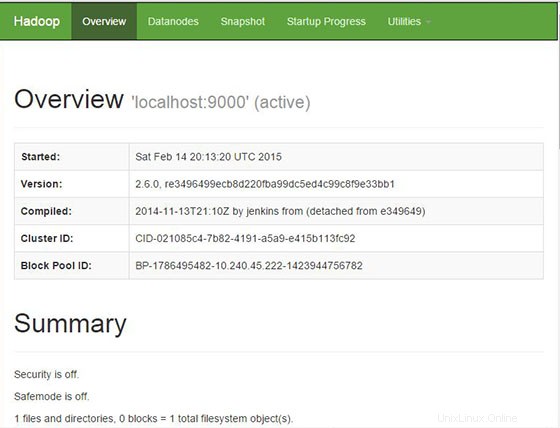
Ahora acceda al puerto 8088 para obtener información sobre el clúster y todas las aplicaciones:
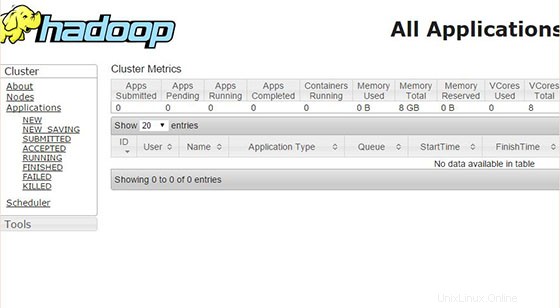
¡Felicitaciones! Ha instalado Apache Hadoop correctamente. Gracias por usar este tutorial para instalar Apache Hadoop en el sistema CentOS 7. Para obtener ayuda adicional o información útil, le recomendamos que consulte el sitio web oficial de Apache Hadoop.