Introducción
La necesidad de capturar y procesar big data es la principal fuerza impulsora detrás de la popularidad de la base de datos NoSQL. Los datos almacenados deben ser accesibles en todo momento, desde cualquier lugar y en cualquier dispositivo. Una forma de satisfacer la creciente demanda es escalar y comprar un servidor más grande. Sin embargo, es más eficiente escalar horizontalmente y usar un clúster de servidores bajo demanda.
El modelo de base de datos relacional no es adecuado para un sistema distribuido que abarca varias máquinas. Las bases de datos NoSQL brindan una solución viable al centrarse en el rendimiento y la disponibilidad, al mismo tiempo que sacrifican parte de la consistencia que generalmente se identifica con las bases de datos relacionales.
Además de responder a la pregunta “¿Qué es NoSQL ”, este tutorial utiliza ejemplos sencillos para resaltar conceptos, características y tipos básicos de NoSQL .

¿Qué es NoSQL? (Definición NoSQL)
NoSQL (Not SQL or Not Only SQL) es un término genérico utilizado para las bases de datos que no dependen de un modelo relacional. Los datos no necesitan tener un esquema estricto ni la estructura de tabla SQL habitual. Por lo general, los datos se agregan como pares clave-valor, documentos JSON, gráficos, o tablas de columnas anchas.
Mediante el uso de bases de datos NoSQL, puede almacenar inmensos volúmenes de datos no estructurados a medida que ingresan y estructurarlos en un momento posterior. Como era de esperar, esto conduce a un rendimiento mucho mejor, velocidades de lectura/escritura y le permite escalar horizontalmente los servidores.
Las bases de datos no relacionales, cuando se aplican en el entorno de caso de uso correcto, brindan beneficios significativos en términos de rendimiento y flexibilidad. Sin embargo, no aplicar un esquema en el punto de entrada de datos también significa que es más difícil consultar bases de datos NoSQL, mantener la consistencia de los datos y establecer relaciones entre conjuntos de datos.
Cómo funciona NoSQL
La idea básica detrás de NoSQL es optimizar el rendimiento de la base de datos para el escalado horizontal, grandes volúmenes de datos y baja latencia al renunciar a algunas restricciones de consistencia de datos presentes en los RDBMS. En lugar de modelos de datos rígidos como tablas, columnas o filas, las bases de datos NoSQL ofrecen modelos flexibles. En casos de uso que no requieren consistencia relacional, estos modelos ayudan a que los NoSQL funcionen mejor que las bases de datos relacionales.
Características de las bases de datos NoSQL
Las bases de datos NoSQL son estructuralmente diversas y ofrecen varios modelos de almacenamiento de datos. Sin embargo, existen varios atributos comunes que distinguen a NoSQL de las bases de datos relacionales.
Esquema en lectura
Una base de datos NoSQL le permite almacenar datos antes de aplicar una estructura o esquema .
El código de la aplicación aplica el esquema solo cuando accede a los datos. Este proceso a menudo se denomina esquema en lectura . Al no estructurar los datos por adelantado, las bases de datos NoSQL pueden escribir y leer inmensos volúmenes de datos significativamente más rápido que una base de datos relacional.
NoSQL frente a bases de datos relacionales
Por el contrario, un modelo relacional de SQL estructura los datos entrantes antes de que se escriban en una base de datos. El diseño de esquema predefinido se utiliza para clasificar todos los tipos de datos posibles por adelantado. El esquema se aplica en todos los ámbitos a medida que los datos se estructuran y almacenan en tablas, columnas y filas.
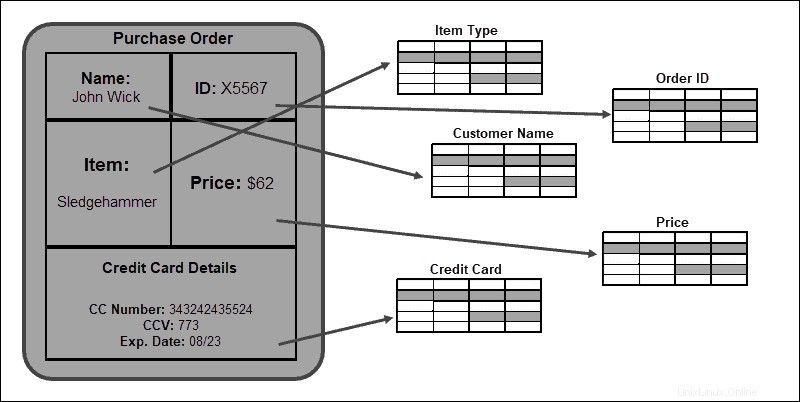
La estructura tabular estricta es una ventaja a la hora de establecer relaciones entre tablas y elementos de la base de datos. La consistencia e integridad de los datos están garantizadas al cumplir con este esquema.
Modelo de datos no relacionales
Las bases de datos NoSQL no establecen relaciones entre registros individuales. Un registro generalmente se almacena como un documento JSON individual y se replica en varios nodos en un clúster.
Usaremos un ejemplo simple que involucra datos sobre bandas de música. En un modelo no relacional, el BandID , Nombre de la banda , País , Género , Etiqueta , ID de álbum , Nombre del álbum, y fecha de lanzamiento los atributos se almacenan en un solo Radiohead documento. Si necesita encontrar la fecha de lanzamiento del álbum de Radiohead, OK Computer , la respuesta es ultrarrápida. La consulta proporciona resultados mucho más rápidos ya que no necesita recuperar información de varias tablas (como en las bases de datos relacionales), sino de una sola entrada.
Los datos agregados en un registro no se pueden relacionar con los datos agregados en otro registro. Cada registro relevante en la base de datos debe actualizarse si desea agregar un atributo, como un servicio de transmisión. Las bases de datos NoSQL son, por lo tanto, más adecuadas para grandes volúmenes de datos que no necesitan estructurarse o relacionarse en un momento posterior.
BASE vs ÁCIDO
¿Es necesario que una base de datos cancele una operación y garantice la coherencia de los datos en caso de falla de la red? ¿O deberían las bases de datos correr el riesgo de incoherencias de datos para garantizar una alta disponibilidad?
El enfoque principal de NoSQL es mantener la disponibilidad al ofrecer coherencia eventual. Coherencia eventual es parte de la semántica BASE. BASE establece que una vez que se escriben los datos, eventualmente aparecerán para su lectura. Sin garantías sólidas, solo tiene una probabilidad limitada de conocer el estado actual, ya que es posible que aún no haya convergido. Si el sistema está funcionando y espera lo suficiente después de un conjunto dado de entradas, finalmente sabrá el verdadero estado de la base de datos.
La desventaja es que es posible que los datos no persistan después de reconciliar los conflictos. Es posible que una lectura no obtenga la última escritura durante un período desconocido. Una publicación de Facebook que no aparece durante unos minutos es aceptable, pero no poder ver una transacción financiera de inmediato es un problema importante.
ÁCIDO
- A tomicidad Solo los datos especificados se ven afectados por una operación.
- C onsistencia Cada operación mueve la base de datos de un estado consistente a otro estado consistente.
- Yo consuelo. Una operación no afecta a otras operaciones simultáneas.
- D durabilidad. Los datos no se pierden después de una transacción exitosa.
BASE
- B asicamente A disponible. Las operaciones de escritura y lectura están disponibles tanto como sea posible, pero sin garantías estrictas.
- S a menudo Estado. Sin garantías, no sabemos, pero tenemos expectativas de que los datos eventualmente se vuelvan consistentes.
- M Consistencia eventual. Si el sistema es completamente funcional y ha pasado un período lo suficientemente largo, eventualmente sabremos el verdadero estado de la base de datos.
Las bases de datos relacionales se centran en la coherencia como la característica más importante a mantener. La coherencia propiedad de una base de datos asegura que si escribe un registro en una base de datos y luego solicita inmediatamente ese registro, tiene la garantía de verlo. El conjunto de propiedades ACID, aplicado por las bases de datos relacionales, significa que una vez que se escriben los datos, tiene total consistencia en las lecturas.
Obtenga más información sobre los dos modelos de transacciones de bases de datos más populares y sus diferencias en el artículo ACID vs BASE.
Escalado horizontal
Las empresas han encontrado formas efectivas de sacar provecho de los datos. El rápido crecimiento del volumen, la velocidad y la variedad de esos datos ha llevado al surgimiento de las bases de datos NoSQL.
Los principales sitios web y plataformas en línea necesitaban superar algunas de las limitaciones de las bases de datos relacionales, como las velocidades de lectura/escritura y la necesidad de normalizar los datos por adelantado. Una limitación importante es la rigidez del modelo relacional cuando se trata de escalar. En un modelo relacional, los datos normalmente no se dividen ni se segregan. En su lugar, se concentra en un solo nodo y las bases de datos solo se pueden escalar aumentando la potencia del hardware existente.
Las bases de datos NoSQL están diseñadas para ejecutarse eficientemente en sistemas distribuidos que se escala rápidamente horizontalmente. Un sistema distribuido tiene la ventaja adicional de proporcionar una alta disponibilidad constante. Se mantienen varias réplicas de un registro en servidores y bastidores, y la falla del hardware no afecta la disponibilidad de los datos. Puede utilizar de forma segura hardware básico en lugar de costosos servidores de gama alta para gestionar cargas de datos vertiginosas.
Tipos de bases de datos NoSQL
Los modelos de bases de datos no relacionales se pueden clasificar en general en cuatro categorías.
- Un almacén de clave-valor le permite almacenar cualquier tipo de datos bajo una clave única.
- Una base de datos de documentos utiliza un enfoque similar al agregar diferentes tipos de datos dentro de un único documento JSON o XML.
- Basado en columnas las bases almacenan datos en una columna de su elección.
- Las bases de datos de gráficos establecen bordes y propiedades para los nodos que representan elementos de datos.
Bases de datos de valores-clave
Las bases de datos de clave-valor, a veces denominadas almacenes de clave-valor, utilizan el modelo de datos más simple:el emparejamiento de una clave y un valor. Una aplicación recupera el valor usando la clave única.
El valor puede contener cualquier estructura o tipo de datos. Depende de la aplicación que intente acceder a los datos para comprender el contenido.
Ejemplos de bases de datos de clave-valor incluyen Redis, Riak , Aerospike y Oracle NoSQL .
Bases de datos basadas en columnas
Las bases de datos basadas en columnas se centran en la eficiencia de las operaciones de lectura. Si necesita leer rápidamente varias columnas de varias filas, tiene sentido organizar los datos en grupos de columnas (es decir, familias de columnas).
La estructura del modelo consta de un identificador de fila que define los datos agregados y el agregado de filas que se compone de valores de nivel secundario más detallados (es decir, columnas ).
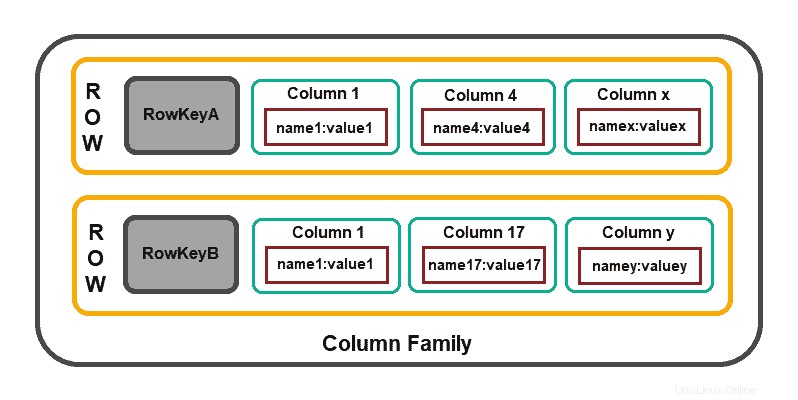
Casandra , HBase , Amazon DynamoDB y Clickhouse , son algunas de las soluciones basadas en columnas más utilizadas.
Bases de datos de documentos
Las bases de datos de documentos almacenan datos parcialmente estructurados en documentos, utilizando JSON, BSON, XML u otros formatos. Los datos dentro del documento están semiestructurados para brindar más flexibilidad al realizar consultas. A diferencia de los almacenes básicos de clave-valor, el usuario no necesita recuperar el registro completo, solo la parte relevante del documento.

Los documentos orientados a la web, los comentarios de los usuarios y las aplicaciones de publicación web se benefician de este modelo de datos. Los famosos NoSQL basados en documentos son MongoDB , OrientDB , Apache CouchDB y MarkLogic .
Bases de datos de gráficos
Las bases de datos de gráficos organizan los datos en nodos y los bordes establecen relaciones entre estos nodos de datos.
Este modelo de almacenamiento de datos demostró ser útil en aplicaciones que enfatizan las relaciones, como plataformas de redes sociales, software de relaciones con los clientes y sistemas de viajes y reservas.
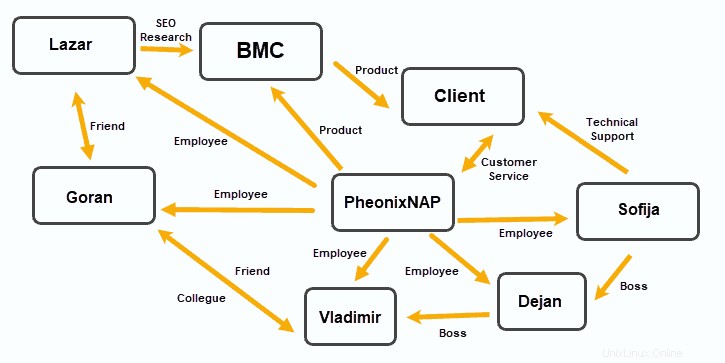
OrientDB y MarkLogic basados en documentos pueden funcionar como bases de datos de gráficos. Gráfico de Jano , RedisGraph y Neo4j son soluciones populares basadas en gráficos.
Ventajas de NoSQL
- Rendimiento – Las bases de datos NoSQL ofrecen un mejor rendimiento en los casos de uso que tratan con datos que no son altamente relacionales. Un NoSQL espera un esquema desnormalizado y optimiza las lecturas en consecuencia.
- Flexibilidad – El esquema dinámico de NoSQL facilita el almacenamiento de datos no estructurados de manera óptima para un caso específico. Permite la creación de documentos sin definir su estructura.
- Escalabilidad – Si bien es posible escalar verticalmente RDBMS actualizando la memoria, el almacenamiento o la potencia de procesamiento de la máquina, NoSQL tiene el beneficio adicional de la escala horizontal. Esto significa que es posible manejar un aumento en el tráfico actualizando la base de datos con servidores adicionales.
¿Cuándo usar NoSQL?
Intentar aplicar una única solución de base de datos para cada escenario posible no es una buena idea. Los diferentes tipos de bases de datos que se tratan en este artículo están diseñados para tratar problemas de datos específicos. Esto no se limita a las bases de datos NoSQL. Incluso las bases de datos relacionales luchan por estandarizar varios tipos de datos en un esquema estricto.
El funcionamiento interno de las bases de datos relacionales está bien documentado y es predecible. El lenguaje SQL y el conjunto de herramientas creadas con tecnología relacional son omnipresentes, con personal experimentado disponible. El modelo de base de datos relacional le permite acceder a los datos de muchas maneras diferentes y creativas y no estar limitado por cómo se almacenan los datos.
Grandes datos
Big Data y el valor de capturar tanto como sea técnicamente posible, no es una carga de trabajo adecuada para el modelo relacional. Una base de datos NoSQL que no utiliza un esquema estricto es una excelente opción para almacenar grandes cantidades de datos variados y no estructurados.
Desarrollo de software
El desarrollo de aplicaciones se ha beneficiado enormemente de las bases de datos NoSQL. Se desperdiciaron muchas horas preciosas de desarrollador en mapear datos entre estructuras de datos en memoria y una base de datos relacional. Una base de datos NoSQL significa que usted crea su modelo, uno que se adapta para satisfacer las necesidades de la aplicación que accede a él y posiblemente reducir la cantidad de codificación requerida.
Si una base de datos no tiene un esquema, significa que la aplicación que accede a los datos debe tener uno. Esto puede convertirse rápidamente en un problema si más de una aplicación, desarrollada de forma independiente, necesita acceder a la misma base de datos.
Las inconsistencias en las lecturas finalmente se resuelven, pero la falta de consistencia en las escrituras es un problema grave. Este problema a menudo se resuelve limitando todas las interacciones de la base de datos dentro de una sola aplicación e integrándola con otras aplicaciones que utilizan servicios web. Esta solución se relaciona bien con la tendencia general de utilizar servicios web con fines de integración.