Cuando trabajaba en un rol centrado en la red, uno de los mayores desafíos siempre fue cerrar la brecha entre la red y la ingeniería de sistemas. Los administradores de sistemas, que carecen de visibilidad en la red, a menudo culpan a la red por interrupciones o problemas extraños. Los administradores de red, incapaces de controlar los servidores y fatigados por la actitud de "culpable hasta que se demuestre su inocencia" hacia la red, a menudo culpaban a los puntos finales de la red.
Por supuesto, la culpa no resuelve los problemas. Tomarse el tiempo para comprender los conceptos básicos del dominio de alguien puede contribuir en gran medida a mejorar las relaciones con otros equipos y guiar las resoluciones más rápidas de los problemas. Este hecho es especialmente cierto para los administradores de sistemas. Al tener una comprensión básica de la resolución de problemas de red, podemos brindar evidencia más sólida a nuestros colegas de redes cuando sospechamos que la red puede tener fallas. Del mismo modo, a menudo podemos ahorrar tiempo al realizar una solución de problemas inicial por nuestra cuenta.
En este artículo, cubriremos los aspectos básicos de la resolución de problemas de red a través de la línea de comandos de Linux.
Una revisión rápida del modelo TCP/IP
Primero, tomemos un momento para revisar los fundamentos del modelo de red TCP/IP. Si bien la mayoría de las personas usa el modelo de interconexión de sistemas abiertos (OSI) para analizar la teoría de redes, el modelo TCP/IP representa con mayor precisión el conjunto de protocolos que se implementan en las redes modernas.
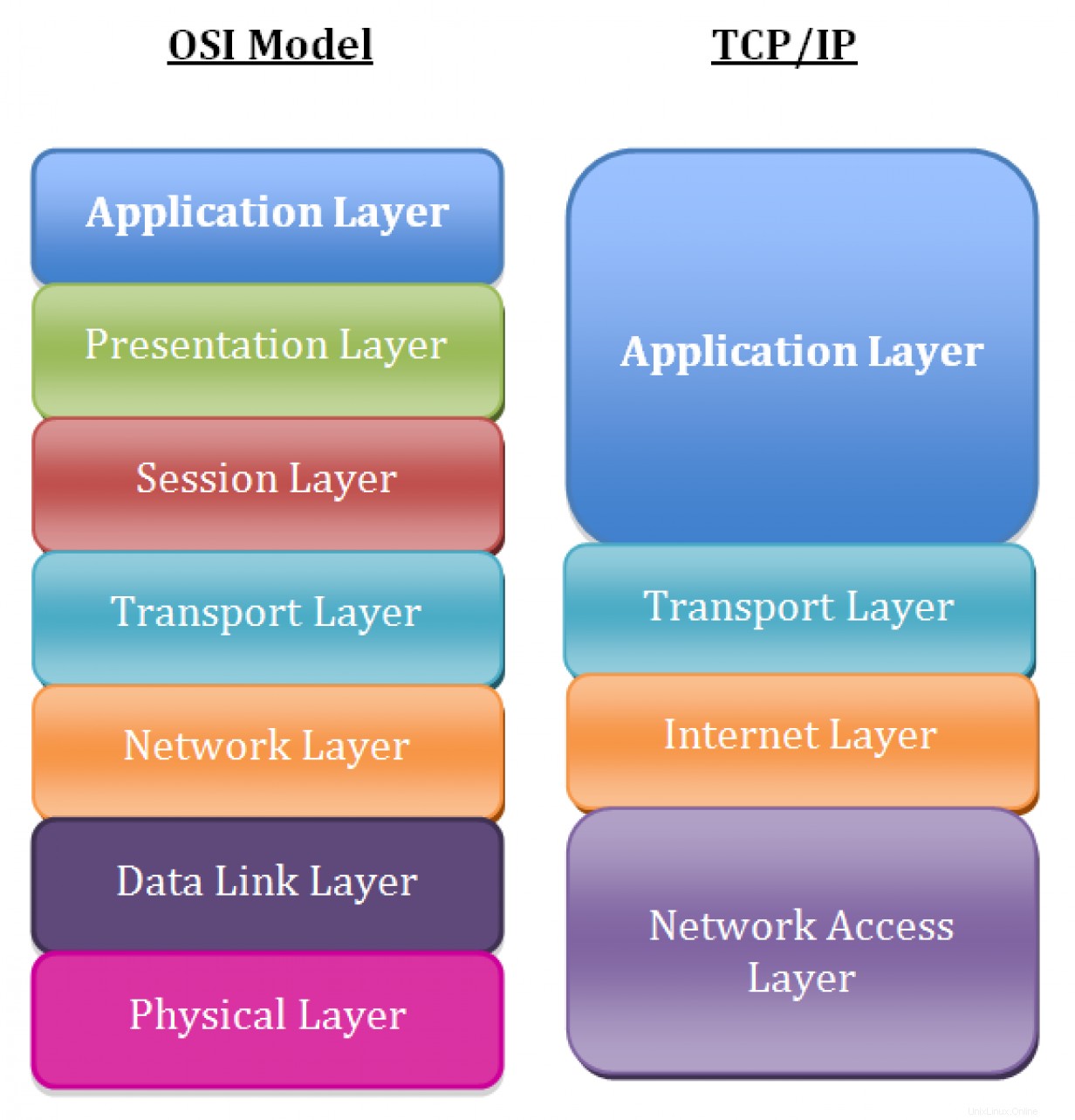
Las capas en el modelo de red TCP/IP, en orden, incluyen:
- Capa 5: Aplicación
- Capa 4: Transporte
- Capa 3: Red/Internet
- Capa 2: Enlace de datos
- Capa 1: Físico
Asumiré que está familiarizado con este modelo y procederé discutiendo formas de solucionar problemas en las capas 1 a 4 de la pila. Dónde comenzar la resolución de problemas depende de la situación. Por ejemplo, si puede conectarse mediante SSH a un servidor, pero el servidor no puede conectarse a una base de datos MySQL, es poco probable que el problema sea la capa física o de enlace de datos en el servidor local. En general, es una buena idea avanzar en la pila. Comience con la aplicación y luego resuelva gradualmente cada capa inferior hasta que haya aislado el problema.
Con ese trasfondo fuera del camino, saltemos a la línea de comando y comencemos a solucionar problemas.
Capa 1:La capa física
A menudo damos por sentada la capa física ("¿se aseguró de que el cable esté enchufado?"), pero podemos solucionar fácilmente los problemas de la capa física desde la línea de comandos de Linux. Eso es si tiene conectividad de consola con el host, lo que podría no ser el caso para algunos sistemas remotos.
Comencemos con la pregunta más básica:¿Está activa nuestra interfaz física? El ip link show comando nos dice:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
Observe la indicación de ABAJO en la salida anterior para la interfaz eth0. Este resultado significa que la capa 1 no aparece. Podríamos intentar solucionar problemas revisando el cableado o el extremo remoto de la conexión (por ejemplo, el interruptor) en busca de problemas.
Sin embargo, antes de comenzar a verificar los cables, es una buena idea asegurarse de que la interfaz no esté deshabilitada. Emitir un comando para abrir la interfaz puede descartar este problema:
# ip link set eth0 up
La salida de ip link show puede ser difícil de analizar de un vistazo rápido. Afortunadamente, el -br switch imprime esta salida en un formato de tabla mucho más legible:
# ip -br link show
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
eth0 UP 52:54:00:82:d6:6e <BROADCAST,MULTICAST,UP,LOWER_UP>
Parece que ip link set eth0 up hizo el truco, y eth0 está de vuelta en el negocio.
Estos comandos son excelentes para solucionar problemas físicos obvios, pero ¿qué sucede con los problemas más insidiosos? Las interfaces pueden negociar a la velocidad incorrecta, o las colisiones y los problemas de la capa física pueden causar la pérdida o corrupción de paquetes que resultan en retransmisiones costosas. ¿Cómo empezamos a solucionar esos problemas?
Podemos usar el -s marca con la ip Comando para imprimir estadísticas adicionales sobre una interfaz. El siguiente resultado muestra una interfaz mayormente limpia, con solo unos pocos paquetes de recepción descartados y sin otros signos de problemas de la capa física:
# ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
34107919 5808 0 6 0 0
TX: bytes packets errors dropped carrier collsns
434573 4487 0 0 0 0
Para una resolución de problemas de capa 1 más avanzada, la ethtool La utilidad es una excelente opción. Un caso de uso particularmente bueno para este comando es verificar si una interfaz ha negociado la velocidad correcta. Una interfaz que ha negociado la velocidad incorrecta (p. ej., una interfaz de 10 Gbps que solo informa velocidades de 1 Gbps) puede ser un indicador de un problema de hardware/cableado, o una mala configuración de negociación en un lado del enlace (p. ej., un puerto de conmutador mal configurado). /P>
Nuestros resultados podrían verse así:
# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: on (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
Tenga en cuenta que el resultado anterior muestra un enlace que ha negociado correctamente a una velocidad de 1000 Mbps y dúplex completo.
Capa 2:La capa de enlace de datos
La capa de enlace de datos es responsable de local conectividad de red; esencialmente, la comunicación de marcos entre hosts en el mismo dominio de Capa 2 (comúnmente llamado red de área local). El protocolo de capa 2 más relevante para la mayoría de los administradores de sistemas es el Protocolo de resolución de direcciones (ARP), que asigna direcciones IP de capa 3 a direcciones MAC Ethernet de capa 2. Cuando un host intenta comunicarse con otro host en su red local (como la puerta de enlace predeterminada), es probable que tenga la dirección IP del otro host, pero no conoce la dirección MAC del otro host. ARP resuelve este problema y descubre la dirección MAC por nosotros.
Un problema común que puede encontrar es una entrada ARP que no se completa, particularmente para la puerta de enlace predeterminada de su host. Si su host local no puede resolver con éxito la dirección MAC de Capa 2 de su puerta de enlace, entonces no podrá enviar ningún tráfico a redes remotas. Este problema puede deberse a que se configuró una dirección IP incorrecta para la puerta de enlace o puede deberse a otro problema, como un puerto de conmutador mal configurado.
Podemos verificar las entradas en nuestra tabla ARP con el ip neighbor comando:
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
Tenga en cuenta que la dirección MAC de la puerta de enlace está completa (hablaremos más sobre cómo encontrar su puerta de enlace en la siguiente sección). Si hubiera un problema con ARP, veríamos una falla de resolución:
# ip neighbor show
192.168.122.1 dev eth0 FAILED
Otro uso común del ip neighbor El comando implica manipular la tabla ARP. Imagine que su equipo de redes acaba de reemplazar el enrutador ascendente (que es la puerta de enlace predeterminada de su servidor). La dirección MAC también puede haber cambiado, ya que las direcciones MAC son direcciones de hardware que se asignan en la fábrica.
Linux almacena en caché la entrada ARP durante un período de tiempo, por lo que es posible que no pueda enviar tráfico a su puerta de enlace predeterminada hasta que se agote el tiempo de espera de la entrada ARP para su puerta de enlace. Para sistemas muy importantes, este resultado no es deseable. Afortunadamente, puede eliminar manualmente una entrada ARP, lo que forzará un nuevo proceso de descubrimiento ARP:
# ip neighbor show
192.168.122.170 dev eth0 lladdr 52:54:00:04:2c:5d REACHABLE
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
# ip neighbor delete 192.168.122.170 dev eth0
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
En el ejemplo anterior, vemos una entrada ARP poblada para 192.168.122.70 en eth0. Luego eliminamos la entrada ARP y podemos ver que se ha eliminado de la tabla.
Capa 3:La capa de red/internet
La capa 3 implica trabajar con direcciones IP, que deberían ser familiares para cualquier administrador de sistemas. El direccionamiento IP proporciona a los hosts una forma de llegar a otros hosts que están fuera de su red local (aunque a menudo también los usamos en redes locales). Uno de los primeros pasos para solucionar problemas es verificar la dirección IP local de una máquina, lo que se puede hacer con la ip address comando, nuevamente haciendo uso de -br bandera para simplificar la salida:
# ip -br address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.135/24 fe80::184e:a34d:1d37:441a/64 fe80::c52f:d96e:a4a2:743/64
Podemos ver que nuestra interfaz eth0 tiene una dirección IPv4 de 192.168.122.135. Si no tuviéramos una dirección IP, nos gustaría solucionar ese problema. La falta de una dirección IP puede deberse a una mala configuración local, como un archivo de configuración de interfaz de red incorrecto, o puede deberse a problemas con DHCP.
La herramienta de primera línea más común que la mayoría de los administradores de sistemas utilizan para solucionar problemas de la capa 3 es el ping utilidad. Ping envía un paquete de solicitud de eco ICMP a un host remoto y espera una respuesta de eco ICMP a cambio. Si tiene problemas de conectividad con un host remoto, ping es una utilidad común para comenzar a solucionar problemas. Ejecutar un simple ping desde la línea de comandos envía ecos ICMP al host remoto de forma indefinida; necesitará CTRL+C para finalizar el ping o pasar -c <num pings> bandera, así:
# ping www.google.com
PING www.google.com (172.217.165.4) 56(84) bytes of data.
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=1 ttl=54 time=12.5 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=2 ttl=54 time=12.6 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=3 ttl=54 time=12.5 ms
^C
--- www.google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 12.527/12.567/12.615/0.036 ms
Tenga en cuenta que cada ping incluye la cantidad de tiempo que tomó recibir una respuesta. Mientras ping puede ser una manera fácil de saber si un host está vivo y respondiendo, de ninguna manera es definitivo. Muchos operadores de red bloquean los paquetes ICMP como medida de seguridad, aunque muchos otros no están de acuerdo con esta práctica. Otro problema común es confiar en el campo de tiempo como un indicador preciso de la latencia de la red. Los paquetes ICMP pueden tener una velocidad limitada por el equipo de red intermedio, y no se debe confiar en ellos para proporcionar representaciones reales de la latencia de la aplicación.
La siguiente herramienta en el cinturón de herramientas de resolución de problemas de la Capa 3 es traceroute dominio. Traceroute aprovecha el campo Time to Live (TTL) en los paquetes IP para determinar la ruta que toma el tráfico hasta su destino. Traceroute enviará un paquete a la vez, comenzando con un TTL de uno. Dado que el paquete caduca en tránsito, el enrutador ascendente devuelve un paquete ICMP Time-to-Live Exceeded. Traceroute luego incrementa el TTL para determinar el siguiente salto. El resultado resultante es una lista de enrutadores intermedios que atravesó un paquete en su camino hacia el destino:
# traceroute www.google.com
traceroute to www.google.com (172.217.10.36), 30 hops max, 60 byte packets
1 acritelli-laptop (192.168.122.1) 0.103 ms 0.057 ms 0.027 ms
2 192.168.1.1 (192.168.1.1) 5.302 ms 8.024 ms 8.021 ms
3 142.254.218.133 (142.254.218.133) 20.754 ms 25.862 ms 25.826 ms
4 agg58.rochnyei01h.northeast.rr.com (24.58.233.117) 35.770 ms 35.772 ms 35.754 ms
5 agg62.hnrtnyaf02r.northeast.rr.com (24.58.52.46) 25.983 ms 32.833 ms 32.864 ms
6 be28.albynyyf01r.northeast.rr.com (24.58.32.70) 43.963 ms 43.067 ms 43.084 ms
7 bu-ether16.nycmny837aw-bcr00.tbone.rr.com (66.109.6.74) 47.566 ms 32.169 ms 32.995 ms
8 0.ae1.pr0.nyc20.tbone.rr.com (66.109.6.163) 27.277 ms * 0.ae4.pr0.nyc20.tbone.rr.com (66.109.1.35) 32.270 ms
9 ix-ae-6-0.tcore1.n75-new-york.as6453.net (66.110.96.53) 32.224 ms ix-ae-10-0.tcore1.n75-new-york.as6453.net (66.110.96.13) 36.775 ms 36.701 ms
10 72.14.195.232 (72.14.195.232) 32.041 ms 31.935 ms 31.843 ms
11 * * *
12 216.239.62.20 (216.239.62.20) 70.011 ms 172.253.69.220 (172.253.69.220) 83.370 ms lga34s13-in-f4.1e100.net (172.217.10.36) 38.067 ms
Traceroute parece una gran herramienta, pero es importante comprender sus limitaciones. Al igual que con ICMP, los enrutadores intermedios pueden filtrar los paquetes que traceroute depende, como el mensaje ICMP Time-to-Live Exceeded. Pero lo que es más importante, la ruta que toma el tráfico hacia y desde un destino no es necesariamente simétrica y no siempre es la misma. Traceroute puede inducirlo a pensar erróneamente que su tráfico toma un buen camino lineal hacia y desde su destino. Sin embargo, esta situación rara vez se da. El tráfico puede seguir una ruta de retorno diferente y las rutas pueden cambiar dinámicamente por muchas razones. Mientras que traceroute puede proporcionar representaciones de ruta precisas en redes corporativas pequeñas, a menudo no es precisa cuando se intenta realizar un seguimiento en redes grandes o en Internet.
Otro problema común con el que probablemente se encontrará es la falta de una puerta de enlace ascendente para una ruta en particular o la falta de una ruta predeterminada. Cuando un paquete IP se envía a una red diferente, debe enviarse a una puerta de enlace para su posterior procesamiento. La puerta de enlace debe saber cómo enrutar el paquete a su destino final. La lista de puertas de enlace para diferentes rutas se almacena en una tabla de enrutamiento , que se puede inspeccionar y manipular mediante ip route comandos.
Podemos imprimir la tabla de enrutamiento usando ip route show comando:
# ip route show
default via 192.168.122.1 dev eth0 proto dhcp metric 100
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.135 metric 100
Las topologías simples a menudo solo tienen una puerta de enlace predeterminada configurada, representada por la entrada "predeterminada" en la parte superior de la tabla. Una puerta de enlace predeterminada faltante o incorrecta es un problema común.
Si nuestra topología es más compleja y necesitamos diferentes rutas para diferentes redes, podemos verificar la ruta para un prefijo específico:
# ip route show 10.0.0.0/8
10.0.0.0/8 via 192.168.122.200 dev eth0
En el ejemplo anterior, enviamos todo el tráfico destinado a la red 10.0.0.0/8 a una puerta de enlace diferente (192.168.122.200).
Si bien no es un protocolo de capa 3, vale la pena mencionar el DNS cuando hablamos de direcciones IP. Entre otras cosas, el Sistema de nombres de dominio (DNS) traduce las direcciones IP en nombres legibles por humanos, como www.redhat.com . Los problemas de DNS son extremadamente comunes y, a veces, son difíciles de solucionar. Se han escrito muchos libros y guías en línea sobre DNS, pero aquí nos centraremos en lo básico.
Una señal reveladora de problemas de DNS es la capacidad de conectarse a un host remoto por dirección IP pero no por su nombre de host. Realizando un nslookup rápido en el nombre de host puede decirnos bastante (nslookup es parte de bind-utils paquete en sistemas basados en Red Hat Enterprise Linux):
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.3.100
El resultado anterior muestra el servidor en el que se realizó la búsqueda en 192.168.122.1 y la dirección IP resultante fue 172.217.3.100.
Si realiza un nslookup para un host pero ping o traceroute intente usar una dirección IP diferente, probablemente esté viendo un problema de entrada de archivo de host. Como resultado, inspeccione el archivo host en busca de problemas:
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.12.132
# ping -c 1 www.google.com
PING www.google.com (1.2.3.4) 56(84) bytes of data.
^C
--- www.google.com ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
1.2.3.4 www.google.com
Tenga en cuenta que en el ejemplo anterior, la dirección de www.google.com resuelto al 172.217.12.132. Sin embargo, cuando intentamos hacer ping al host, el tráfico se enviaba a 1.2.3.4. Echando un vistazo a /etc/hosts file, podemos ver una anulación que alguien debe haber agregado por descuido. Los problemas de anulación de archivos host son extremadamente común, especialmente si trabaja con desarrolladores de aplicaciones que a menudo necesitan realizar estas modificaciones para probar su código durante el desarrollo.
Capa 4:La capa de transporte
La capa de transporte consta de los protocolos TCP y UDP, siendo TCP un protocolo orientado a la conexión y UDP sin conexión. Las aplicaciones escuchan en sockets , que constan de una dirección IP y un puerto. El kernel dirigirá el tráfico destinado a una dirección IP en un puerto específico a la aplicación de escucha. Una discusión completa de estos protocolos está más allá del alcance de este artículo, por lo que nos centraremos en cómo solucionar los problemas de conectividad en estas capas.
Lo primero que puede querer hacer es ver qué puertos están escuchando en el servidor local. El resultado puede ser útil si no puede conectarse a un servicio en particular en la máquina, como un servidor web o SSH. Otro problema común ocurre cuando un demonio o servicio no se inicia debido a que algo más está escuchando en un puerto. El ss El comando es invaluable para realizar este tipo de acciones:
# ss -tunlp4
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:68 *:* users:(("dhclient",pid=3167,fd=6))
udp UNCONN 0 0 127.0.0.1:323 *:* users:(("chronyd",pid=2821,fd=1))
tcp LISTEN 0 128 *:22 *:* users:(("sshd",pid=3366,fd=3))
tcp LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=3600,fd=13))
Analicemos estas banderas:
- -t - Mostrar puertos TCP.
- -u - Mostrar puertos UDP.
- -n - No intente resolver los nombres de host.
- -l - Mostrar solo puertos de escucha.
- -p - Muestra los procesos que están usando un socket en particular.
-4 - Mostrar solo sockets IPv4.
Echando un vistazo a la salida, podemos ver varios servicios de escucha. El sshd la aplicación está escuchando en el puerto 22 en todas las direcciones IP, indicado por *:22 salida.
El ss El comando es una herramienta poderosa, y una revisión de su breve página de manual puede ayudarlo a ubicar indicadores y opciones para encontrar lo que esté buscando.
Otro escenario común de solución de problemas implica la conectividad remota. Imagine que su máquina local no puede conectarse a un puerto remoto, como MySQL en el puerto 3306. Una herramienta poco común pero comúnmente instalada puede ser su amiga cuando solucione este tipo de problemas:telnet . El telnet El comando intenta establecer una conexión TCP con cualquier host y puerto que le proporcione. Esta característica es perfecta para probar la conectividad TCP remota:
# telnet database.example.com 3306
Trying 192.168.1.10...
^C
En el resultado anterior, telnet cuelga hasta que lo matemos. Este resultado nos dice que no podemos acceder al puerto 3306 en la máquina remota. Tal vez la aplicación no esté escuchando, y necesitamos emplear los pasos de solución de problemas anteriores usando ss en el host remoto, si tenemos acceso. Otra posibilidad es un host o firewall intermedio que filtre el tráfico. Es posible que debamos trabajar con el equipo de red para verificar la conectividad de la capa 4 en la ruta.
Telnet funciona bien para TCP, pero ¿qué pasa con UDP? El netcat La herramienta proporciona una forma sencilla de comprobar un puerto UDP remoto:
# nc 192.168.122.1 -u 80
test
Ncat: Connection refused.
El netcat La utilidad se puede usar para muchas otras cosas, incluida la prueba de conectividad TCP. Tenga en cuenta que netcat Es posible que no esté instalado en su sistema y, a menudo, se considera un riesgo de seguridad dejarlo tirado. Es posible que desee considerar desinstalarlo cuando haya terminado de solucionar el problema.
Los ejemplos anteriores discutieron utilidades simples y comunes. Sin embargo, una herramienta mucho más poderosa es nmap . Se han dedicado libros enteros a nmap funcionalidad, por lo que no la cubriremos en este artículo para principiantes, pero debe saber algunas de las cosas que es capaz de hacer:
- Escaneo de puertos TCP y UDP en máquinas remotas.
- Huellas digitales del sistema operativo.
- Determinar si los puertos remotos están cerrados o simplemente filtrados.
Resumiendo
Cubrimos una gran cantidad de temas de introducción a la red en este artículo, avanzando en la pila de la red desde cables y conmutadores hasta direcciones IP y puertos. Las herramientas discutidas aquí deberían brindarle un buen punto de partida para solucionar problemas básicos de conectividad de red, y deberían resultar útiles cuando intente proporcionar la mayor cantidad de detalles posible a su equipo de red.
A medida que avanza en su viaje de solución de problemas de red, sin duda se encontrará con banderas de comando previamente desconocidas, ingeniosas frases ingeniosas y nuevas y poderosas herramientas (tcpdump y Wireshark son mis favoritos) para profundizar en las causas de los problemas de su red. Diviértete y recuerda:¡Los paquetes no mienten!