Hoy en día, tenemos muchas soluciones gratuitas para el procesamiento de big data. Muchas empresas también ofrecen funciones empresariales especializadas para complementar las plataformas de código abierto.
La tendencia comenzó en 1999 con el desarrollo de Apache Lucene. El marco pronto se convirtió en código abierto y condujo a la creación de Hadoop. Dos de los marcos de procesamiento de big data más populares que se utilizan en la actualidad son de código abierto:Apache Hadoop y Apache Spark.
Siempre hay dudas sobre qué marco usar, Hadoop o Spark.
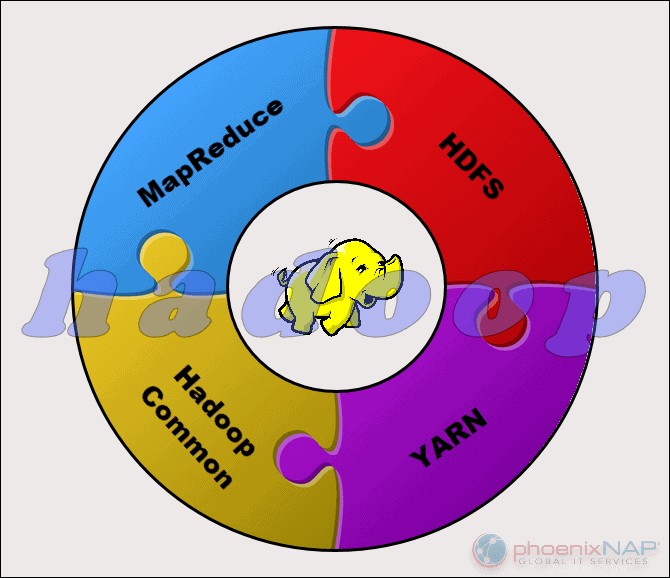
Apache Hadoop es una plataforma que maneja grandes conjuntos de datos de forma distribuida. El marco utiliza MapReduce para dividir los datos en bloques y asignar los fragmentos a los nodos de un clúster. MapReduce luego procesa los datos en paralelo en cada nodo para producir una salida única.
Cada máquina en un clúster almacena y procesa datos. Hadoop almacena los datos en discos usando HDFS . El software ofrece opciones de escalabilidad perfectas. Puede comenzar con tan solo una máquina y luego expandirse a miles, agregando cualquier tipo de hardware empresarial o básico.
El ecosistema Hadoop es altamente tolerante a fallas. Hadoop no depende del hardware para lograr una alta disponibilidad. En esencia, Hadoop está diseñado para buscar fallas en la capa de aplicación. Al replicar datos en un clúster, cuando falla una pieza de hardware, el marco puede construir las partes que faltan desde otra ubicación.
La naturaleza de Hadoop lo hace accesible para todos los que lo necesitan. La comunidad de código abierto es grande y allanó el camino hacia el procesamiento accesible de big data.
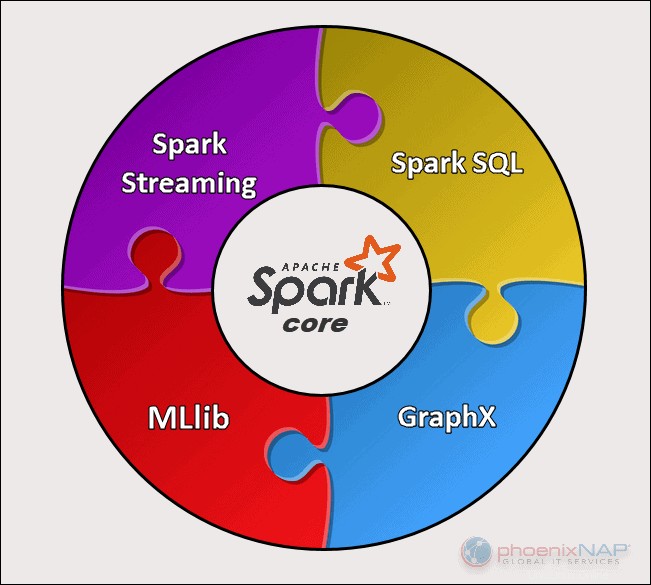
Apache Spark es una herramienta de código abierto. Este marco puede ejecutarse en modo independiente o en una nube o administrador de clústeres como Apache Mesos y otras plataformas. Está diseñado para un rendimiento rápido y usa RAM para almacenar en caché y procesar datos.
Spark realiza diferentes tipos de cargas de trabajo de big data. Esto incluye el procesamiento por lotes similar a MapReduce, así como el procesamiento de secuencias en tiempo real, el aprendizaje automático, el cálculo de gráficos y las consultas interactivas. Con API de alto nivel fáciles de usar, Spark puede integrarse con muchas bibliotecas diferentes, incluida PyTorch y TensorFlow. Para conocer la diferencia entre estas dos bibliotecas, consulte nuestro artículo sobre PyTorch frente a TensorFlow.
El motor Spark fue creado para mejorar la eficiencia de MapReduce y mantener sus beneficios. Aunque Spark no tiene su sistema de archivos, puede acceder a los datos en muchas soluciones de almacenamiento diferentes. La estructura de datos que utiliza Spark se llama Conjunto de datos distribuido resistente o RDD.
Las siguientes secciones describen las principales diferencias y similitudes entre los dos marcos. Echaremos un vistazo a Hadoop vs. Spark desde múltiples ángulos.
La siguiente tabla proporciona una descripción general de las conclusiones realizadas en las siguientes secciones.
| Categoría de comparación | Hadoop | Chispa |
| Rendimiento | Rendimiento más lento, usa discos para almacenamiento y depende de la velocidad de lectura y escritura del disco. | Rápido rendimiento en memoria con menos operaciones de lectura y escritura en disco. |
| Coste | Una plataforma de código abierto, menos costosa de ejecutar. Utiliza hardware de consumo asequible. Más fácil de encontrar profesionales capacitados en Hadoop. | Una plataforma de código abierto, pero depende de la memoria para el cálculo, lo que aumenta considerablemente los costos de funcionamiento. |
| Procesamiento de datos | Mejor para el procesamiento por lotes. Utiliza MapReduce para dividir un gran conjunto de datos en un clúster para un análisis paralelo. | Adecuado para análisis de datos iterativos y de transmisión en vivo. Funciona con RDD y DAG para ejecutar operaciones. |
| Tolerancia a fallos | Un sistema altamente tolerante a fallas. Replica los datos a través de los nodos y los usa en caso de un problema. | Hace un seguimiento del proceso de creación de bloques RDD y luego puede reconstruir un conjunto de datos cuando falla una partición. Spark también puede usar un DAG para reconstruir datos entre nodos. |
| Escalabilidad | Fácilmente escalable agregando nodos y discos para almacenamiento. Admite decenas de miles de nodos sin límite conocido. | Un poco más difícil de escalar porque depende de RAM para los cálculos. Admite miles de nodos en un clúster. |
| Seguridad | Extremadamente seguro. Admite LDAP, ACL, Kerberos, SLA, etc. | No es seguro. De forma predeterminada, la seguridad está desactivada. Se basa en la integración con Hadoop para lograr el nivel de seguridad necesario. |
| Facilidad de uso y Soporte de idiomas | Más difícil de usar con idiomas menos admitidos. Utiliza Java o Python para aplicaciones MapReduce. | Más fácil de usar. Permite el modo de shell interactivo. Las API se pueden escribir en Java, Scala, R, Python, Spark SQL. |
| Aprendizaje automático | Más lento que Spark. Los fragmentos de datos pueden ser demasiado grandes y crear cuellos de botella. Mahout es la biblioteca principal. | Mucho más rápido con procesamiento en memoria. Utiliza MLlib para los cálculos. |
| Programación y gestión de recursos | Utiliza soluciones externas. YARN es la opción más común para la gestión de recursos. Oozie está disponible para la programación de flujos de trabajo. | Tiene herramientas integradas para la asignación, programación y supervisión de recursos. |
Rendimiento
Cuando echamos un vistazo a Hadoop frente a Spark en términos de cómo procesan los datos , puede que no parezca natural comparar el rendimiento de los dos marcos. Aún así, podemos trazar una línea y obtener una imagen clara de qué herramienta es más rápida.
Al acceder a los datos almacenados localmente en HDFS, Hadoop aumenta el rendimiento general. Sin embargo, no coincide con el procesamiento en memoria de Spark. Según las afirmaciones de Apache, Spark parece ser 100 veces más rápido cuando usa RAM para computación que Hadoop con MapReduce.
El predominio se mantuvo con la clasificación de los datos en discos. Spark fue 3 veces más rápido y necesitó 10 veces menos nodos para procesar 100 TB de datos en HDFS. Este punto de referencia fue suficiente para establecer el récord mundial en 2014.
La razón principal de esta supremacía de Spark es que no lee ni escribe datos intermedios en los discos, sino que usa RAM. Hadoop almacena datos en muchas fuentes diferentes y luego procesa los datos en lotes usando MapReduce.
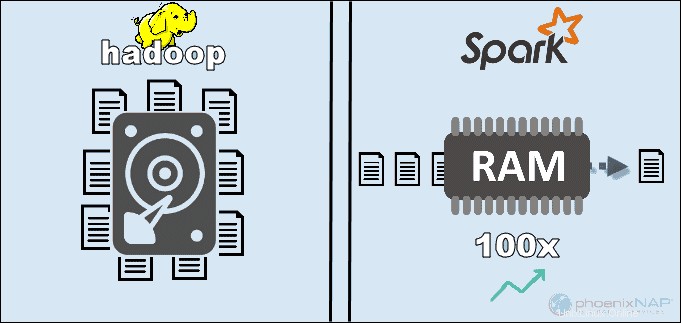
Todo lo anterior puede posicionar a Spark como el ganador absoluto. Sin embargo, si el tamaño de los datos es mayor que la RAM disponible, Hadoop es la opción más lógica. Otro punto a tener en cuenta es el costo de operar estos sistemas.
Coste
Al comparar Hadoop con Spark teniendo en cuenta el costo, debemos profundizar más que el precio del software. Ambas plataformas son de código abierto y completamente gratis. Sin embargo, los costos de infraestructura, mantenimiento y desarrollo deben tenerse en cuenta para obtener un costo total de propiedad (TCO) aproximado.
El factor más importante en la categoría de costos es el hardware subyacente que necesita para ejecutar estas herramientas. Dado que Hadoop depende de cualquier tipo de almacenamiento en disco para el procesamiento de datos, el costo de funcionamiento es relativamente bajo.
Por otro lado, Spark depende de cálculos en memoria para el procesamiento de datos en tiempo real. Por lo tanto, activar nodos con mucha RAM aumenta considerablemente el costo de propiedad.
Otra preocupación es el desarrollo de aplicaciones. Hadoop existe desde hace más tiempo que Spark y es menos difícil encontrar desarrolladores de software.
Los puntos anteriores sugieren que la infraestructura de Hadoop es más rentable . Si bien esta afirmación es correcta, debemos recordar que Spark procesa los datos mucho más rápido. Por lo tanto, requiere una cantidad menor de máquinas para completar la misma tarea.
Procesamiento de datos
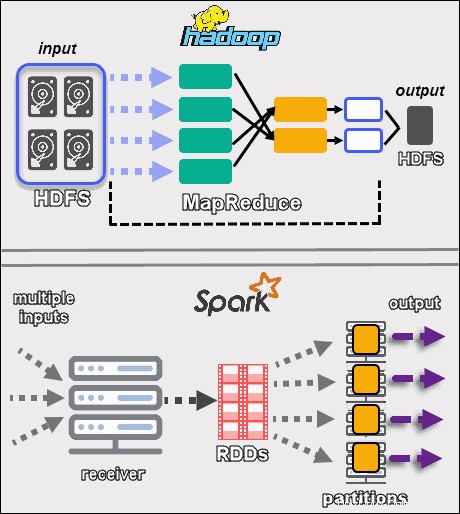
Los dos marcos manejan los datos de maneras muy diferentes . Aunque tanto Hadoop con MapReduce como Spark con RDD procesan datos en un entorno distribuido, Hadoop es más adecuado para el procesamiento por lotes. Por el contrario, Spark brilla con el procesamiento en tiempo real.
El objetivo de Hadoop es almacenar datos en discos y luego analizarlos en paralelo en lotes en un entorno distribuido. MapReduce no requiere una gran cantidad de RAM para manejar grandes volúmenes de datos. Hadoop depende del hardware cotidiano para el almacenamiento y es más adecuado para el procesamiento lineal de datos.
Apache Spark funciona con conjuntos de datos distribuidos resilientes (RDD ). Un RDD es un conjunto distribuido de elementos almacenados en particiones en nodos en todo el clúster. El tamaño de un RDD suele ser demasiado grande para que lo maneje un nodo. Por lo tanto, Spark divide los RDD en los nodos más cercanos y realiza las operaciones en paralelo. El sistema realiza un seguimiento de todas las acciones realizadas en un RDD mediante el uso de un Gráfico acíclico dirigido (DAG ).
Con los cálculos en memoria y las API de alto nivel, Spark maneja de manera eficaz transmisiones en vivo de datos no estructurados. Además, los datos se almacenan en un número predefinido de particiones. Un nodo puede tener tantas particiones como sea necesario, pero una partición no puede expandirse a otro nodo.
Tolerancia a fallos
Hablando de Hadoop frente a Spark en la categoría de tolerancia a fallas, podemos decir que ambos brindan un nivel respetable de manejo de fallas . Además, podemos decir que la forma en que abordan la tolerancia a fallas es diferente.
Hadoop tiene la tolerancia a fallos como base de su funcionamiento. Replica los datos muchas veces a través de los nodos. En caso de que ocurra un problema, el sistema reanuda el trabajo creando los bloques que faltan desde otras ubicaciones. Los nodos maestros rastrean el estado de todos los nodos esclavos. Finalmente, si un nodo esclavo no responde a los pings de un maestro, el maestro asigna los trabajos pendientes a otro nodo esclavo.
Spark usa bloques RDD para lograr la tolerancia a fallas. El sistema rastrea cómo se crea el conjunto de datos inmutable. Luego, puede reiniciar el proceso cuando hay un problema. Spark puede reconstruir datos en un clúster mediante el seguimiento DAG de los flujos de trabajo. Esta estructura de datos permite que Spark maneje fallas en un ecosistema de procesamiento de datos distribuido.
Escalabilidad
La línea entre Hadoop y Spark se vuelve borrosa en esta sección. Hadoop usa HDFS para manejar grandes datos. Cuando el volumen de datos crece rápidamente, Hadoop puede escalar rápidamente para adaptarse a la demanda. Dado que Spark no tiene su sistema de archivos, tiene que depender de HDFS cuando los datos son demasiado grandes para manejarlos.
Los clústeres pueden expandirse fácilmente y aumentar el poder de cómputo agregando más servidores a la red. Como resultado, la cantidad de nodos en ambos marcos puede llegar a miles. No existe un límite firme para la cantidad de servidores que puede agregar a cada clúster y la cantidad de datos que puede procesar.
Algunas de las cifras confirmadas incluyen 8000 máquinas en un entorno Spark con petabytes de datos. Cuando se habla de clústeres de Hadoop, se sabe que albergan decenas de miles de máquinas. y cerca de un exabyte de datos.
Facilidad de uso y compatibilidad con lenguajes de programación
Spark puede ser el marco más nuevo con no tantos expertos disponibles como Hadoop, pero se sabe que es más fácil de usar. Por el contrario, Spark ofrece compatibilidad con varios idiomas junto al idioma nativo (Scala):Java, Python, R y Spark SQL. Esto permite a los desarrolladores utilizar el lenguaje de programación que prefieran.
El marco Hadoop está basado en Java . Los dos lenguajes principales para escribir código MapReduce son Java o Python. Hadoop no tiene un modo interactivo para ayudar a los usuarios. Sin embargo, se integra con las herramientas Pig y Hive para facilitar la escritura de programas MapReduce complejos.
Además de la compatibilidad con las API en varios idiomas, Spark gana en la sección de facilidad de uso con su modo interactivo. Puede usar el shell de Spark para analizar datos de forma interactiva con Scala o Python. El shell proporciona comentarios instantáneos a las consultas, lo que hace que Spark sea más fácil de usar que Hadoop MapReduce.
Otra cosa que le da ventaja a Spark es que los programadores pueden reutilizar el código existente cuando corresponda. Al hacerlo, los desarrolladores pueden reducir el tiempo de desarrollo de aplicaciones. Los datos históricos y de transmisión se pueden combinar para que este proceso sea aún más efectivo.
Seguridad
Al comparar la seguridad de Hadoop con la de Spark, dejaremos que el gato salga de la bolsa de inmediato:Hadoop es el claro ganador . Sobre todo, la seguridad de Spark está desactivada de forma predeterminada. Esto significa que su configuración queda expuesta si no soluciona este problema.
Puede mejorar la seguridad de Spark introduciendo la autenticación a través del secreto compartido o el registro de eventos. Sin embargo, eso no es suficiente para las cargas de trabajo de producción.
Por el contrario, Hadoop funciona con múltiples métodos de autenticación y control de acceso. La más difícil de implementar es la autenticación Kerberos. Si Kerberos es demasiado para manejar, Hadoop también es compatible con Ranger , LDAP , ACL , cifrado entre nodos , permisos de archivo estándar en HDFS y autorización de nivel de servicio .
Sin embargo, Spark puede alcanzar un nivel adecuado de seguridad al integrarse con Hadoop . De esta forma, Spark puede usar todos los métodos disponibles para Hadoop y HDFS. Además, cuando Spark se ejecuta en YARN, puede adoptar los beneficios de otros métodos de autenticación que mencionamos anteriormente.
Aprendizaje automático
El aprendizaje automático es un proceso iterativo que funciona mejor mediante el uso de computación en memoria. Por esta razón, Spark demostró ser una solución más rápida en esta área.
La razón de esto es que Hadoop MapReduce divide los trabajos en tareas paralelas que pueden ser demasiado grandes para los algoritmos de aprendizaje automático. Este proceso crea problemas de rendimiento de E/S en estas aplicaciones de Hadoop.
La biblioteca Mahout es la principal plataforma de aprendizaje automático en los clústeres de Hadoop. Mahout confía en MapReduce para realizar la agrupación, clasificación y recomendación. Samsara comenzó a reemplazar este proyecto.
Spark viene con una biblioteca de aprendizaje automático predeterminada, MLlib. Esta biblioteca realiza cálculos iterativos de aprendizaje automático en memoria. Incluye herramientas para realizar regresión, clasificación, persistencia, construcción de canalizaciones, evaluación y muchas más.
Spark con MLlib demostró ser nueve veces más rápido que Apache Mahout en un entorno basado en disco Hadoop. Cuando necesita resultados más eficientes que los que ofrece Hadoop, Spark es la mejor opción para Machine Learning.
Programación y gestión de recursos
Hadoop no tiene un programador incorporado. Utiliza soluciones externas para la gestión y programación de recursos. Con Administrador de recursos y Administrador de nodos YARN es responsable de la gestión de recursos en un clúster de Hadoop. Una de las herramientas disponibles para programar flujos de trabajo es Oozie.
YARN no se ocupa de la gestión estatal de aplicaciones individuales. Solo asigna la potencia de procesamiento disponible.
Hadoop MapReduce funciona con complementos como CapacityScheduler y FairScheduler . Estos programadores aseguran que las aplicaciones obtengan los recursos esenciales según sea necesario mientras mantienen la eficiencia de un clúster. FairScheduler brinda los recursos necesarios a las aplicaciones mientras realiza un seguimiento de que, al final, todas las aplicaciones obtienen la misma asignación de recursos.
Spark, por otro lado, tiene estas funciones incorporadas. El programador de DAG es responsable de dividir a los operadores en etapas. Cada etapa tiene varias tareas que DAG programa y Spark debe ejecutar.
Spark Scheduler y Block Manager realizan tareas de programación, supervisión y distribución de recursos en un clúster.
Casos de uso de Hadoop frente a Spark
Al observar Hadoop versus Spark en las secciones enumeradas anteriormente, podemos extraer algunos casos de uso para cada marco.
Los casos de uso de Hadoop incluyen:
- Procesar grandes conjuntos de datos en entornos donde el tamaño de los datos supera la memoria disponible.
- Construcción de infraestructura de análisis de datos con un presupuesto limitado.
- Completar trabajos donde no se requieren resultados inmediatos y el tiempo no es un factor limitante.
- Procesamiento por lotes con tareas que aprovechan las operaciones de lectura y escritura del disco.
- Análisis de datos históricos y de archivo.
Con Spark, podemos separar los siguientes casos de uso en los que supera a Hadoop:
- El análisis de datos de transmisión en tiempo real.
- Cuando el tiempo es esencial, Spark ofrece resultados rápidos con cálculos en memoria.
- Tratar con las cadenas de operaciones paralelas utilizando algoritmos iterativos.
- Procesamiento de gráficos paralelos para modelar los datos.
- Todas las aplicaciones de aprendizaje automático.
Nota :Si ha tomado su decisión, puede seguir nuestra guía sobre cómo instalar Hadoop en Ubuntu o cómo instalar Spark en Ubuntu. Si está trabajando en Windows 10, consulte Cómo instalar Spark en Windows 10.
¿Hadoop o Spark?
Hadoop y Spark son tecnologías para el manejo de big data. Aparte de eso, son marcos bastante diferentes en la forma en que administran y procesan los datos.
De acuerdo con las secciones anteriores de este artículo, parece que Spark es el claro ganador. Si bien esto puede ser cierto hasta cierto punto, en realidad, no se crearon para competir entre sí, sino para complementarse.
Por supuesto, como mencionamos anteriormente en este artículo, hay casos de uso en los que uno u otro marco es una opción más lógica. En la mayoría de las demás aplicaciones, Hadoop y Spark funcionan mejor juntos . Como sucesor, Spark no está aquí para reemplazar a Hadoop, sino para usar sus funciones para crear un ecosistema nuevo y mejorado.
Al combinar los dos, Spark puede aprovechar las funciones que le faltan, como un sistema de archivos. Hadoop almacena una gran cantidad de datos utilizando hardware asequible y luego realiza análisis, mientras que Spark brinda procesamiento en tiempo real para manejar los datos entrantes. Sin Hadoop, las aplicaciones comerciales pueden perder datos históricos cruciales que Spark no maneja.
En este entorno cooperativo, Spark también aprovecha los beneficios de gestión de recursos y seguridad de Hadoop. Con YARN, la agrupación en clústeres de Spark y la gestión de datos son mucho más fáciles. Puede ejecutar automáticamente cargas de trabajo de Spark con cualquier recurso disponible.
Esta colaboración proporciona los mejores resultados en análisis de datos transaccionales retroactivos, análisis avanzados y procesamiento de datos de IoT. Todos estos casos de uso son posibles en un entorno.
Los creadores de Hadoop y Spark intentaron hacer las dos plataformas compatibles y producir los resultados óptimos apto para cualquier requerimiento comercial.