Una vez que ingrese al dominio del sistema operativo Linux, la lista de posibilidades informáticas a través del entorno de línea de comandos de Linux parecerá interminable. Es simplemente porque cuanto más usa Linux, más quiere aprender y este anhelo lo lleva a través de innumerables oportunidades de aprendizaje.
En este tutorial, veremos contar e imprimir líneas duplicadas en un archivo de texto en un entorno de sistema operativo Linux. Este módulo tutorial es parte de la administración de archivos de Linux.
La línea de comandos o el entorno de terminal de Linux no es nuevo en el procesamiento de archivos de texto de entrada. Es tan competente en este tipo de operaciones que aún no se ha enfrentado a un desafío digno en el procesamiento de archivos de texto.
Este tutorial arrojará algo de luz sobre la identificación/manejo de líneas duplicadas dentro de archivos de texto aleatorios en Linux.
Enunciado del problema
Para hacer este tutorial más fácil e interesante, vamos a crear un archivo de texto de muestra que actuará como el archivo aleatorio en el que queremos verificar la existencia de líneas duplicadas.
$ sudo nano sample_file.txt
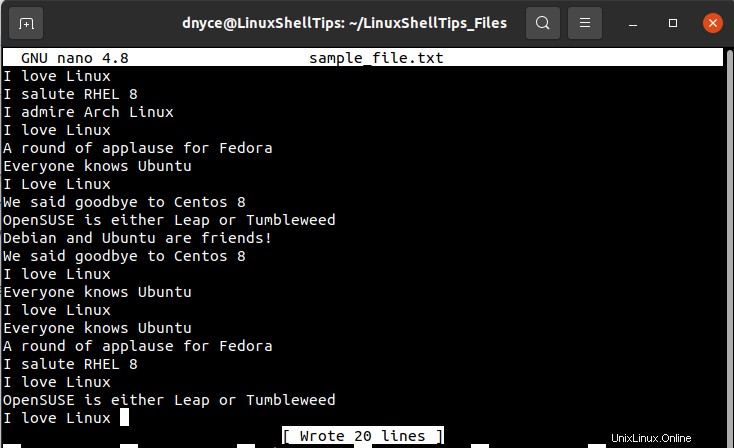
Con solo escanear la captura de pantalla del archivo de texto anterior, deberíamos poder notar la existencia de algunas líneas duplicadas, pero no podemos estar seguros de su número exacto de ocurrencias.
Para estar seguros de la cantidad de líneas duplicadas que se producen, encontraremos nuestras soluciones a partir de los siguientes enfoques basados en terminal/línea de comandos de Linux:
Encuentre líneas duplicadas en un archivo usando los comandos sort y uniq
La conveniencia de usar el uniq comando es que viene con -c opción de comando. Sin embargo, esta opción de comando solo es válida si el archivo de texto que está buscando/explorando tiene líneas adyacentes duplicadas.
Para evitar este inconveniente al usar el uniq comando para imprimir líneas duplicadas, tenemos que tomar prestado el enfoque del comando de clasificación de agrupar líneas repetidas/duplicadas dentro de un archivo de texto específico.
En resumen, primero pasaremos el archivo de texto de destino a través de ordenar comando y luego canalizarlo al uniq comando que luego estará acompañado por el -c opción de comando como se muestra a continuación:
$ sort sample_file.txt | uniq -c
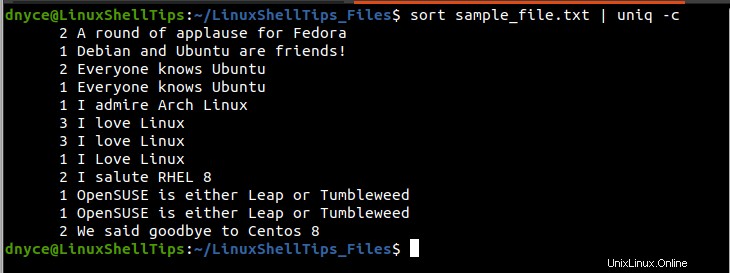
La primera columna (a la izquierda) del resultado anterior indica el número de veces que las líneas impresas en la columna derecha aparecen dentro del sample_file.txt Archivo de texto. Por ejemplo, la línea “Me encanta Linux” se duplica/repite (3+3+1) veces dentro del archivo de texto, un total de 7 veces.
Imprimir líneas duplicadas en un archivo usando el comando Awk
El awk comando para resolver este problema “imprimir líneas duplicadas en un archivo de texto ” problema es un simple de una sola línea. Para comprender cómo funciona, primero debemos implementarlo como se muestra a continuación:
$ awk '{ a[$0]++ } END{ for(x in a) print a[x], x }' sample_file.txt
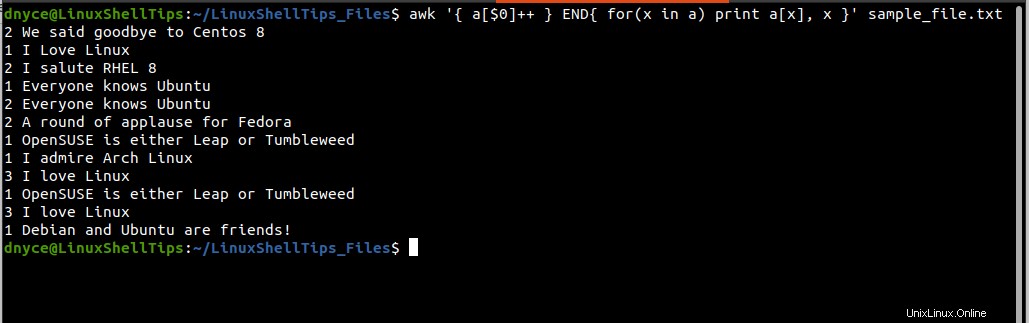
La ejecución del comando anterior genera dos columnas, la primera columna cuenta el número de veces que aparece una línea repetida/duplicada dentro del archivo de texto y la segunda columna apunta a la línea en cuestión.
Sin embargo, el resultado del comando anterior no está tan organizado como el de ordenar y uniq comandos.
Hemos cubierto con éxito cómo imprimir líneas duplicadas en un archivo de texto en un entorno de sistema operativo Linux.