Por otro lado, aumentan los rendimientos de recuperación de datos. En lugar de realizar múltiples JOIN costosos en numerosas tablas, la normalización de la base de datos ayuda a reunir información que se combina de manera común o lógica.
Las anomalías de la base de datos aparecen debido a formas normales inferiores. El problema de las redundancias encuentra una solución al agregar limitaciones a nivel de software al ingresar datos en una base de datos.
La normalización y desnormalización de la base de datos son dos formas diferentes de alterar la estructura de una base de datos. La tabla describe las principales diferencias entre los dos métodos:
| Normalización | Desnormalización |
|---|
| Funcionalidad | Elimina la información redundante y mejora la velocidad de cambio de datos. | Combina información múltiple en una sola unidad y mejora la velocidad de recuperación de datos. |
| Enfoque | Limpieza de la base de datos para eliminar redundancias. | Se introdujeron redundancias para una ejecución de consultas más rápida. |
| Memoria | Rendimiento general optimizado y mejorado. | Ineficiencia de la memoria debido a redundancias. |
| Integridad | La eliminación de anomalías en la base de datos mejora la integridad de la base de datos. | No se mantiene la integridad de los datos. Hay anomalías en la base de datos. |
| Caso de uso | Bases de datos donde los cambios de inserción, actualización y eliminación ocurren con frecuencia y las uniones no son costosas. | Bases de datos que se consultan con frecuencia, como almacenes de datos. |
| Tipo de procesamiento | Procesamiento de transacciones en línea - OLTP | Procesamiento analítico en línea - OLAP |
La normalización de la base de datos toma una base de datos no normalizada a través de formas normales para mejorar la estructura de datos. Por otro lado, la desnormalización comienza con una base de datos normalizada y combina datos para una ejecución más rápida de consultas de uso común.
¿Por qué y cuándo debería desnormalizar una base de datos?
La desnormalización de la base de datos es una técnica viable cuando la velocidad de recuperación de datos es un factor esencial. Sin embargo, el método cambia la estructura general de la base de datos. La desnormalización es útil en los siguientes escenarios:
- Mejora del rendimiento de consultas. Juntar la información agrega redundancias. Sin embargo, la cantidad de JOIN se reduce, lo que aumenta el rendimiento de las consultas.
- Conveniencia de gestión . Una base de datos normalizada es difícil de administrar debido a su gran granularidad. En lugar de calcular valores o conectarlos según sea necesario, la desnormalización ayuda a proporcionar datos fácilmente disponibles.
- Informes acelerados . Los datos analíticos requieren una gran cantidad de cálculos con prontitud. Una base de datos desnormalizada para generar informes es una solución perfecta para proporcionar información analítica rápidamente.
Si una base de datos tiene un rendimiento bajo, la desnormalización no siempre es el camino correcto a seguir. Dado que el proceso cambia la estructura de la base de datos, las funcionalidades existentes corren el riesgo de fallar.
Tener un punto de referencia es un concepto importante al cambiar la estructura de la base de datos. En última instancia, la normalización de la base de datos sirve como último recurso en lugar de una solución rápida.
Técnicas de desnormalización
Se utilizan varias técnicas de desnormalización de bases de datos según el caso de uso. Cada método tiene un lugar apropiado de uso, ventajas y desventajas.
Pre-unión de Mesas
Las tablas preunidas almacenan la información utilizada con frecuencia en una sola tabla. El proceso es útil cuando:
- Las consultas se ejecutan con frecuencia en las tablas juntas.
- La operación de unión es costosa.
El método crea redundancias masivas, por lo que es fundamental utilizar un número mínimo de columnas y actualizar la información periódicamente.
Ejemplo de tablas previas a la unión
Una tienda mantiene la información sobre los artículos y las categorías a las que pertenecen los artículos. La clave externa sirve como referencia al tipo de elemento. Al unirse previamente a las tablas, se agrega el nombre de la categoría a la tabla de artículos.
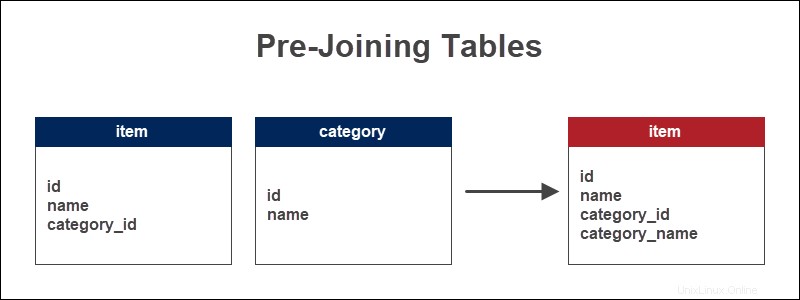
Agregar el nombre de la categoría directamente a la tabla de artículos permite ver los artículos por categoría rápidamente. Para consultas más largas, este método ahorra tiempo y reduce la cantidad de JOIN.
Mesas espejadas
Una tabla reflejada es una copia de una tabla existente. La tabla es:
- Una copia parcial.
- Una copia completa.
El objetivo es reproducir los datos del original en una nueva tabla. Hacer duplicados es una buena técnica para crear una copia de seguridad para preservar el estado inicial de la base de datos.
Ejemplo de tablas duplicadas
La duplicación de tablas es un método que se utiliza a menudo para preparar datos en los sistemas de apoyo a la toma de decisiones. Dado que las consultas generalmente se agregan en muchos puntos de datos, la tarea disminuiría significativamente el rendimiento del sistema.
Los sistemas de soporte de decisiones se benefician enormemente del uso de tablas reflejadas. La aplicación de transacciones sobre la tabla original no se interrumpe mientras que los informes exigentes ocurren en la tabla duplicada.
División de tablas
La división de tablas implica dividir las tablas normalizadas en dos o más relaciones. La división de tablas sucede en dos dimensiones:
- Horizontalmente . Las tablas se dividen en subconjuntos de filas mediante
UNION operador.
- Verticalmente . Las tablas se dividen en subconjuntos de columnas mediante
INNER JOIN operador.
El objetivo del método es dividir las tablas en unidades más pequeñas para un manejo de datos más rápido y conveniente. Si la base de datos también contiene la tabla original, este método se considera un caso particular de tablas reflejadas.
Ejemplos de división de tablas
Los ejemplos de uso dependen de los criterios de división de tablas. Las razones más comunes para dividir mesas son:
- Administrativo . Una mesa para cada sector en lugar de una mesa para toda la empresa.
- Espacial . Una tabla para cada región en lugar de una tabla para todo el país.
- Basado en el tiempo . Una mesa para cada mes en lugar de una mesa para todo el año.
- Físico . Una tabla para cada ubicación en lugar de una tabla para todos los sitios.
- Procedimiento . Una tabla para cada paso de una tarea en lugar de una tabla para todo el trabajo.
Almacenamiento de valores derivables
Vale la pena almacenar los cálculos que se ejecutan con frecuencia en situaciones en las que:
- El uso del valor derivado es frecuente.
- Los valores de origen no cambian.
El almacenamiento directo de datos derivables garantiza que los cálculos ya se hayan realizado al generar un informe y elimina la necesidad de buscar los valores de origen para cada consulta.
Ejemplo de almacenamiento de valores derivados
Si tenemos una tabla de base de datos que realiza un seguimiento de la información sobre las personas, la edad de una persona es un valor calculado en función de su fecha de nacimiento. Obtenga la edad encontrando la diferencia entre la fecha actual usando la función de fecha de MySQL CURDATE() y la fecha de nacimiento.
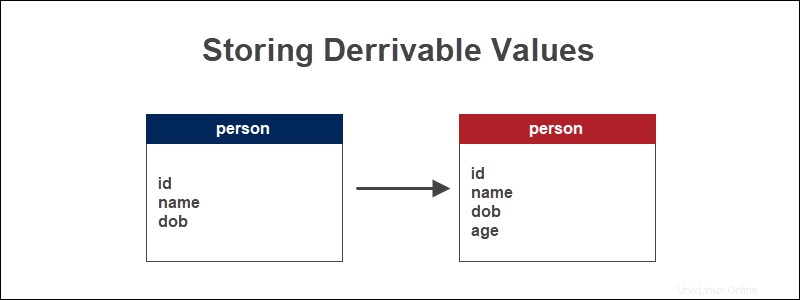
La edad es un dato fundamental a la hora de analizar cualquier información demográfica. El valor de origen, que es la fecha de nacimiento, no cambia.
Tablas de jerarquía
Una tabla de jerarquía es una estructura similar a un árbol con una relación de uno a muchos. Una tabla principal tiene muchos hijos. Sin embargo, los hijos solo tienen una tabla principal. Las tablas de jerarquía se utilizan en los casos en que:
- La estructura de los datos es jerárquica.
- Las tablas principales son estáticas y no cambian.
Valores codificados
Los valores codificados eliminan una referencia a una entidad de uso común. Utilice este método en situaciones en las que:
- Los valores se consideran estáticos.
- El número de valores es pequeño.
En lugar de utilizar una pequeña tabla de consulta, los valores se codifican directamente en la aplicación. El proceso también evita tener que realizar uniones en la tabla de búsqueda.
Ejemplo de valores codificados
Una tabla con información sobre personas podría usar una pequeña tabla de consulta para almacenar información sobre el género de las personas. Dado que la información en la tabla de búsqueda tiene un número limitado de valores, considere codificar los datos directamente en la tabla de personas.
Los valores codificados eliminan la necesidad de una tabla de búsqueda y la operación JOIN con esa tabla. Cualquier alteración realizada en la tabla de búsqueda o registro de nuevos valores requiere la adición de una restricción de verificación.
Almacenamiento de detalles con maestro
La tabla maestra contiene la tabla principal de información, mientras que otras tablas contienen detalles específicos. Almacene los detalles con la tabla maestra cuando:
- Es esencial una descripción general detallada de la tabla maestra.
- Los informes analíticos en la tabla maestra son frecuentes.
Mantener todos los detalles con la tabla maestra es conveniente cuando se seleccionan datos. El método funciona mejor cuando hay menos detalles. De lo contrario, el proceso de recuperación de datos se ralentiza significativamente.
Ejemplo de almacenamiento de detalles con maestro
Una tabla maestra con información del cliente normalmente almacena detalles específicos sobre la persona en una tabla separada. La información sobre la ubicación en particular, por ejemplo, generalmente reside en una serie de tablas más pequeñas.
Cualquier informe que considere la ubicación de los clientes se beneficia al agregar los detalles de la ubicación a la tabla maestra.
Repetición de un solo detalle con maestro
Las consultas a menudo necesitan agregar un solo detalle a la tabla maestra en lugar de unir varios valores previamente. Utilice este método cuando:
- Las UNIONES son costosas para un solo detalle.
- La tabla maestra requiere la información con frecuencia.
Agregar un solo detalle a una tabla maestra es más común cuando la base de datos contiene datos históricos. La entidad repetida suele ser la información más reciente.
Ejemplo de detalle único con maestro
La base de datos de una tienda normalmente tiene una tabla maestra de información sobre los artículos que vende. Otra tabla con detalles sobre los cambios de precios históricos también contiene información sobre el precio actual.
Dado que este único detalle ayuda a analizar los precios actuales de los artículos, es útil repetir la información más reciente sobre el precio en la tabla maestra.
Cualquier cambio de costo debe abordarse y actualizarse en la tabla maestra también para mantener la coherencia.
Llaves de cortocircuito
En una base de datos con tres o más tablas de información relacionada, el método de claves de cortocircuito omite la(s) tabla(s) intermedia(s) y "cortocircuita" las tablas principal y secundaria.
Utilice la técnica del cortocircuito en situaciones en las que:
- Una base de datos tiene más de tres niveles de maestro-detalle.
- Los valores de los abuelos y nietos a menudo se necesitan y la información de los padres no es tan valiosa.
Si dos relaciones se relacionan a través de una tabla intermedia, omita JOIN en la relación intermedia y conecte la primera y la última tabla directamente.
Ejemplo de llaves de cortocircuito
Un sistema de información podría mantener información sobre personas en una tabla, su dirección en otra ubicación y el área geográfica de esa dirección en una tercera tabla. Para cualquier informe demográfico, la dirección exacta no es un dato crítico.
Sin embargo, la ubicación de una persona es esencial para el análisis. Cortocircuitar la mesa de personas con el área omite JOIN en la mesa del medio.
Ventajas de la desnormalización
Las ventajas de la desnormalización de la base de datos son:
- Velocidad . Dado que las consultas JOIN son costosas en una base de datos normalizada, la recuperación de datos es más rápida.
- Simplicidad . La obtención de datos es más sencilla debido a la menor cantidad de tablas.
- Menos errores . Trabajar con un número menor de tablas significa menos errores al recuperar información de una base de datos.
Desventajas de la desnormalización
Las desventajas a considerar al desnormalizar una base de datos son:
- Complejidad . Actualizar e insertar en una base de datos es más complejo y costoso.
- Incoherencia . Encontrar el valor correcto para una parte de la información es más desafiante porque los datos son difíciles de actualizar.
- Almacenamiento . Se necesita un espacio de almacenamiento más significativo debido a las redundancias introducidas.
