Imagine que tiene un archivo (o un grupo de archivos) y desea buscar una cadena específica o una configuración dentro de estos archivos. Abrir cada archivo individualmente y tratar de encontrar la cadena específica sería tedioso y probablemente no sea el enfoque correcto. Entonces, ¿qué podemos usar?
Hay muchas herramientas que podemos usar en los sistemas basados en *nix para buscar y manipular texto. En este artículo, cubriremos el grep Comando para buscar patrones, ya sea que se encuentren en archivos o que provengan de una transmisión (un archivo o una compilación de entrada de una canalización, o | ). En un próximo artículo, también veremos cómo usar sed (Stream Editor) para manipular una transmisión.
La mejor manera de comprender el funcionamiento de un programa o utilidad es consultar su página de manual. Muchas (si no todas) las herramientas de Unix proporcionan páginas man durante la instalación. En los sistemas basados en Red Hat Enterprise Linux, podemos ejecutar lo siguiente para enumerar grep Archivos de documentación de:
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
Con las páginas man a nuestra disposición, ahora podemos usar grep y explora sus opciones.
grep básicos
Durante esta parte del artículo, usamos las words archivo, que puede encontrar en la siguiente ubicación:
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
Este archivo contiene 479.826 palabras y lo proporciona words paquete. En mi sistema Fedora, ese paquete es words-3.0-33.fc30.noarch . Cuando listamos el contenido de las words archivo, vemos el siguiente resultado:
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
Bien, dijimos las words El archivo contenía 479.826 líneas, pero ¿cómo sabemos eso? Recuerde, antes hablamos de las páginas del manual. A ver si grep ofrece una opción para contar líneas en un archivo dado.
Irónicamente, usaremos grep para grep para la opción de la siguiente manera:

Entonces, obviamente necesitamos -c , o la opción larga --count , para contar el número de líneas en un archivo dado. Contando las líneas en /usr/share/dict/words rendimientos:
$ grep -c '.' /usr/share/dict/words
479826
El '.' significa que contaremos todas las líneas que contengan al menos un carácter, espacio, espacio en blanco, tabulador, etc.
Básico grep expresiones regulares
El grep El comando se vuelve más poderoso cuando usamos expresiones regulares (regexes). Entonces, mientras nos enfocamos en el grep comando en sí mismo, también tocaremos la sintaxis básica de expresiones regulares.
Supongamos que solo nos interesan las palabras que comienzan con Z . Esta situación es donde las expresiones regulares son útiles. Usamos el quilate (^ ) para buscar patrones que comiencen con un carácter específico, que indica el comienzo de una cadena:
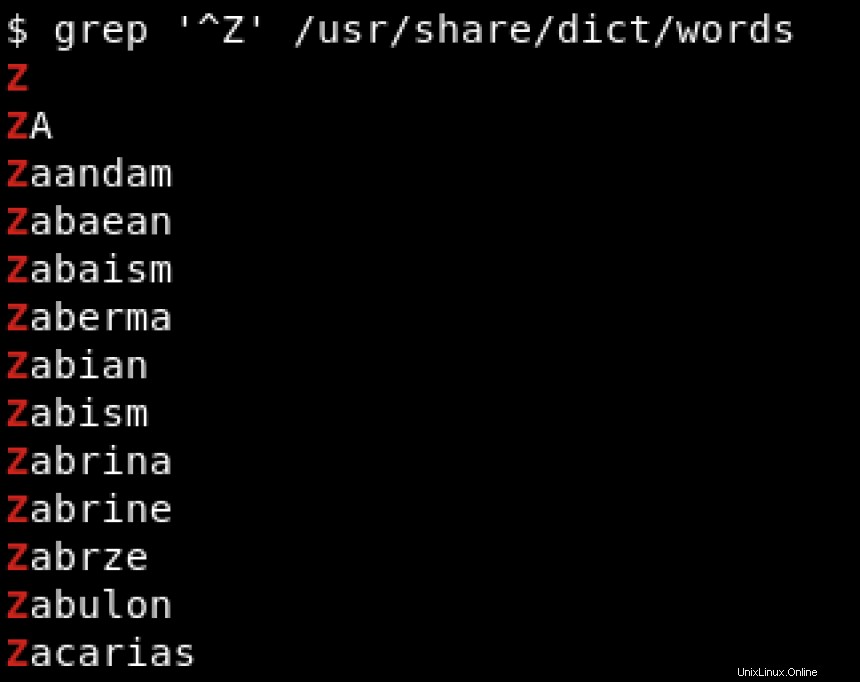
Para buscar patrones que terminan con un carácter específico, usamos el signo de dólar ($ ) para indicar el final de la cadena. Vea el ejemplo a continuación donde buscamos cadenas que terminen con hat :
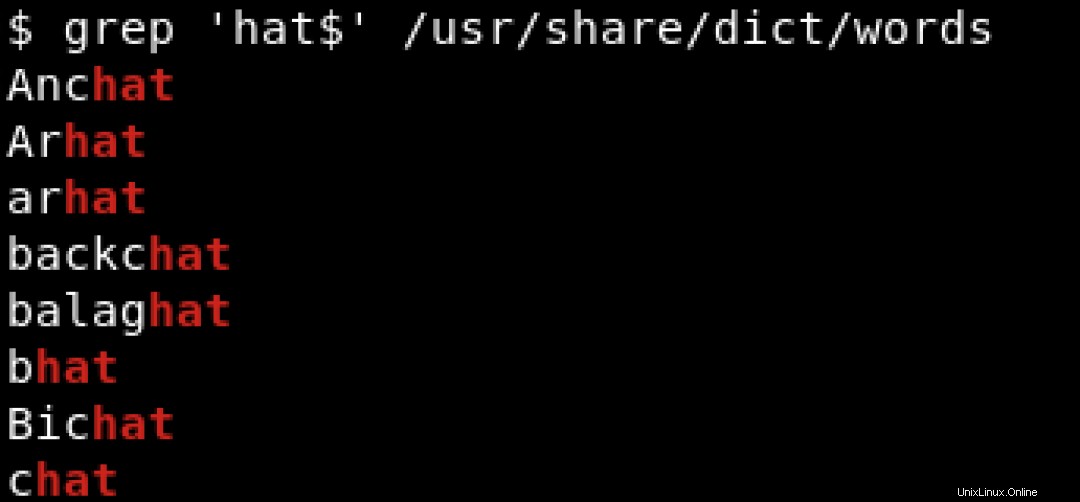
Para imprimir todas las líneas que contienen hat independientemente de su posición, ya sea al principio o al final de la línea, usaríamos algo como:
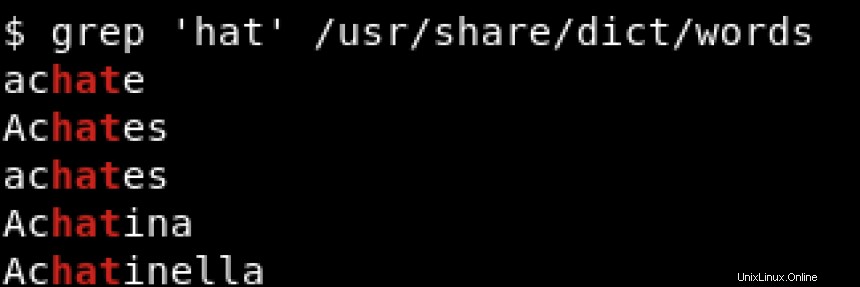
El ^ y $ se denominan metacaracteres y deben escaparse con una barra invertida (\ ) cuando queremos hacer coincidir estos caracteres literalmente. Si desea obtener más información sobre los metacaracteres, consulte https://www.regular-expressions.info/characters.html.
Ejemplo:Eliminar comentarios
Ahora que hemos arañado la superficie de grep , trabajemos en algunos escenarios del mundo real. Muchos archivos de configuración en *nix contienen comentarios, que describen diferentes configuraciones dentro del archivo de configuración. El /etc/fstab , archivo por ejemplo, tiene:
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
Los comentarios están marcados por el hash (# ), y queremos ignorarlos cuando se impriman. Una opción es el cat comando:
$ cat /etc/fstab | grep -v '^#'
Sin embargo, no necesitas cat aquí (evite el uso inútil de Cat). El grep El comando es perfectamente capaz de leer archivos, por lo que en su lugar, puede usar algo como esto para ignorar las líneas que contienen comentarios:
$ grep -v '^#' /etc/fstab
Si desea enviar la salida (sin comentarios) a otro archivo, usaría:
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
Mientras que grep puede formatear la salida en la pantalla, este comando no puede modificar un archivo en su lugar. Para hacer esto, necesitaríamos un editor de archivos como ed . En el próximo artículo, usaremos sed para lograr lo mismo que hicimos aquí con grep .
Ejemplo:Eliminar comentarios y líneas vacías
Mientras todavía estamos en grep , examinemos el /etc/sudoers expediente. Este archivo contiene muchos comentarios, pero solo nos interesan las líneas que no tienen comentarios y también queremos deshacernos de las líneas vacías.
Entonces, primero, eliminemos las líneas que contienen los comentarios. Se produce el siguiente resultado:
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
Ahora, queremos deshacernos de las líneas en blanco (vacías). Bueno, eso es fácil, solo ejecuta otro grep comando:
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
¿Podríamos hacerlo mejor? ¿Podríamos ejecutar nuestro grep comando para ser más amigable con los recursos y no bifurcar grep ¿dos veces? Ciertamente podemos:
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
Aquí presentamos otro grep opción, -E (o --extended-regexp ) <PATTERN> es una expresión regular extendida.
Ejemplo:Imprimir solo /etc/passwd usuarios
Es obvio que grep es poderoso cuando se usa con expresiones regulares. Este artículo cubre simplemente una pequeña porción de lo que grep es realmente capaz de. Para demostrar las capacidades de grep y el uso de expresiones regulares, analizaremos el /etc/passwd archivar e imprimir solo los nombres de usuario.
El formato del /etc/passwd archivo es el siguiente:
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
Los campos anteriores tienen el siguiente significado:
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
Ver man 5 passwd para obtener más información sobre /etc/passwd expediente. Para imprimir solo los nombres de usuario, podríamos usar algo como lo siguiente:
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
En el grep anterior comando, introdujimos otra opción:-o (o --only-matching ) para mostrar solo la parte de una línea que coincide con <PATTERN> . Luego, combinamos -Eo para obtener el resultado deseado.
Ahora dividiremos el comando anterior para que podamos comprender mejor lo que realmente está sucediendo. De izquierda a derecha:
^coincidencias al principio de la línea.[a-zA-Z_-]se denomina clase de carácter y coincide con una lista incluida de coincidencia de un solo carácter.+es un cuantificador que coincide entre uno y un número ilimitado de veces.
La expresión regular anterior se repetirá hasta que alcance un carácter que no coincida. La primera línea del archivo es:
root:x:0:0:root:/root:/bin/bash
Se procesa de la siguiente manera:
- El primer carácter es una
r, por lo que coincide con[a-z]. - El
+pasa al siguiente carácter. - El segundo carácter es un
oy esto coincide con[a-z]. - El
+pasa al siguiente carácter.
Esta secuencia se repite hasta que llegamos a los dos puntos (: ). La clase de carácter [a-zA-Z_-] no coincide con el : símbolo, entonces grep pasa a la siguiente línea.
Dado que los nombres de usuario en passwd están todos en minúsculas, también podríamos simplificar nuestra clase de caracteres de la siguiente manera y aun así obtener el resultado deseado:
$ grep -Eo '^[a-z_-]+' /etc/passwd
Ejemplo:Buscar un proceso
Al usar ps para grep para un proceso, a menudo usamos algo como:
$ ps aux | grep ‘thunderbird’
Pero el ps El comando no solo listará el thunderbird proceso. También enumera el grep comando que acabamos de ejecutar también, ya que grep también se ejecuta después de la canalización y se muestra en la lista de procesos:
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
Podemos manejar esto agregando grep -v grep para excluir grep de la salida:
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
Mientras usa grep -v grep hará lo que queríamos, existen mejores formas de lograr el mismo resultado sin bifurcar un nuevo grep proceso:
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
El [t]hunderbird aquí coincide con el literal t , y distingue entre mayúsculas y minúsculas. No coincidirá con grep , y es por eso que ahora solo vemos thunderbird en la salida.
Este ejemplo es solo una demostración de cuán flexible grep es, no le ayudará a solucionar los problemas de su árbol de procesos. Hay mejores herramientas adecuadas para este propósito, como pgrep .
Resumen
Usa grep cuando desee buscar un patrón, ya sea en un archivo o en varios directorios de forma recursiva. Intenta entender cómo funcionan las expresiones regulares cuando grep , ya que las expresiones regulares pueden ser poderosas.
[¿Quiere probar Red Hat Enterprise Linux? Descárguelo ahora gratis.]