Introducción
Un Spark DataFrame es una estructura de datos integrada con una API fácil de usar para simplificar el procesamiento distribuido de big data. DataFrame está disponible para lenguajes de programación de uso general como Java, Python y Scala.
Es una extensión de la API Spark RDD optimizada para escribir código de manera más eficiente sin dejar de ser potente.
Este artículo explica qué es Spark DataFrame, las funciones y cómo usar Spark DataFrame al recopilar datos.

Requisitos previos
- Spark instalado y configurado (Siga nuestra guía:Cómo instalar Spark en Ubuntu, Cómo instalar Spark en Windows 10).
- Un entorno configurado para usar Spark en Java, Python o Scala (esta guía usa Python).
¿Qué es un marco de datos?
Un DataFrame es una abstracción de programación en el módulo Spark SQL. Los marcos de datos se asemejan a tablas de bases de datos relacionales u hojas de cálculo de Excel con encabezados:los datos residen en filas y columnas de diferentes tipos de datos.
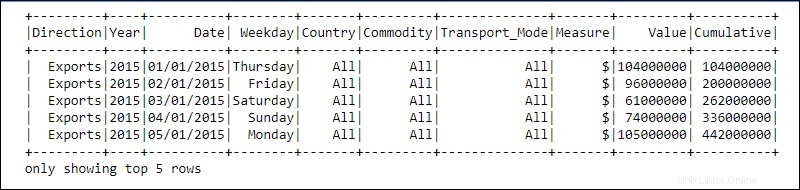
El procesamiento se logra utilizando funciones complejas definidas por el usuario y funciones familiares de manipulación de datos, como ordenar, unir, agrupar, etc.
La información de los datos distribuidos se estructura en esquemas . Cada columna en un DataFrame contiene la columna nombre , tipo de datos, y anulable propiedades. Cuando anulable se establece en verdadero , una columna acepta null propiedades también.

¿Cómo funciona un marco de datos?
La API de DataFrame es parte del módulo Spark SQL. La API proporciona una manera fácil de trabajar con datos dentro del marco Spark SQL mientras se integra con lenguajes de propósito general como Java, Python y Scala.
Si bien existen similitudes con Python Pandas y marcos de datos R, Spark hace algo diferente. Esta API está hecha a medida para integrarse con datos a gran escala para la ciencia de datos y el aprendizaje automático y ofrece numerosas optimizaciones.
Spark DataFrames se pueden distribuir en varios clústeres y se optimizan con Catalyst. El optimizador Catalyst toma consultas (incluidos los comandos SQL aplicados a DataFrames) y crea un plan de cómputo paralelo óptimo.
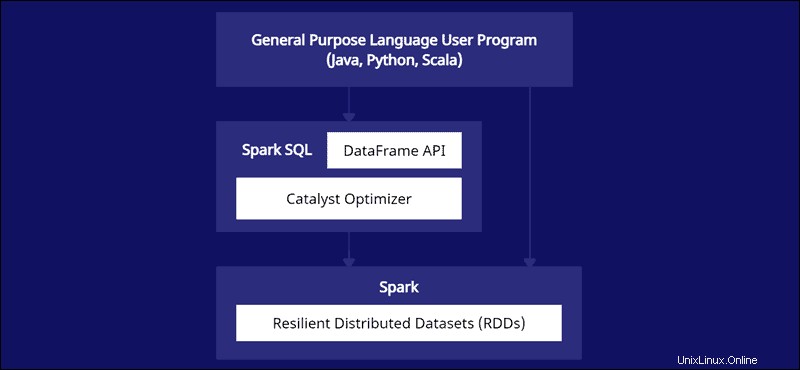
Si tiene experiencia con marcos de datos de Python y R, el código de Spark DataFrame le resultará familiar. Por otro lado, si usa Spark RDD (Conjunto de datos distribuido resistente), tener información sobre la estructura de datos brinda oportunidades de optimización.
Los creadores de Spark diseñaron DataFrames para enfrentar los desafíos de big data de la manera más eficiente. Los desarrolladores pueden aprovechar el poder de la computación distribuida con API familiares pero más optimizadas.
Características de Spark DataFrames
Spark DataFrame viene con muchas características valiosas:
- Compatibilidad con varios formatos de datos, como Hive, CSV, XML, JSON, RDD, Cassandra, Parquet, etc.
- Soporte para la integración con varias herramientas de Big Data.
- La capacidad de procesar kilobytes de datos en máquinas más pequeñas y petabytes en clústeres.
- Optimizador de Catalyst para un procesamiento de datos eficiente en varios idiomas.
- Manejo de datos estructurados a través de una vista esquemática de los datos.
- Administración de memoria personalizada para reducir la sobrecarga y mejorar el rendimiento en comparación con los RDD.
- API para Java, R, Python y Spark.
¿Cómo crear un marco de datos Spark?
Hay varios métodos para crear un Spark DataFrame. Aquí hay un ejemplo de cómo crear uno en Python usando el entorno de cuaderno Jupyter:
1. Inicializar y crear una sesión API:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. Cree datos de juguetes como una lista de diccionarios:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
3. Cree el DataFrame usando createDataFrame función y pasar los data lista:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. Imprima el esquema y la tabla para ver el DataFrame creado:
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()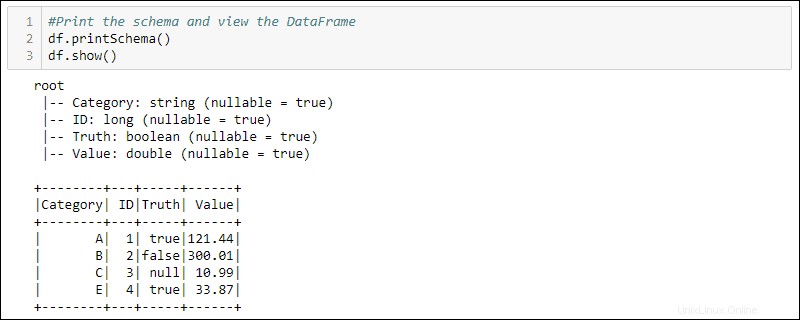
Cómo utilizar marcos de datos
Los datos estructurados almacenados en un DataFrame proporcionan dos métodos de manipulación
- Uso de lenguaje específico del dominio
- Uso de consultas SQL.
Los siguientes dos métodos usan el marco de datos del ejemplo anterior para seleccionar todas las filas donde la columna Verdad está configurada como verdadera y ordenar los datos por la columna Valor.
Método 1:uso de consultas específicas de dominio
Python proporciona métodos integrados para filtrar y clasificar los datos. Seleccione la columna específica usando df.<column name> :
df.filter(df.Truth == True).sort(df.Value).show()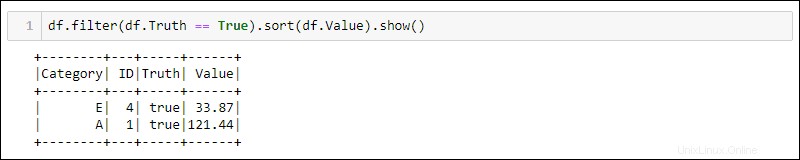
Método 2:Uso de consultas SQL
Para usar consultas SQL con DataFrame, cree una vista con createOrReplaceTempView método incorporado y ejecute la consulta SQL usando spark.sql método:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')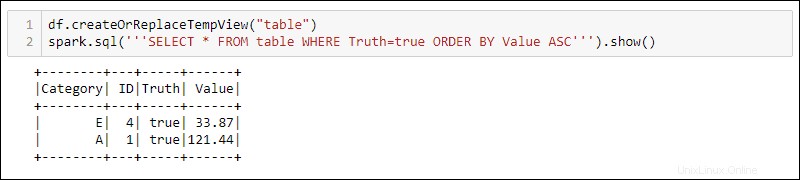
El resultado muestra los resultados de la consulta SQL aplicados a la vista temporal del DataFrame. Esto permite crear múltiples vistas y consultas sobre los mismos datos para el procesamiento de datos complejos.