Introducción
Una de las mayores amenazas para las bases de datos modernas es la pérdida de datos debido a fallas de hardware o ransomware. Las bases de datos distribuidas ofrecen una solución mediante la replicación de datos en diferentes ubicaciones físicas.
La replicación de bases de datos permite distribuir partes de una base de datos entre múltiples nodos.
En este tutorial, cubriremos cómo funciona la replicación de datos, cuándo usarla, diferentes tipos y esquemas de replicación y herramientas que ayudan a replicar una base de datos.

¿Qué es la replicación de bases de datos?
Replicación de bases de datos es el proceso de copiar datos y almacenarlos en diferentes ubicaciones. Realizar la replicación de datos garantiza que haya una copia coherente de la base de datos en todos los nodos de un sistema distribuido. Esto sirve para que los datos estén ampliamente disponibles y protegerlos de la pérdida de datos.
Los datos replicados pueden ser completos o parcial instantánea y se puede almacenar en el sitio, fuera del sitio o en un entorno de nube. En caso de tiempo de inactividad, las organizaciones recuperan datos y mantienen la continuidad del negocio mediante la restauración desde una ubicación de copia de seguridad.
Los datos se replican sincrónicamente o asincrónicamente :
- Replicación síncrona . Los datos se escriben simultáneamente en la base de datos principal y todas sus réplicas.
- Replicación asíncrona . Los datos se escriben primero en la base de datos principal y luego se copian en las réplicas.
Tipos de replicación de bases de datos
Hay varios métodos diferentes para replicar una base de datos. Las organizaciones deben elegir una técnica basada en el propósito de los datos replicados y cómo pretenden acceder a ellos.
Replicación de instantáneas
Replicación de instantáneas copia una "instantánea" de la base de datos, exactamente como aparece en el momento en que comienza el proceso de replicación. No supervisa los cambios o actualizaciones de los datos.
La replicación de instantáneas es útil cuando los datos no cambian con frecuencia, pero también si hay cambios significativos en poco tiempo. Cualquier cambio en la base de datos hace que una instantánea quede obsoleta hasta que se replique una nueva.
Replicación transaccional
Replicación transaccional crea una copia completa de la base de datos, con nuevos datos ingresando a medida que cambia la base de datos. Los datos se copian en tiempo real en el orden de los cambios realizados, lo que garantiza la coherencia.
Lo mejor es utilizar la replicación transaccional para garantizar cambios incrementales en tiempo real en los datos. Esto mejora el rendimiento y reduce la latencia al mismo tiempo que proporciona un alto volumen de actividad de lectura, escritura y eliminación.
Combinar replicación
Combinar replicación combina datos de varias fuentes en una sola base de datos. El uso de la replicación combinada permite que varios usuarios cambien los datos y apliquen todos los cambios a la nueva réplica.
La replicación de mezcla ayuda a descubrir y abordar rápidamente los cambios conflictivos. También permite a los usuarios realizar cambios sin conexión antes de sincronizar con el servidor.
Replicación heterogénea
Replicación heterogénea se utiliza para replicar datos entre servidores suministrados por diferentes proveedores. Por ejemplo, le permite copiar datos de un servidor SQL a un servidor que no sea SQL.
Replicación transaccional punto a punto
Replicación punto a punto se basa en la replicación transaccional. Permite que todos los usuarios y servidores participantes se envíen datos entre sí para que las actualizaciones se realicen casi en tiempo real.
La replicación punto a punto es especialmente útil para aplicaciones web. Su flexibilidad ayuda a escalar la cantidad de usuarios sin afectar el rendimiento. También hace que el sistema sea más robusto, lo que permite que los servidores se apaguen para realizar tareas de mantenimiento.
Esquemas de replicación de bases de datos
Los siguientes esquemas de replicación se utilizan para la replicación de bases de datos:
Replicación completa
Realizar una replicación completa significa copiar la base de datos completa a cada nodo del sistema distribuido. Este enfoque maximiza la redundancia de datos, aumenta el rendimiento global y la disponibilidad de datos. Los datos están disponibles siempre que un nodo sea funcional.
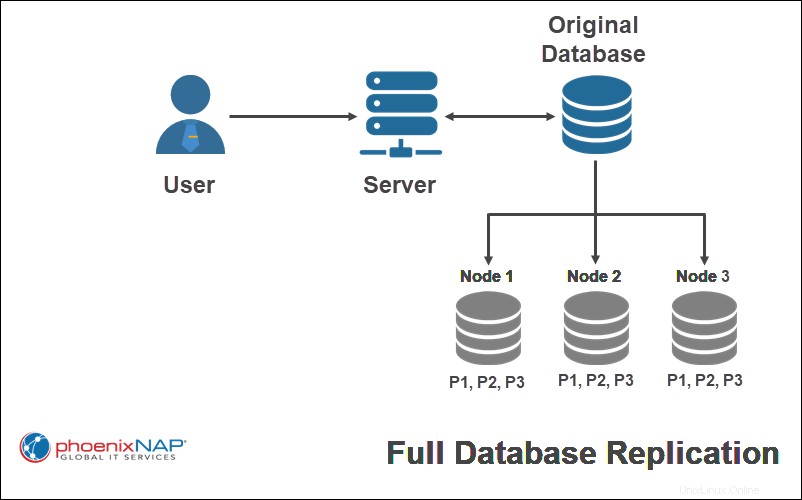
En el ejemplo anterior, todas las partes de la base de datos original (P1, P2, P3) se replican completamente en todos los sitios.
La replicación completa tarda más en realizarse, ya que la actualización debe replicarse en todos los sitios. Además, los costos de almacenar instantáneas de datos completos en múltiples ubicaciones pueden sumarse.
Replicación parcial
Copiar solo ciertas partes de una base de datos es replicación parcial . Por lo general, esto se decide según la importancia de tener los datos disponibles en cada ubicación.
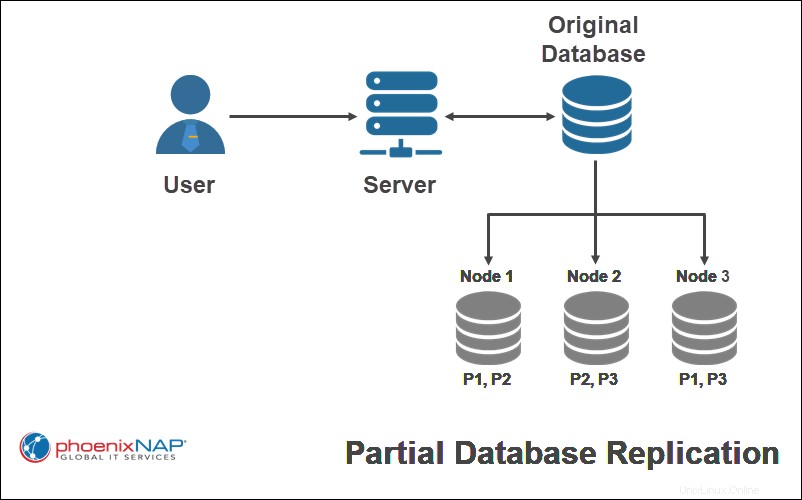
En el ejemplo anterior, solo ciertas partes de la base de datos original (P1, P2, P3) se replican en un solo nodo.
Cuando se utiliza un esquema de replicación parcial, el número de copias para cada parte de la base de datos puede variar desde uno hasta el número total de nodos en el sistema distribuido.
Sin replicación
Sin sin replicación , cada nodo en un sistema distribuido solo recibe una copia de una parte de la base de datos. Este esquema de replicación es el más rápido de realizar, pero tiende a reducir la disponibilidad de datos y deja la base de datos vulnerable a la pérdida de datos. Sin embargo, la concurrencia es fácil de lograr.
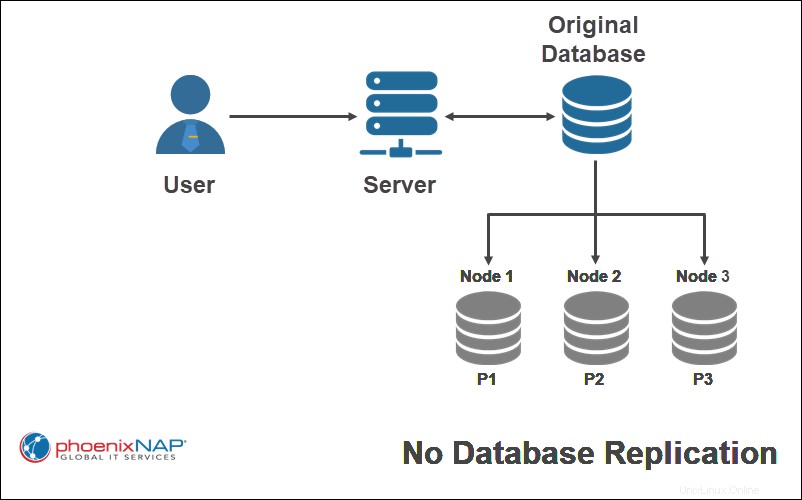
En el ejemplo anterior, solo se replica un único fragmento de la base de datos original en un nodo específico.
Software y herramientas de replicación de bases de datos
Muchas herramientas de administración de bases de datos ofrecen formas de realizar la replicación de bases de datos. También hay herramientas de replicación de terceros que ofrecen las mismas funciones.
Las herramientas de terceros pueden incluso ser más flexibles, ya que la mayoría le permite replicar en múltiples tipos de bases de datos. Estos son algunos de los ejemplos más populares:
- Copia de seguridad y restauración de datos de phoenixNAP. phoenixNAP ofrece múltiples opciones y soluciones de copia de seguridad, incluida la integración de Veeam, la copia de seguridad de la base de datos en la nube, la copia de seguridad administrada para Office 365 y DRaaS (Recuperación ante desastres como servicio).
- Copia de seguridad y replicación de Veeam . Veeam trabaja con diferentes tipos de bases de datos, incluidas bases de datos en la nube, virtuales, Kubernetes y distribuciones físicas. Ofrece protección continua de datos, replicación avanzada y conmutación por error para recuperación ante desastres y recuperación instantánea para administradores de bases de datos populares, como NAS, Microsoft SQL y Oracle.
- Copia de seguridad cibernética de Acronis . Acronis es compatible con más de 20 plataformas de bases de datos y ofrece funciones de seguridad avanzadas, como la prevención de ransomware basada en IA.
- Copia de seguridad y replicación de NAKIVO . NAKIVO ofrece funciones como soporte para aplicaciones en vivo, recuperación a nivel de archivos y objetos, deduplicación global e informes automáticos. Puede replicar datos localmente, en un servidor remoto o en la nube.
- Carbonite Safe Backup. Carbonite está orientado a empresas más pequeñas. Ofrece copias de seguridad automáticas en la nube y del disco duro, copias de seguridad de imágenes y restauración completa, y replicación de bases de datos en niveles superiores.
Ventajas de la replicación de datos
El uso de la replicación de la base de datos ayuda:
- Garantice la continuidad del negocio con un plan de recuperación ante desastres. En caso de falla del hardware o un ataque de ransomware, contar con la replicación de datos como parte de su plan de recuperación ante desastres garantiza que haya una copia externa del sistema. Eso permite a las organizaciones restaurar datos y mantener la continuidad del negocio.
- Mejora el rendimiento. Tener los mismos datos en varias ubicaciones significa que un usuario puede recuperar datos del servidor más cercano, lo que reduce la latencia de la red y aumenta el rendimiento.
- Mejorar el soporte multiusuario. La replicación de datos ayuda con la ejecución de consultas, especialmente cuando varios usuarios acceden a la base de datos.
- Mejore los análisis. Tener una copia separada y completa de una base de datos permite que un equipo realice análisis sin afectar el rendimiento.
- Mejorar la disponibilidad. Varios usuarios pueden acceder y administrar datos en una base de datos distribuida sin interponerse entre sí.
Desventajas de la replicación de datos
La replicación de datos plantea varios desafíos:
- Puede requerir mucho espacio de almacenamiento, especialmente para replicaciones completas. Esto puede generar altos costos o reducir el rendimiento si es necesario actualizar muchas réplicas simultáneamente.
- Mantener la coherencia de los datos es difícil cuando se utilizan métodos como la fusión o la replicación punto a punto.