Introducción
phoenixNAP Bare Metal Cloud expone una interfaz RESTful API que permite a los desarrolladores automatizar la creación de servidores bare metal.
Para demostrar las capacidades del sistema, este artículo explica y proporciona ejemplos de código de Python sobre cómo aprovechar la API de BMC para automatizar el aprovisionamiento de un clúster Spark en Bare Metal Cloud .

Requisitos previos
- cuenta de phoenixNAP Bare Metal Cloud
- Un token de acceso OAuth
Cómo automatizar la implementación de Spark Clusters
Las instrucciones a continuación se aplican al entorno Bare Metal Cloud de phoenixNAP. Es posible que los ejemplos de código de Python que se encuentran en este artículo no funcionen en otros entornos.
Los pasos necesarios para implementar y acceder al clúster de Apache Spark:
1. Genere un token de acceso.
2. Cree servidores Bare Metal Cloud que ejecuten Ubuntu OS.
3. Implemente un clúster de Apache Spark en las instancias de servidor creadas.
4. Acceda al panel de control de Apache Spark siguiendo el enlace generado.
El artículo destaca un subconjunto de segmentos de código de Python que aprovechan la API de Bare Metal Cloud y los comandos de shell para completar los pasos descritos anteriormente.
Paso 1:Obtenga el token de acceso
Antes de enviar solicitudes a la API de BMC, debe obtener un token de acceso de OAuth utilizando el client_id y cliente_secreto registrado en el Portal BMC.
Para obtener más información sobre cómo registrarse para client_id y client_secret, consulte la guía de inicio rápido de la API Bare Metal Cloud.
A continuación se muestra la función de Python que genera el token de acceso para la API:
def get_access_token(client_id: str, client_secret: str) -> str:
"""Retrieves an access token from BMC auth by using the client ID and the
client Secret."""
credentials = "%s:%s" % (client_id, client_secret)
basic_auth = standard_b64encode(credentials.encode("utf-8"))
response = requests.post(' https://api.phoenixnap.com/bmc/v0/servers',
headers={
'Content-Type': 'application/x-www-form-urlencoded',
'Authorization': 'Basic %s' % basic_auth.decode("utf-8")},
data={'grant_type': 'client_credentials'})
if response.status_code != 200:
raise Exception('Error: {}. {}'.format(response.status_code, response.json()))
return response.json()['access_token']
Paso 2:Crear instancias de servidor bare metal
Utilice las llamadas a la API REST de POST/servidores para crear instancias de servidor bare metal. Para cada solicitud POST/servidores, especifique los parámetros necesarios, como la ubicación del centro de datos, el tipo de servidor, el sistema operativo, etc.
A continuación se muestra la función de Python que realiza una llamada a la API de BMC para crear un servidor bare metal.
def __do_create_server(session, server):
response = session.post('https://api.phoenixnap.com/bmc/v0/servers'),
data=json.dumps(server))
if response.status_code != 200:
print("Error creating server: {}".format(json.dumps(response.json())))
else:
print("{}".format(json.dumps(response.json())))
return response.json()
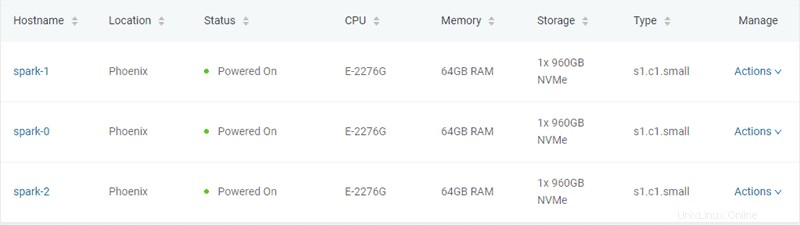
En este ejemplo, se crean tres servidores bare metal de tipo "s1.c1.small", como se especifica en el archivo server-settings.conf.
{
"ssh-key" : "ssh-rsa xxxxxx== username",
"servers_quantity" : 3,
"type" : "s1.c1.small",
"hostname" : "spark",
"description" : "spark",
"public" : True,
"location" : "PHX",
"os" : "ubuntu/bionic"
}
El resultado esperado del script de Python que genera el token y aprovisiona los servidores es el siguiente:
Retrieving token
Successfully retrieved API token
Creating servers...
{
"id": "5ee9c1b84a9ca71ea6b9b766",
"status": "creating",
"hostname": "spark-1",
"description": "spark-1",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.11"
],
"publicIpAddresses": [
"131.153.143.250",
"131.153.143.251",
"131.153.143.252",
"131.153.143.253",
"131.153.143.254"
]
}
Server created, provisioning spark-1...
{
"id": "5ee9c1b84a9ca71ea6b9b767",
"status": "creating",
"hostname": "spark-0",
"description": "spark-0",
"os": "ubuntu/bionic",
"type": "s1.c1.small",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.12"
],
"publicIpAddresses": [
"131.153.143.50",
"131.153.143.51",
"131.153.143.52",
"131.153.143.53",
"131.153.143.54"
]
}
Server created, provisioning spark-0...
{
"id": "5ee9c1b84a9ca71ea6b9b768",
"status": "creating",
"hostname": "spark-2",
"description": "spark-2",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.13"
],
"publicIpAddresses": [
"131.153.142.234",
"131.153.142.235",
"131.153.142.236",
"131.153.142.237",
"131.153.142.238"
]
}
Server created, provisioning spark-2...
Waiting for servers to be provisioned... Una vez que crea los tres servidores bare metal, el script se comunica con la API de BMC para verificar el estado del servidor hasta que se complete el aprovisionamiento y los servidores se enciendan.
Paso 3:aprovisionar el clúster de Apache Spark
Una vez que se aprovisionan los servidores, el script de Python establece una conexión SSH utilizando la dirección IP pública de los servidores. A continuación, el script instala Spark en los servidores de Ubuntu. Eso incluye instalar JDK , Escala , Git y Chispa en todos los servidores.
Para iniciar el proceso, ejecute all_hosts.sh archivo en todos los servidores. El script proporciona instrucciones de descarga e instalación, así como la configuración del entorno necesaria para preparar el clúster para su uso.
Apache Spark incluye scripts que configuran los servidores como nodos maestros y trabajadores. La única restricción en la configuración de un nodo trabajador es tener ya configurado el nodo maestro. El primer servidor que se aprovisionará se asigna como el nodo Spark Master.
La siguiente función de Python realiza esa tarea:
def wait_server_ready(function_scheduler, server_data):
json_server = bmc_api.get_server(REQUEST, server_data['id'])
if json_server['status'] == "creating":
main_scheduler.enter(2, 1, wait_server_ready, (function_scheduler, server_data))
elif json_server['status'] == "powered-on" and not data['has_a_master_server']:
server_data['status'] = json_server['status']
server_data['master'] = True
server_data['joined'] = True
data['has_a_master_server'] = True
data['master_ip'] = json_server['publicIpAddresses'][0]
data['master_hostname'] = json_server['hostname']
print("ASSIGNED MASTER SERVER: {}".format(data['master_hostname']))Ejecute el master_host.sh archivo para configurar el primer servidor como el nodo maestro. Vea a continuación el contenido del master_host.sh archivo:
#!/bin/bash
echo "Setting up master node"
/opt/spark/sbin/start-master.shUna vez que se asigna y configura el nodo principal, los otros dos nodos se agregan al clúster de Spark.
Vea a continuación el contenido del worker_host.sh archivo:
#!/bin/bash
echo "Setting up master node on /etc/hosts"
echo "$1 $2 $2" | sudo tee -a /etc/hosts
echo "Starting worker node"
echo "Joining worker node to the cluster"
/opt/spark/sbin/start-slave.sh spark://$2:7077
Se completó el aprovisionamiento de un clúster de Apache Spark. A continuación se muestra el resultado esperado de la secuencia de comandos de Python:
ASSIGNED MASTER SERVER: spark-2
Running all_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running master_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up master node
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.master.Master-1-spark-2.out
Master host installed
Running all_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running all_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running slave_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-0.out
Running slave_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-1.out
Setup servers done
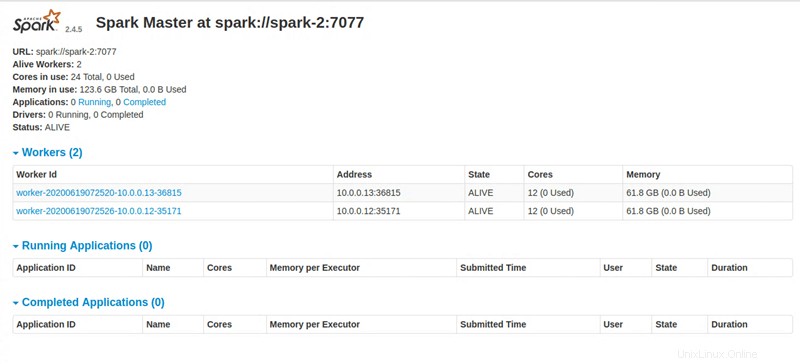
Master node UI: http://131.153.142.234:8080
Paso 4:acceda al panel de Apache Spark
Al ejecutar todas las instrucciones, la secuencia de comandos de Python proporciona un enlace para acceder al panel de Apache Spark.