Introducción
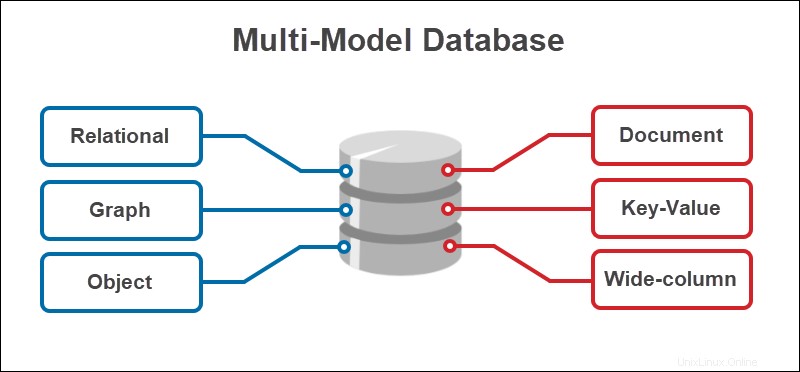
Base de datos multimodelo Los sistemas de gestión unifican varios sistemas de bases de datos en uno solo. En lugar de trabajar con numerosos modelos y encontrar formas de incorporarlos, las bases de datos multimodelo proporcionan un motor único para varios tipos de bases de datos.
Este artículo brinda una descripción detallada de las bases de datos multimodelo.

¿Qué es una base de datos multimodelo?
Una base de datos multimodelo es un sistema de gestión que combina múltiples tipos de bases de datos con un backend único. La mayoría de los sistemas de administración de bases de datos solo admiten un único modelo de base de datos. Por otro lado, las bases de datos multimodelo almacenan, consultan e indexan datos de diferentes modelos.
Las bases de datos multimodelo brindan las ventajas de modelado de la persistencia políglota sin tener que buscar formas de combinar diferentes modelos. El enfoque flexible permite almacenar datos de diferentes maneras. El resultado es:
- Programación ágil y flexible.
- Redundancia de datos reducida.
Por ejemplo, explorar las relaciones entre los puntos de datos o crear un sistema de recomendaciones es mucho más fácil con las bases de datos de gráficos. Por otro lado, las bases de datos relacionales ayudan a definir relaciones entre columnas de datos.
Una característica vital de la base de datos multimodelo es la capacidad de transformar datos de un formato a otro. Por ejemplo, los datos en formato JSON se transforman rápidamente en XML. La conversión de formatos de datos proporciona agilidad adicional y facilita el cumplimiento de los requisitos específicos del proyecto.
Ejemplos de casos de uso de bases de datos multimodelo
Los casos de uso ayudan a dar una idea de cómo funcionan las bases de datos multimodelo. El análisis de ejemplos prácticos proporciona una mejor comprensión de cómo varios modelos funcionan juntos en un sistema.
Almacenamiento y administración de múltiples fuentes de datos
Un sistema de TI típico utiliza varias fuentes de datos. La información almacenada no siempre está en el mismo formato o base de datos. Los múltiples formatos crean un sistema complejo, lo que dificulta el mantenimiento y la búsqueda de datos.
El almacenamiento de datos en una base de datos multimodelo facilita la administración. Todo está en una base de datos, lo que reduce el tiempo necesario para almacenar y administrar datos de diferentes fuentes.
Ampliar las características del modelo
Las bases de datos multimodelo proporcionan extensiones entre modelos. Las características de algunos modelos ayudan a complementar las deficiencias de otros modelos.
Por ejemplo, consultar datos en formato JSON mediante consultas SQL es sencillo. No es necesario ajustar la fuente de datos original. La extensibilidad reduce el tiempo de procesamiento de datos y elimina la necesidad de sistemas de extracción, transformación y carga (ETL).
Entornos de datos híbridos
Un entorno de datos típico mantiene los datos operativos separados de los analíticos. Los datos para análisis deben ser transformados y almacenados en un lugar diferente al de los datos operativos.
La información se duplica, disminuyendo la calidad de los datos. Asimismo, el espacio separado genera gastos generales de mantenimiento. Ambas bases de datos necesitan administración de políticas y administración de copias de seguridad.
Una base de datos multimodelo proporciona un enfoque híbrido para el almacenamiento de datos. Un centro de datos unificado para almacenar datos transaccionales y analíticos es más fácil de mantener.
Centralización de datos
Los datos dentro de una organización tienen barreras. Si bien deben existir restricciones, este enfoque impide utilizar información dentro de una empresa.
Las bases de datos multimodelo almacenan datos tal cual sin necesidad de transformaciones. La centralización de datos proporciona información valiosa sobre los datos existentes, así como la oportunidad de crear nuevos casos de uso.
Búsqueda de datos masivos
Hadoop es excepcional en el procesamiento de grandes cantidades de datos diversos en diferentes modelos. La razón principal es la velocidad de recepción, procesamiento y almacenamiento de diversos datos. Sin embargo, lo único que le falta a Hadoop es un mecanismo de búsqueda eficiente.
Aprovechar el poder de procesamiento de Hadoop y combinarlo con la fuerza de las búsquedas en bases de datos de modelos múltiples produce un sistema sólido. El proceso de trabajar con datos se vuelve escalable y robusto para tareas de big data.
Ventajas y desventajas de la base de datos multimodelo
Las bases de datos multimodelo tienen ventajas y desventajas. La tabla proporciona el resumen:
| Ventajas | Contras |
|---|---|
| Coherencia de datos | Complejo |
| Ágil | Desarrollo |
| Cumple con ACID | Carece de técnicas de modelado |
| Adecuado para proyectos complejos | No apto para proyectos simples |