Introducción
Kubernetes ofrece un extraordinario nivel de flexibilidad para orquestar un gran grupo de contenedores distribuidos.
La gran cantidad de características y opciones disponibles puede presentar un desafío. La aplicación de las mejores prácticas lo ayuda a evitar posibles obstáculos y a crear un entorno seguro y eficiente desde el principio.
Utilice las prácticas recomendadas de Kubernetes descritas. para crear contenedores optimizados, agilizar las implementaciones, administrar servicios confiables y administrar un clúster completo.

Contenedores seguros y optimizados
Los contenedores proporcionan mucho menos aislamiento que las máquinas virtuales. Siempre debe verificar las imágenes de los contenedores y mantener un control estricto sobre los permisos de los usuarios.
El uso de imágenes de contenedores pequeños aumenta la eficiencia, conserva los recursos y reduce la superficie de ataque para posibles atacantes.
Usar solo imágenes de contenedores confiables
Las imágenes de contenedores listas para usar son muy accesibles y excepcionalmente útiles. Sin embargo, las imágenes públicas pueden volverse obsoletas rápidamente, contener exploits, errores o incluso software malicioso que se propaga rápidamente a través de un clúster de Kubernetes.
Solo use imágenes de repositorios confiables y siempre escanee las imágenes en busca de posibles vulnerabilidades. Numerosas herramientas en línea, como Anchore o Clair, brindan un análisis estático rápido de imágenes de contenedores y le informan sobre posibles amenazas y problemas. Dedique unos minutos a escanear imágenes de contenedores antes de implementarlas y evitar consecuencias potencialmente desastrosas.
Usuarios no root y sistemas de archivos de solo lectura
Cambie el contexto de seguridad incorporado para obligar a todos los contenedores a ejecutarse solo con usuarios que no sean root y con un sistema de archivos de solo lectura.
Evite ejecutar contenedores como usuario raíz. Una brecha de seguridad puede escalar rápidamente si un usuario puede otorgarse permisos adicionales.

Si un sistema de archivos está configurado para solo lectura, hay pocas posibilidades de alterar el contenido del contenedor. En lugar de editar los archivos del sistema, sería necesario eliminar todo el contenedor y colocar uno nuevo en su lugar.
Cree imágenes pequeñas y en capas
Las imágenes pequeñas aceleran sus compilaciones y necesitan menos almacenamiento. La superposición eficiente de una imagen puede reducir significativamente el tamaño de la imagen. Intente crear sus imágenes desde cero para lograr resultados óptimos.
Use varias declaraciones FROM en un solo Dockerfile si necesita muchos componentes diferentes. Esta función crea secciones, cada una de las cuales hace referencia a una imagen base diferente. La imagen final ya no almacena las capas anteriores, solo los componentes que necesita de cada una, lo que hace que el contenedor de Docker sea mucho más delgado.
Cada capa se extrae en función de FROM comando ubicado en el contenedor desplegado.
Limitar el acceso de usuarios con RBAC
El control de acceso basado en roles (RBAC) garantiza que ningún usuario tenga más permisos de los que necesita para completar sus tareas. Puede habilitar RBAC agregando el siguiente indicador al iniciar el servidor API:
--authorization-mode=RBACRBAC utiliza el rbac.authorization.k8s.io Grupo de API para impulsar decisiones de autorización a través de la API de Kubernetes.
Registros de Stdout y Stderr
Es una práctica común enviar registros de aplicaciones a stdout (salida estándar) y registros de errores en stderr (error estándar) corriente. Una vez que una aplicación escribe en stdout y stderr, un motor de contenedor, como Docker, redirige y almacena registros en un archivo JSON.
Los contenedores, pods y nodos de Kubernetes son entidades dinámicas. Los registros deben ser consistentes y estar permanentemente disponibles. Por lo tanto, se recomienda mantener los registros de todo el clúster en un sistema de almacenamiento independiente.
Kubernetes se puede integrar con una amplia gama de soluciones de registro existentes, como ELK Stack.
Agilice las implementaciones
Una implementación de Kubernetes establece una plantilla que garantiza que los pods estén en funcionamiento, se actualicen regularmente o se reviertan según lo definido por el usuario.
El uso de etiquetas transparentes, banderas, contenedores vinculados y DaemonSets puede brindarle un control detallado sobre el proceso de implementación.
Uso de la bandera de registro
Cuando agrega el --record bandera, el kubectl ejecutado El comando se almacena como una anotación. Al inspeccionar el historial de lanzamiento de la implementación, puede rastrear fácilmente las actualizaciones en el CAMBIO-CAUSA columna.
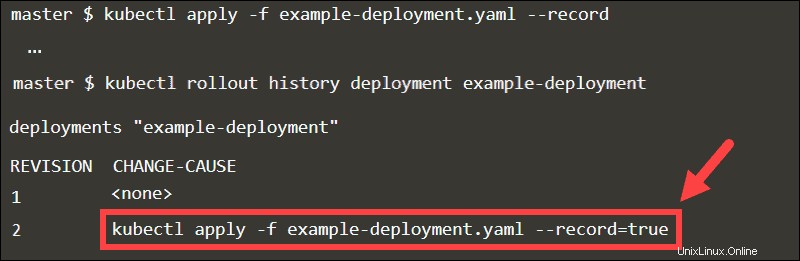
Retroceda a cualquier revisión declarando el número de revisión en el comando deshacer.
kubectl rollout undo deployment example-deployment --to-revision=1
Sin el --record bandera, sería difícil identificar la revisión específica.
Etiquetas descriptivas
Trate de usar tantas etiquetas descriptivas como sea posible. Las etiquetas son pares clave:valor que permiten a los usuarios agrupar y organizar pods en subconjuntos significativos. La mayoría de las funciones, los complementos y las soluciones de terceros necesitan etiquetas para poder identificar los pods y controlar los procesos automatizados.
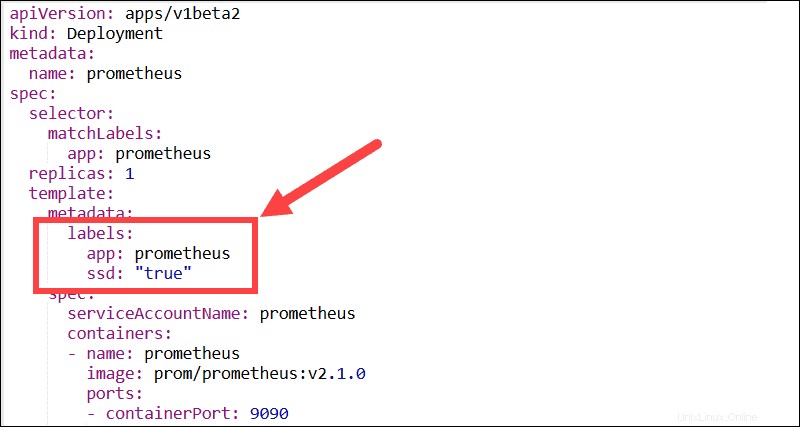
Por ejemplo, los DaemonSets de Kubernetes dependen de etiquetas y selectores de nodos para administrar la implementación de pods dentro de un clúster.
Crea múltiples procesos dentro de un pod
Utilice las capacidades de enlace de contenedores de Kubernetes en lugar de tratar de resolver todos los problemas dentro de un contenedor. Implementa efectivamente múltiples contenedores en un solo pod de Kubernetes. Un buen ejemplo es la subcontratación de funciones de seguridad a un proxy sidecar. contenedor.
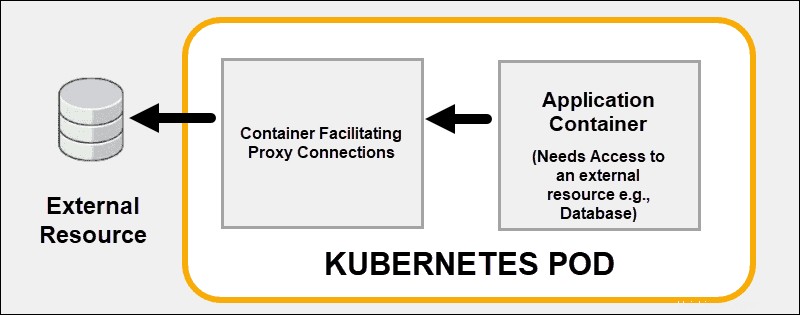
Un contenedor acoplado puede respaldar o mejorar la funcionalidad principal del contenedor principal o ayudar al contenedor principal a adaptarse a su entorno de implementación.
Usar contenedores de inicialización
Uno o más contenedores de inicio generalmente realizan tareas de utilidad o controles de seguridad que no desea incluir en el contenedor de la aplicación principal. Puede usar contenedores init para asegurarse de que un servicio esté listo antes de iniciar el contenedor principal del pod.
Cada contenedor de inicio debe ejecutarse correctamente hasta su finalización antes de que se inicie el contenedor de inicio posterior. Los contenedores de inicio pueden retrasar el inicio del contenedor principal del pod hasta que se cumpla una condición previa. Sin esta condición previa, Kubernetes reinicia el pod. Una vez que se cumple el requisito previo, el contenedor de inicio finaliza automáticamente y permite que se inicie el contenedor principal.
Evite usar la última etiqueta
Abstenerse de usar ninguna etiqueta o :latest etiqueta al implementar contenedores en un entorno de producción. La última etiqueta dificulta determinar qué versión de la imagen se está ejecutando.
Una forma efectiva de asegurarse de que el contenedor siempre use la misma versión de la imagen es usar el resumen de imagen único como etiqueta. En este ejemplo, se implementa una versión de imagen de Redis usando su resumen único:
[email protected]:675hgjfn48324cf93ffg43269ee113168c194352dde3eds876677c5cbKubernetes no actualiza automáticamente la versión de la imagen a menos que cambie el valor de resumen.
Configurar sondeos de disponibilidad y actividad
Animación y pruebas de preparación ayude a Kubernetes a monitorear e interpretar el estado de sus aplicaciones. Si define una comprobación de actividad y un proceso cumple los requisitos, Kubernetes detiene el contenedor e inicia una nueva instancia para ocupar su lugar.
Las sondas de preparación realizan auditorías a nivel de pod y evalúan si un pod puede aceptar tráfico. Si un pod no responde, una sonda de preparación activa un proceso para reiniciar el pod.
La documentación para configurar las sondas de preparación y actividad está disponible en el sitio web oficial de Kubernetes.
Pruebe diferentes tipos de servicios
Al aprender a utilizar diferentes tipos de servicios, puede administrar de manera eficaz el tráfico interno y externo de los pods. Su objetivo es crear un entorno de red estable mediante la administración de puntos finales confiables, como direcciones IP, puertos y DNS.
Puertos estáticos con NodePort
Exponga los pods a usuarios externos configurando el tipo de servicio en NodePort. Si especifica un valor en nodePort Kubernetes reserva ese número de puerto en todos los nodos y reenvía todo el tráfico entrante destinado a los pods que forman parte del servicio. Se puede acceder al servicio mediante la IP interna del clúster y la IP del nodo con el puerto reservado.

Los usuarios pueden ponerse en contacto con el servicio NodePort desde fuera del clúster solicitando:
NodeIP:NodePortUtilice siempre un número de puerto dentro del rango configurado para NodePort (30000-32767). Si una transacción de la API falla, deberá solucionar los posibles conflictos de puertos.
Ingreso frente a LoadBalancer
El tipo LoadBalancer expone servicios externamente utilizando el balanceador de carga de su proveedor. Cada servicio que expone usando el tipo LoadBalancer recibe su IP. Si tiene muchos servicios, es posible que experimente costos adicionales no planificados según la cantidad de servicios expuestos.
Un requisito de configuración estándar es proporcionar un controlador de entrada con una dirección IP pública estática existente. La dirección IP pública estática permanece si se elimina el controlador de ingreso. Este enfoque le permite utilizar los registros de DNS y las configuraciones de red actuales de manera uniforme durante todo el ciclo de vida de sus aplicaciones.
Asignar servicios externos a un DNS
El tipo ExternalName no asigna servicios a un selector, sino que usa un nombre DNS en su lugar. Utilice el externalName parámetro para mapear servicios usando un registro CNAME. Un registro CNAME es un nombre de dominio completo y no una IP numérica.
Los clientes que se conecten al servicio omitirán el proxy del servicio y se conectarán directamente al recurso externo. En este ejemplo, el pnap-service está asignado a admin.phoenixnap.com recurso externo.

Acceso al servicio pnap funciona de la misma manera que con otros servicios. La diferencia crucial es que la redirección ahora ocurre a nivel de DNS.
Diseño de aplicaciones
La implementación automatizada de contenedores con Kubernetes garantiza que la mayoría de las operaciones ahora se ejecuten sin intervención humana directa. Diseñe sus aplicaciones e imágenes de contenedores para que sean intercambiables y no requieran una microgestión constante.
Enfóquese en servicios individuales
Intente dividir su aplicación en varios servicios y evite agrupar demasiada funcionalidad en un solo contenedor. Es mucho más fácil escalar aplicaciones horizontalmente y reutilizar contenedores si se enfocan en hacer una función.
Al crear sus aplicaciones, suponga que sus contenedores son entidades a corto plazo que se detendrán y reiniciarán regularmente.
Usar gráficos Helm
Helm, el administrador de paquetes de aplicaciones de Kubernetes, puede optimizar el proceso de instalación e implementar recursos en todo el clúster muy rápidamente. Los paquetes de aplicaciones de Helm se llaman Charts.
Aplicaciones como MySQL, PostgreSQL, MongoDB, Redis, WordPress son soluciones en demanda. En lugar de crear y editar varios archivos de configuración complejos, puede implementar gráficos de Helm fácilmente disponibles.
Utilice el siguiente comando para crear las implementaciones, los servicios, las reclamaciones de volumen persistente y los secretos necesarios para ejecutar Kafka Manager en su clúster.
helm install --name my-messenger stable/kafka-managerYa no necesita analizar componentes específicos y aprender a configurarlos para ejecutar Kafka correctamente.
Usar afinidad de nodos y pods
La característica de afinidad se utiliza para definir tanto la afinidad de nodos como la afinidad entre pods. La afinidad de nodos le permite especificar los nodos en los que se puede programar un pod mediante el uso de etiquetas de nodos existentes.
- requerido durante la programación Ignorado durante la ejecución – Establece restricciones obligatorias que deben cumplirse para que un pod se programe en un nodo.
- preferido durante la programación ignorado durante la ejecución – Define preferencias que un programador prioriza pero no garantiza.
Si las etiquetas de los nodos cambian durante el tiempo de ejecución y las reglas de afinidad del pod ya no se cumplen, el pod no se elimina del nodo. El nodeSelector El parámetro limita los pods a nodos específicos mediante el uso de etiquetas. En este ejemplo, el pod de Grafana se programará solo en nodos que tengan el ssd etiqueta.
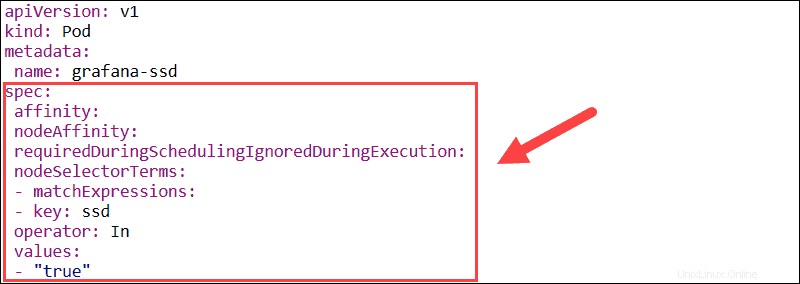
La función de afinidad/antiafinidad del pod amplía los tipos de restricciones que puede expresar. En lugar de usar etiquetas de nodo, puede usar etiquetas de pod existentes para delinear los nodos en los que se puede programar un pod. Esta función le permite establecer reglas para que los pods individuales se programen en función de las etiquetas de otros pods.
Corrupciones y tolerancias de nodos
Kubernetes intenta implementar pods automáticamente en ubicaciones con la menor carga de trabajo. La afinidad de nodos y pods le permite controlar en qué nodo se implementa un pod. Las contaminaciones pueden evitar la implementación de pods en nodos específicos sin alterar los pods existentes. Los pods que desea implementar en un nodo contaminado deben habilitarse para usar el nodo.
- Corrupciones – Evite que se programen nuevos pods en los nodos, defina las preferencias de los nodos y elimine los pods existentes de un nodo.
- Tolerancias – Permita que los pods se programen solo en nodos con Taints existentes y coincidentes.
Tants y Tolerations producen resultados óptimos cuando se usan juntos para garantizar que los pods se programen en los nodos apropiados.
Recursos de grupo con espacios de nombres
Utilice espacios de nombres de Kubernetes para particionar clústeres grandes en grupos más pequeños y fácilmente identificables. Los espacios de nombres le permiten crear entornos independientes de prueba, control de calidad, producción o desarrollo y asignar recursos adecuados dentro de un espacio de nombres único. Los nombres de los recursos de Kubernetes solo deben ser únicos dentro de un único espacio de nombres. Diferentes espacios de nombres pueden tener recursos con el mismo nombre.
Si varios usuarios tienen acceso al mismo clúster, puede limitar a los usuarios y permitirles actuar dentro de los límites de un espacio de nombres específico. Separar a los usuarios es una excelente manera de delimitar los recursos y evitar posibles conflictos de nombres o versiones.
Los espacios de nombres son recursos de Kubernetes y son excepcionalmente fáciles de crear. Cree un archivo YAML que defina el nombre del espacio de nombres y use kubectl para publicarlo en el servidor API de Kubernetes. Posteriormente, puede usar el espacio de nombres para administrar la implementación de recursos adicionales.