Introducción
Con tantas opciones disponibles, puede ser un desafío elegir una solución de base de datos que se adapte perfectamente a sus necesidades. Cuando se trata de tipos de bases de datos, una opción popular es una base de datos relacional.
En este artículo, cubriremos la estructura de las bases de datos relacionales, cómo funcionan y las ventajas y desventajas de usarlas. También usaremos ejemplos para ilustrar cómo las bases de datos relacionales organizan los datos.

Definición de base de datos relacional
Una base de datos relacional es un tipo de base de datos que se centra en la relación entre los elementos de datos almacenados. Permite a los usuarios establecer vínculos entre diferentes conjuntos de datos dentro de la base de datos y usar estos vínculos para administrar y hacer referencia a datos relacionados.
Muchas bases de datos relacionales usan SQL (Lenguaje de consulta estructurado) para realizar consultas y mantener datos.
Bases de datos relacionales y no relacionales
Las bases de datos relacionales se centran en las relaciones entre los datos. Por lo tanto, la base de datos de relaciones necesita almacenar datos de una manera altamente estructurada. Esto permite una indexación más rápida y tiempos de respuesta de consulta y hace que los datos sean más seguros y consistentes.
Por otro lado, las bases de datos NoSQL no necesitan depender tanto de la estructura, lo que les permite almacenar grandes cantidades de datos, permanecer flexibles y escalar fácilmente el almacenamiento y el rendimiento.
¿Cómo se organizan los datos en un sistema de base de datos relacional?
Los sistemas de bases de datos relacionales utilizan un modelo que organiza los datos en tablas de filas (también llamado registros o tuplas ) y columnas (también llamados atributos o campos ). Generalmente, las columnas representan categorías de datos, mientras que las filas representan instancias individuales.
Usemos una tienda digital como ejemplo. Nuestra base de datos puede tener una tabla que contenga información del cliente, con columnas que representen nombres o direcciones de clientes, mientras que cada fila contiene datos para un cliente individual.

Estas tablas se pueden vincular o relacionar usando teclas . Cada fila de una tabla se identifica mediante una clave única, denominada clave principal. Esta clave principal se puede agregar a otra tabla, convirtiéndose en una clave externa. La relación clave primaria/foránea constituye la base del funcionamiento de las bases de datos relacionales.
Volviendo a nuestro ejemplo, si tenemos una tabla que representa pedidos de productos, una de las columnas podría contener información del cliente. Aquí, podemos importar una clave principal que se vincula a una fila con la información de un cliente específico.
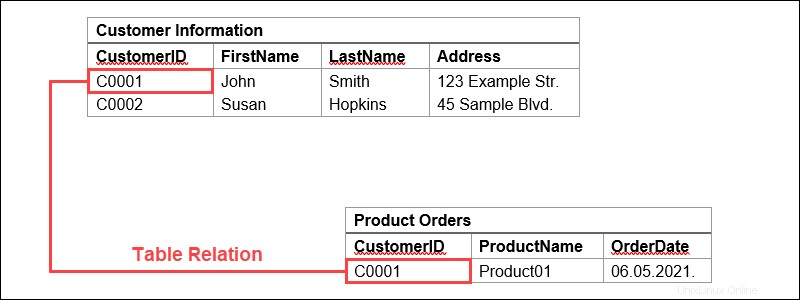
De esta manera, podemos referenciar los datos o duplicar datos de la tabla de información del cliente. También significa que estas dos tablas ahora están relacionadas.
Ejemplos de bases de datos relacionales
Ahora que hemos cubierto cómo funcionan, estos son algunos de los ejemplos más populares de bases de datos relacionales:
MySQL

MySQL se desarrolló como un sistema de gestión de código abierto para bases de datos relacionales hasta que fue adquirido por Sun Microsystems (ahora Oracle Corporation). Todavía está disponible bajo una licencia de código abierto, con la adición de diferentes licencias propietarias.
MySQL cuenta con soporte de replicación incorporado con cumplimiento de ACID, agrupación en clústeres sin nada compartido y admite múltiples motores de almacenamiento. Sin embargo, el uso de algunos motores de almacenamiento puede hacer que SQL no funcione correctamente.
MySQL sobresale en la entrada de datos rápida y escalabilidad mientras mantiene una alta disponibilidad y rendimiento. Esto lo hace extremadamente útil para el desarrollo web y de aplicaciones.
PostgreSQL

PostgreSQL es un administrador de base de datos relacional gratuito disponible bajo una licencia de código abierto. Comparte algunas características con MySQL, con la notable adición de MVCC (control de concurrencia de múltiples versiones), lo que lo hace compatible con ACID.
PostgreSQL conserva un alto nivel de rendimiento y flexibilidad, incluso cuando maneja grandes bases de datos. Es la elección correcta para los usuarios que necesitan altas velocidades de lectura/escritura y análisis de datos extensos.
Algunos usuarios notables de PostgreSQL incluyen Reddit, Skype e Instagram.
MariaDB

MariaDB comenzó como una bifurcación de MySQL impulsada por la comunidad después de que Oracle comprara este último. Todavía es de código abierto, disponible bajo la Licencia Pública General GNU.
MariaDB se basa en la base de MySQL agregando soporte para aún más motores de almacenamiento y corrigiendo las limitaciones del motor de almacenamiento. Esto le permite funcionar incluso más rápido que MySQL y ejecutar tanto SQL como NoSQL en una única base de datos.
Entre los usuarios notables de MariaDB se incluyen Google, Mozilla y la Fundación Wikimedia.
SQLite

A diferencia de otras entradas en esta lista, SQLite no es un administrador de base de datos cliente-servidor, sino que está integrado en la aplicación final. Esto lo hace liviano y capaz de trabajar con una amplia variedad de sistemas y plataformas.
También causa algunas limitaciones, ya que SQLite solo proporciona disparadores parcialmente, tiene un ALTER TABLE limitado y no puede escribir en las vistas. También limita el tamaño máximo de la base de datos a 32.000 columnas y 140 TB.
Por lo tanto, SQLite se utiliza mejor como componente de base de datos para otras aplicaciones. Los usos notables incluyen navegadores populares, como Google Chrome, Mozilla Firefox, Opera y Safari.
¿Qué es el sistema de gestión de bases de datos relacionales?
Un sistema de gestión de bases de datos (DBMS) es una solución de software que ayuda a los usuarios a ver, consultar y administrar bases de datos.
Sistemas de gestión de bases de datos relacionales (RDBMS) son un subconjunto más avanzado de DBMS, que manejan bases de datos relacionales.
SGBD frente a RDBMS
Estas son algunas de las diferencias entre las soluciones DBMS más generales y RDBMS:
| SGBD | RDBMS |
| Almacena pequeñas cantidades de datos como archivos, sin relaciones. | Almacena grandes cantidades de datos como tablas que están relacionadas entre sí. |
| Solo puede acceder a un elemento de datos a la vez. | Puede acceder a múltiples elementos de datos al mismo tiempo. |
| Trabajar con grandes cantidades de datos hace que la recuperación sea más lenta. | El enfoque relacional permite que la obtención de datos siga siendo rápida incluso para bases de datos grandes. |
| Sin normalización de base de datos. | Permite la normalización de la base de datos. |
| No admite bases de datos distribuidas. | Admite bases de datos distribuidas. |
| Admite un solo usuario. | Admite múltiples usuarios. |
| Nivel de seguridad más bajo. | Múltiples niveles de seguridad. |
| Bajos requisitos de software y hardware. | Altos requisitos de software y hardware. |