Apache Spark es un marco de computación en clúster gratuito y de código abierto que se utiliza para análisis, aprendizaje automático y procesamiento de gráficos en grandes volúmenes de datos. Spark viene con más de 80 operadores de alto nivel que le permiten crear aplicaciones paralelas y usarlas de manera interactiva desde los shells de Scala, Python, R y SQL. Es un motor de procesamiento de datos en memoria ultrarrápido especialmente diseñado para la ciencia de datos. Proporciona un amplio conjunto de características que incluyen velocidad, tolerancia a fallas, procesamiento de flujo en tiempo real, computación en memoria, análisis avanzado y muchas más.
En este tutorial, le mostraremos cómo instalar Apache Spark en el servidor Debian 10.
Requisitos
- Un servidor que ejecuta Debian 10 con 2 GB de RAM.
- Se ha configurado una contraseña raíz en su servidor.
Cómo empezar
Antes de comenzar, se recomienda actualizar su servidor con la última versión. Puede actualizarlo usando el siguiente comando:
apt-get update -y
apt-get upgrade -y
Una vez que su servidor esté actualizado, reinícielo para implementar los cambios.
Instalar Java
Apache Spark está escrito en lenguaje Java. Por lo tanto, deberá instalar Java en su sistema. De forma predeterminada, la última versión de Java está disponible en el repositorio predeterminado de Debian 10. Puedes instalarlo usando el siguiente comando:
apt-get install default-jdk -y
Después de instalar Java, verifique la versión instalada de Java usando el siguiente comando:
java --version
Deberías obtener el siguiente resultado:
openjdk 11.0.5 2019-10-15 OpenJDK Runtime Environment (build 11.0.5+10-post-Debian-1deb10u1) OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Debian-1deb10u1, mixed mode, sharing)
Descargar Apache Spark
Primero, deberá descargar la última versión de Apache Spark desde su sitio web oficial. Al momento de escribir este artículo, la última versión de Apache Spark es la 3.0. Puede descargarlo en el directorio /opt con el siguiente comando:
cd /opt
wget http://apachemirror.wuchna.com/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
Una vez que se complete la descarga, extraiga el archivo descargado usando el siguiente comando:
tar -xvzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
A continuación, cambie el nombre del directorio extraído a chispa como se muestra a continuación:
mv spark-3.0.0-preview2-bin-hadoop2.7 spark
A continuación, deberá configurar el entorno para Spark. Puede hacerlo editando el archivo ~/.bashrc:
nano ~/.bashrc
Agregue las siguientes líneas al final del archivo:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Guarde y cierre el archivo cuando haya terminado. Luego, active el entorno con el siguiente comando:
source ~/.bashrc
Iniciar el servidor maestro
Ahora puede iniciar el servidor maestro usando el siguiente comando:
start-master.sh
Deberías obtener el siguiente resultado:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.out
De forma predeterminada, Apache Spark escucha en el puerto 8080. Puede verificarlo con el siguiente comando:
netstat -ant | grep 8080
Salida:
tcp6 0 0 :::8080 :::* LISTEN
Ahora, abra su navegador web y escriba la URL http://server-ip-address:8080. Debería ver la siguiente página:
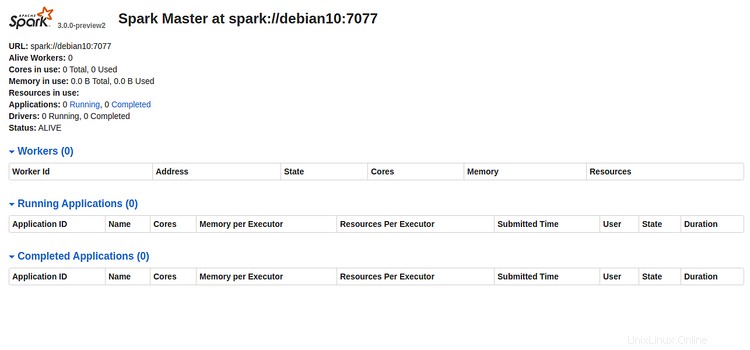
Anote la URL de Spark "spark://debian10:7077 " de la imagen de arriba. Esto se usará para iniciar el proceso de trabajo de Spark.
Iniciar proceso de trabajo de Spark
Ahora, puede iniciar el proceso de trabajo de Spark con el siguiente comando:
start-slave.sh spark://debian10:7077
Deberías obtener el siguiente resultado:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.out
Acceder a Spark Shell
Spark Shell es un entorno interactivo que proporciona una forma sencilla de aprender la API y analizar datos de forma interactiva. Puede acceder al shell de Spark con el siguiente comando:
spark-shell
Debería ver el siguiente resultado:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.0.0-preview2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
19/12/29 15:53:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1577634806690).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.5)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Desde aquí, puede aprender cómo aprovechar al máximo Apache Spark de manera rápida y conveniente.
Si desea detener el servidor Spark Master y Slave, ejecute los siguientes comandos:
stop-slave.sh
stop-master.sh
Eso es todo por ahora, ha instalado con éxito Apache Spark en el servidor Debian 10. Para obtener más información, puede consultar la documentación oficial de Spark en Spark Doc.