Aquí hay un montón de consejos útiles para hoy que probablemente permanecerán en su arsenal para siempre.
Como administrador de sistemas de Linux, a veces es difícil visualizar qué está causando un problema de rendimiento. Claro, es bastante fácil ver qué proceso está acaparando la CPU con herramientas como "top" o su hermano más elegante, htop. Cuando se trata de calcular la carga a largo plazo en una máquina o comprender cuánta memoria y ancho de banda de red se está utilizando, puede ser un desafío un poco mayor si no conoce las herramientas disponibles.
Supervisión de CPU y memoria con (h)top
Use el botón F6 en htop para ordenar por CPU o memoria, etc.
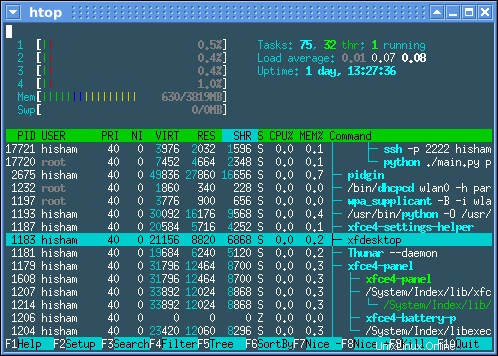
Análisis de CPU, memoria y E/S de disco durante un tiempo medido
Para analizar la carga promedio de CPU, memoria y E/S de disco durante una cantidad de tiempo medida, use la herramienta vmstat. Tiene un aspecto feo en comparación con htop, pero una vez que comprende la pantalla, puede ser muy eficaz para comprender lo que sucede con el sistema, excepto la utilización de la red. Tenga en cuenta también que es posible que los servidores invitados virtualizados no brinden las cifras reales de CPU y E/S, ya que pueden variar dinámicamente según la configuración del hipervisor.
Al igual que top, vmstat tiene una disponibilidad casi omnipresente para cada versión de Linux. Vmstat normalmente toma dos argumentos:el tiempo de muestra y el número de muestras a medir. Entonces, por ejemplo, ejecutar
vmstat 1 100
Hará una muestra cada segundo y realizará la muestra 100 veces. De forma predeterminada, vmstat le mostrará la salida de la carga de la CPU, la memoria/intercambio y el bloque de E/S, cuando ejecuta sus 100 muestras, le dará los promedios durante las muestras de tiempo, en este caso 100 segundos. Si desea ejecutar vmstat de forma continua, utilice 0 como número de muestra. Más información sobre la sintaxis y la salida de vmstat está disponible aquí (o use man vmstat).
Finalmente, como una alternativa basada en texto, puede crear esta función en su .bashrc o en un script de shell, esto le permitirá ejecutarlo a intervalos usando el comando at o programarlo con cron o quizás combinarlo con otro script para realizar un análisis más detallado. tiempo.
memcpu() { echo “— Los 10 mejores procesos de consumo de CPU —“; ps auxf | ordenar -nr -k 3 | head -10;
echo “— Los 10 mejores procesos de consumo de memoria —“; ps auxf | ordenar -nr -k 4 | cabeza -10; }
Análisis rápido de la utilización de la red
Podría decirse que monitorear la utilización de la red es tan importante como la CPU y la memoria. La cantidad de herramientas integradas que hacen esto varía entre distribuciones. Hay una multitud de herramientas que puede instalar a través de yum o apt-get en las respectivas distribuciones. Puedes probar ntop o nmon. Hoy vamos a ver nload. Aunque ntop se promociona a sí mismo como el comando "superior" de las redes, es una herramienta basada en la web que, si bien es buena, no es tan fácil de usar como nload. Para ejecutar nload, simplemente ejecútelo sin ningún argumento y generará la carga en la interfaz de red actual.
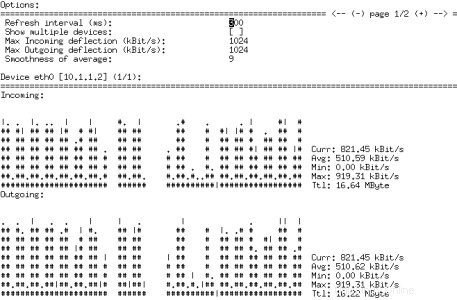
Nload hace exactamente lo que dice en la lata. El análisis histórico facilita ver qué tan ocupada está la red, desafortunadamente eso no le mostrará qué aplicación está causando la carga, pero hay aplicaciones que también pueden ayudar, como la excelente aplicación nethogs. Se ve y funciona igual que los procesos que se muestran en la parte superior por nombre y se ordenan según el proceso que consume más ancho de banda.
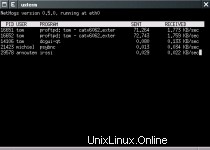
En conclusión y más opciones
Lo que he demostrado aquí son algunas herramientas de análisis excelentes y rápidas para sacarlo de un problema potencialmente difícil de diagnosticar. Si necesita un análisis a más largo plazo de casi cualquier aspecto medible, entonces debería buscar algo como nagios y combinarlo con rrdtool para graficar el análisis de tendencias históricas. Mire cacti (gráficos rrd) y munin (algo así como nagios + rrdtool + cacti en un paquete fácil).