Crear gráficos estadísticos en Python puede ser una molestia, especialmente si los genera manualmente. Pero con la ayuda de la biblioteca de visualización de datos Seaborn Python, puede simplificar su trabajo y crear hermosos gráficos rápidamente y con menos líneas de código.
Con Seaborn, crear hermosos gráficos estadísticos para sus datos es pan comido. Esta guía le mostrará cómo usar esta poderosa biblioteca a través de ejemplos de la vida real.
Requisitos
Este tutorial será una demostración práctica. Si desea seguirnos, asegúrese de tener lo siguiente:
- Una computadora con Windows o Linux con Python y Anaconda instalados. Este tutorial usará Anaconda 2021.11 con Python 3.9 en una PC con Windows 10.
¿Qué es la biblioteca Seaborn Python?
La biblioteca Seaborn Python es una biblioteca de visualización de datos de Python basada en la biblioteca Matplotlib. Seaborn ofrece un amplio conjunto de herramientas de alto nivel para crear diagramas y gráficos estadísticos. La capacidad de Seaborn para integrarse con objetos Pandas Dataframe le permite visualizar datos rápidamente.
Un marco de datos representa datos tabulares, como los que encontraría en una tabla, una hoja de cálculo o un archivo CSV de valores separados por comas.
Seaborn funciona con Pandas DataFrames y convierte datos ocultos en código que Matplotlib puede entender.
Si bien hay muchas parcelas de alta calidad disponibles, aprenderá en este tutorial sobre las tres familias de parcelas Seaborn integradas más comunes para ayudarlo a comenzar.
- Gráficas relacionales.
- Parcelas de distribución.
- Gráficas categóricas.
Seaborn incluye muchas más tramas y este tutorial no puede cubrirlas todas. La documentación de la API de Seaborn y el tutorial son excelentes puntos de partida para conocer todos los diferentes tipos de gráficos de Seaborn.
Configuración de un nuevo entorno de JupyterLab y Seaborn Python
Antes de comenzar su viaje a Seaborn, primero deberá configurar un entorno de Jupyter Lab. Además, para mantener la coherencia con los ejemplos, trabajará en un conjunto de datos específico junto con este tutorial.
JupyterLab es una aplicación web que le permite combinar código, texto enriquecido, gráficos y otros medios en un solo documento. También puede compartir cuadernos en línea con otras personas o usarlos como documentos ejecutables.
Para comenzar a configurar su entorno, siga estos pasos.
1. Abra el Navegador Anaconda r en su computadora.
una. En una computadora con Windows:haga clic en Inicio —> Anaconda3 —> Navegador Anaconda .
b. En una computadora con Linux:Ejecute el anaconda-navigator comando en la terminal.
2. En Anaconda Navigator, busque el JupyterLab aplicación y haga clic en Iniciar . Al hacerlo, se abrirá una instancia de JupyterLab en un navegador web.

3. Después de iniciar JypyterLab, abra la barra lateral del Explorador de archivos y cree una nueva carpeta llamada ATA_Seaborn en su perfil o directorio de inicio. Esta nueva carpeta será el directorio de su proyecto.
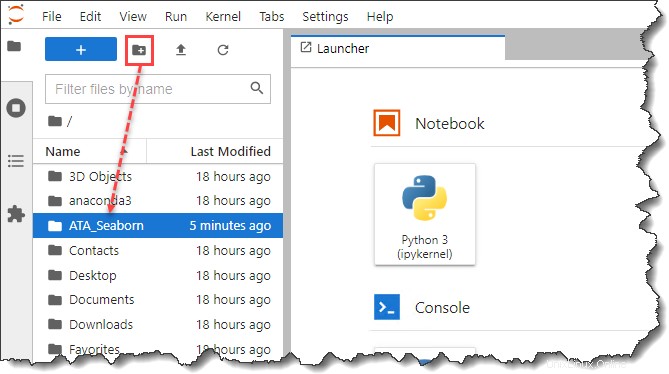
4. A continuación, abra una nueva pestaña del navegador y descargue Pokémon conjunto de datos Asegúrate de guardar el ata_pokemon.csv archivo al directorio del proyecto que creó, que, en este ejemplo, es ATA_Seaborn .
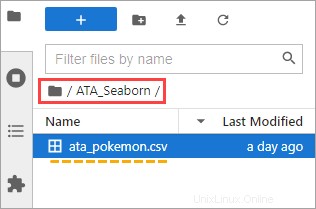
5. De vuelta en JupyterLab, haga doble clic en ATA_Seaborn carpeta. Ahora debería ver el ata_pokemon.csv debajo de esa carpeta.
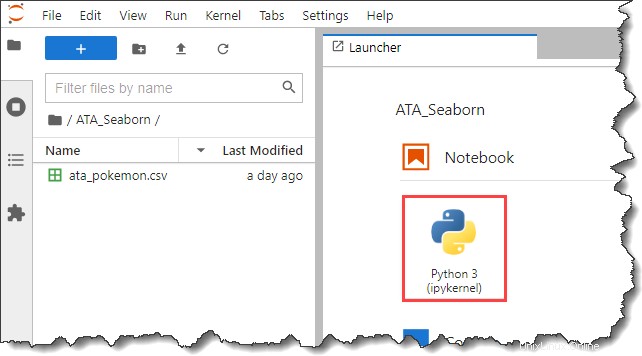
6. Ahora, haga clic en Python 3 botón debajo del Cuaderno sección en el Lanzador pestaña para crear un nuevo cuaderno.
7. Ahora, haga clic en el nuevo cuaderno Untitled.ipynb y presiona F2 para cambiar el nombre del archivo. Cambia el nombre del archivo a ata_pokemon.ipynb .

8. A continuación, agregue un título a su cuaderno. Este paso es opcional pero se recomienda para que su proyecto sea más identificable.
En la barra de herramientas de sus cuadernos, haga clic en el menú desplegable que dice Código y haz clic en Rebajas.
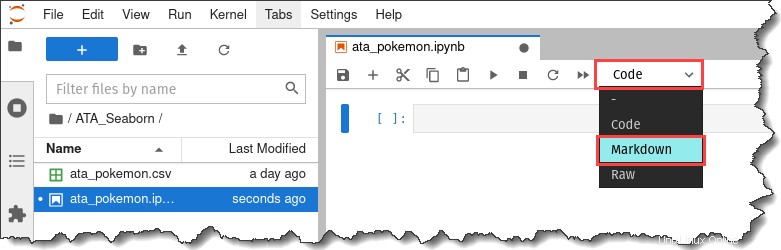
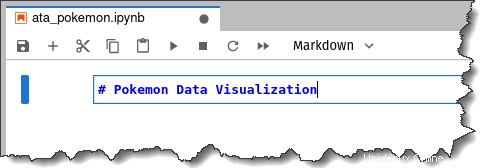
9. Ingrese el texto, "# Visualización de datos de Pokémon", dentro de la celda de descuento y presione las teclas Shift + Enter.
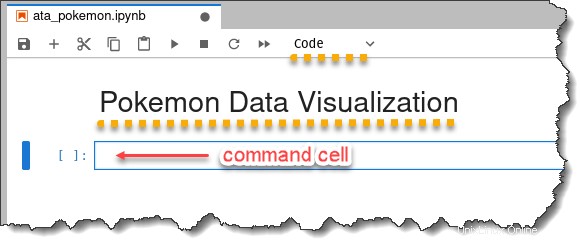
La selección del tipo de celda cambia automáticamente a Código, y el cuaderno tendrá el título Visualización de datos de Pokémon en la cima.
10. Finalmente, guarde su trabajo presionando las teclas Ctrl + S.
Asegúrese de guardar su trabajo con frecuencia. Debe guardar su trabajo con frecuencia para evitar perder algo si hay algún problema con la conexión a Internet. Cada vez que realice un cambio, pulse
CTRL+Spara guardar su progreso. También puede hacer clic en el botón Guardar en la barra de herramientas.
Importación de las bibliotecas Pandas y Seaborn Python
El código de Python generalmente comienza con la importación de las bibliotecas necesarias. Y en este proyecto, trabajará con las bibliotecas Pandas y Seaborn Python.
Para importar Pandas y Seaborn, copie el código a continuación y péguelo en la celda de comando de su computadora portátil.
Recuerde esto:para ejecutar el código o los comandos en la celda de comando, presione las teclas Shift + Enter.
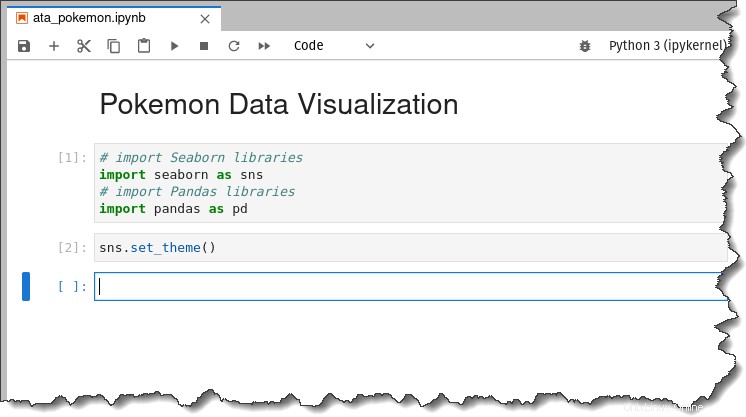
# import Seaborn libraries
import seaborn as sns
# import Pandas libraries
import pandas as pdA continuación, ejecute el siguiente comando para aplicar la estética del tema predeterminado de Seaborn a los gráficos que generará.
sns.set_theme()
Seaborn tiene cinco temas integrados disponibles. Son darkgrid (predeterminado), whitegrid , dark , white y ticks .
Importación del conjunto de datos de muestra
Ahora que ha configurado su entorno de JupyterLab, importemos los datos del conjunto de datos a su entorno de Jupyter.
1. Ejecute el pd.read_csv() Comando en la celda para importar los datos. El nombre del archivo del conjunto de datos debe estar entre paréntesis para indicar el archivo a importar entre comillas dobles.
El siguiente comando importará el ata_pokemon.csv y almacene el conjunto de datos en el pokemon variable.
pokemon = pd.read_csv("ata_pokemon.csv")
2. Ejecute el pokemon.head() para obtener una vista previa de las primeras cinco filas del conjunto de datos importado.
pokemon.head()Obtendrá el siguiente resultado.
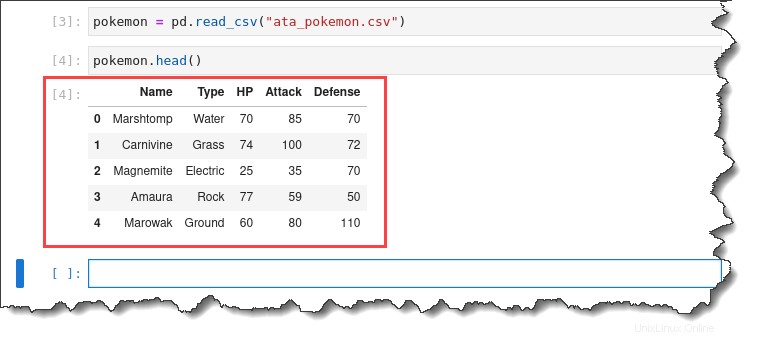
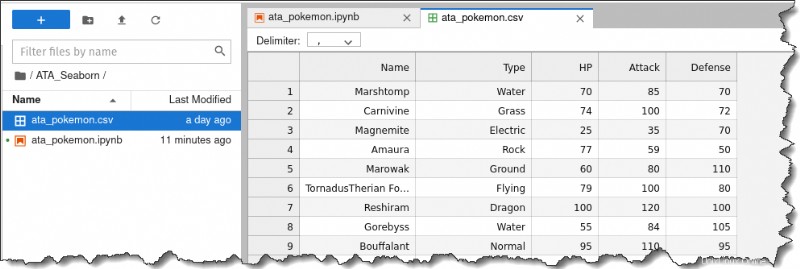
3. Haz doble clic en ata_pokemon.csv archivo de la izquierda para inspeccionar cada fila individual. Obtendrá el siguiente resultado.
Como puede ver, es muy conveniente trabajar con este conjunto de datos porque enumera cada observación por fila y toda la información numérica está en columnas separadas.
Ahora, hagamos algunas preguntas sobre el conjunto de datos para ayudar con el análisis.
- ¿Cuál es la relación entre Attack y HP?
- ¿Cuál es la distribución de Attack?
- ¿Cuál es la relación entre Ataque y Tipo?
- ¿Cuál es la distribución de ataque para cada tipo?
- ¿Cuál es el ataque promedio o medio para cada tipo?
- ¿Y cuál es la cantidad de Pokémon para cada tipo?
Tenga en cuenta que muchas de estas preguntas se centran en las relaciones de datos numéricos y categóricos. Los datos categóricos son datos no numéricos que, en este conjunto de datos de muestra, son el tipo de Pokémon.
A diferencia de Matplotlib, que está optimizado para crear gráficos con datos estrictamente numéricos, puede usar Seaborn para analizar datos que tienen datos categóricos y numéricos.
Creación de diagramas de relaciones
Así que ha importado un conjunto de datos. ¿Que sigue? Ahora utilizará sus datos importados y generará gráficos estadísticos a partir de ellos. Comencemos con la creación de gráficos relacionales o de relaciones para descubrir la relación entre HP y atacar datos.
El trazado de relaciones es práctico para identificar posibles relaciones entre variables en su conjunto de datos. Seaborn tiene dos diagramas para trazar relaciones:diagramas de dispersión y diagramas de líneas.
Trazado de líneas
La creación de un diagrama de líneas requiere que llame a Seaborn Python lineplot() función. Esta función toma tres parámetros:data= , x=' y y=' ‘.
Copie el siguiente comando y ejecútelo en su celda de comando Jupyter. Este comando usa el pokemon objeto como la fuente de datos que importó previamente, el HP datos de columna para el eje x y el Attack datos para el eje y.
sns.lineplot(data=pokemon, x='HP', y='Attack')Como puede ver a continuación, el gráfico de líneas no hace un gran trabajo al mostrarle la información que puede analizar rápidamente. Un diagrama de líneas es mejor para mostrar un eje x que sigue una variable continua como el tiempo.
En este ejemplo, está trazando una variable discreta HP. Entonces, lo que sucede es que el gráfico de líneas va por todos lados. Y es más difícil inferir una tendencia.
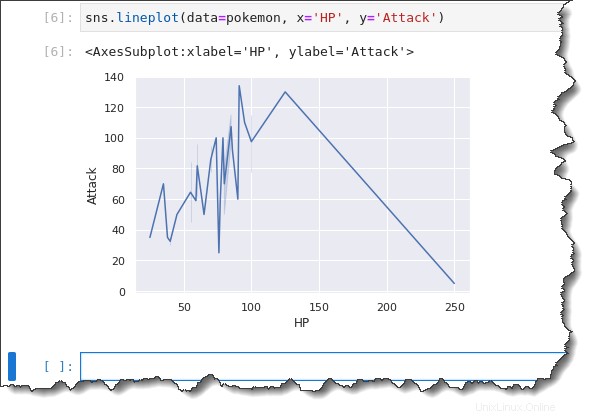
Gráfico de dispersión
Una parte del análisis exploratorio de datos es probar diferentes cosas para ver qué funciona bien. Y al hacerlo, aprenderá que algunas gráficas pueden mostrarle mejores perspectivas que otras.
Entonces, ¿qué hace que una gráfica de relaciones sea mejor que las gráficas de líneas? — Gráficos de dispersión.
Para hacer un diagrama de dispersión, llama a la función de diagrama de dispersión, sns.scatterplot y pase tres parámetros: data=pokemon , x=HP y y=Attack .
Ejecute el siguiente comando para hacer un diagrama de dispersión para el conjunto de datos de pokemon.
sns.scatterplot(data=pokemon, x='HP', y='Attack')Como puede ver en el siguiente resultado, el diagrama de dispersión muestra que puede haber una correlación positiva general entre HP (eje x) y Ataque (eje y), con un valor atípico.
Generalmente, a medida que aumenta HP, el Ataque también lo hace. Los Pokémon con puntos de vida más grandes tienden a ser más fuertes.
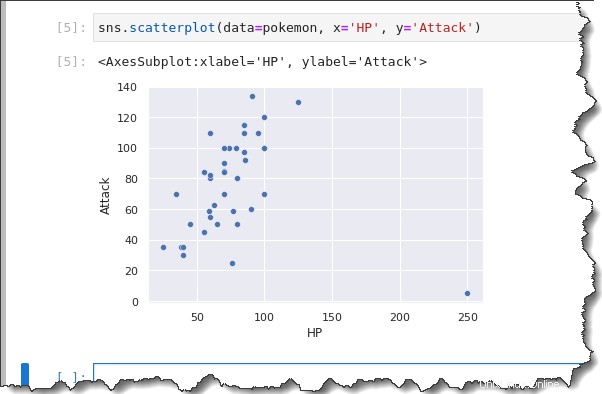
Gráfico de dispersión con leyendas
Si bien el gráfico de dispersión ya presentaba una visualización de datos más sensible, aún puede mejorar aún más el gráfico desglosando la distribución de tipos con una leyenda.
Ejecute el sns.scatterplot() vuelva a funcionar en el siguiente ejemplo. Pero esta vez, agregue el hue='Type' palabra clave, que creará una leyenda que muestra los diferentes tipos de Pokémon. De vuelta en la pestaña de su cuaderno Jupyter, ejecute el siguiente comando.
sns.scatterplot(data=pokemon, x='HP', y='Attack', hue='Type')Observe el resultado a continuación, el diagrama de dispersión ahora tiene diferentes colores. Analizar los aspectos categóricos de sus datos ahora es mucho mejor debido a las distinciones visuales que proporciona la leyenda.
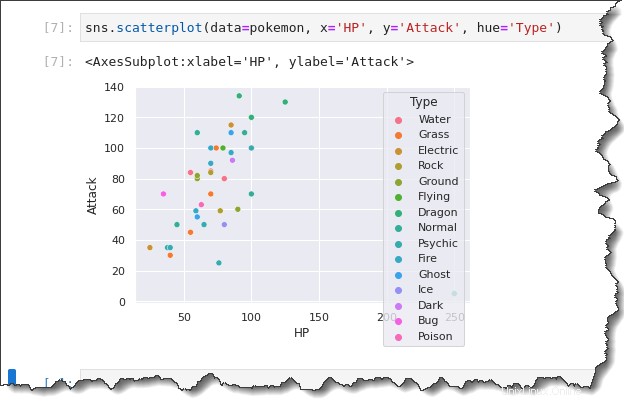
Lo que es aún mejor es que aún puedes desglosar la trama aún más usando el sns.relplot() función con el col=Type y col_wrap argumentos de palabras clave.
Ejecute el siguiente comando en Jupyter para crear una trama para cada tipo de Pokémon en un formato de cuadrículas de múltiples tramas.
sns.relplot(data=pokemon, x='HP', y='Attack', hue='Type', col='Type', col_wrap=3)Mirando el resultado a continuación, puede inferir que HP y Attack generalmente están correlacionados positivamente. Los Pokémon con más HP tienden a ser más fuertes.
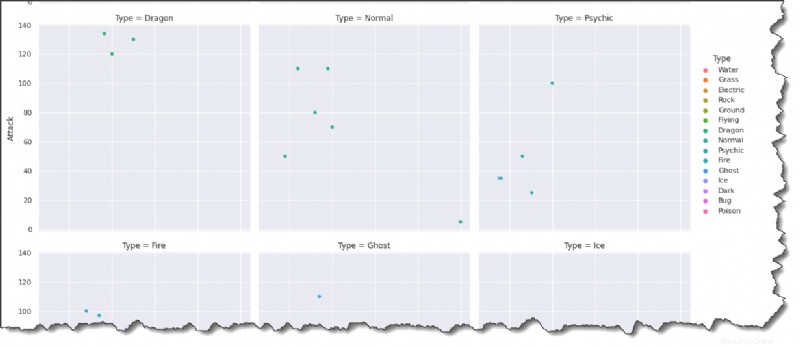
¿Estaría de acuerdo en que agregar colores y leyendas hace que el trazado sea más interesante?
Creación de gráficos de distribución
En la sección anterior, ha creado un diagrama de dispersión. Esta vez, usemos un gráfico de distribución para obtener información sobre la distribución de Ataque y HP para cada tipo de Pokémon.
Trazado de histograma
Puede utilizar el histograma para visualizar la distribución de una variable. En su conjunto de datos de muestra, la variable es el ataque de Pokémon.
Para crear un gráfico de histograma, ejecute el sns.histplot() función a continuación. Esta función toma dos parámetros:data=pokemon y x='Attack' . Copie el siguiente comando y ejecútelo en Jupyter.
sns.histplot(data=pokemon, x='Attack')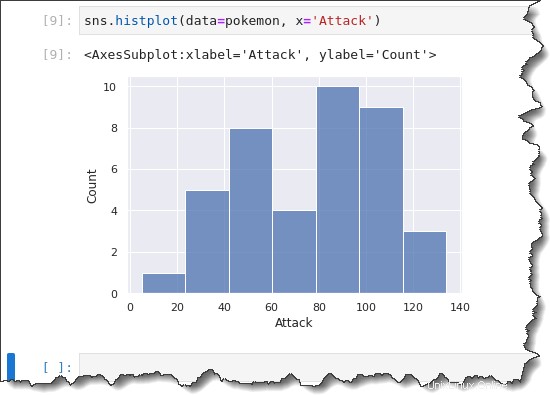
Al crear un histograma, Seaborn elige automáticamente un tamaño de contenedor óptimo para usted. Es posible que desee cambiar el tamaño del contenedor para observar la distribución de datos en agrupaciones de formas diferentes.
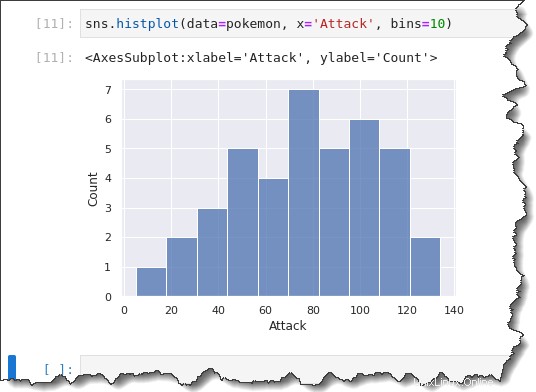
Para especificar un tamaño de contenedor fijo o personalizado, agregue el bins=x argumento del comando donde x es el tamaño de contenedor personalizado. Ejecute el siguiente comando para crear un histograma con un tamaño de contenedor de 10.
sns.histplot(data=pokemon, x='Attack', bins=10)En el histograma anterior que generaste, el Pokémon Attack parece tener una distribución bimodal (dos grandes jorobas).
Pero cuando observa el tamaño de su contenedor de 10, las agrupaciones se desglosan de forma más segmentada. Puede ver que hay más una distribución unimodal, con un sesgo hacia la derecha.
Trazado de estimación de densidad del kernel (KDE)
Otra forma de visualizar la distribución es con el gráfico de estimación de densidad kernel. KDE es esencialmente como un histograma pero con curvas en lugar de columnas.
La ventaja de usar un diagrama de KDE es que puede hacer inferencias más rápidas sobre cómo se distribuyen los datos debido a la curva de probabilidad, que muestra características como la tendencia central, la modalidad y el sesgo.
Para crear un diagrama de KDE, llame al sns.kdeplot() función y pasar en el mismo data=pokemon , x='Attack' como argumentos. Ejecute el siguiente código en Jupyter para ver el diagrama de KDE en acción.
sns.kdeplot(data=pokemon, x='Attack')Como puede ver a continuación, el gráfico de KDE es similar al sesgo del histograma con un tamaño de contenedor de 10.
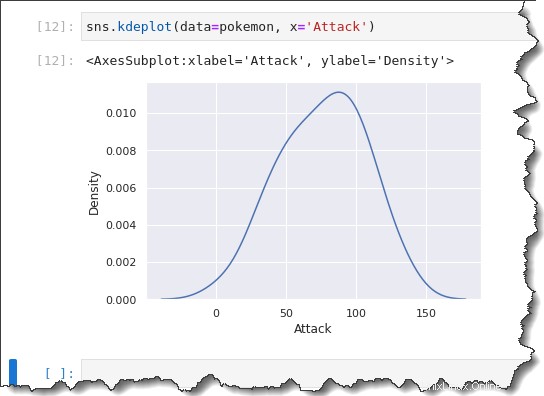
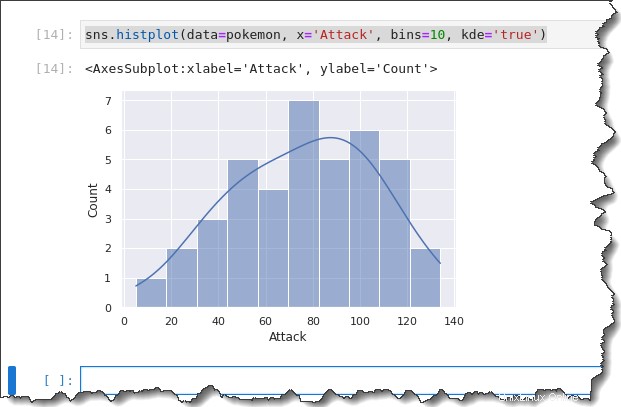
Dado que el histograma y KDE son similares, ¿por qué no usarlos juntos? Seaborn le permite superponer el KDE en un histograma agregando la palabra clave kde='true' argumento del comando anterior, como puede ver a continuación.
sns.histplot(data=pokemon, x='Attack', bins=10, kde='true')Obtendrá el siguiente resultado. De acuerdo con el histograma a continuación, la mayoría de los Pokémon tienen un punto de ataque distribuido entre 50 y 120. ¡No es una buena distribución!
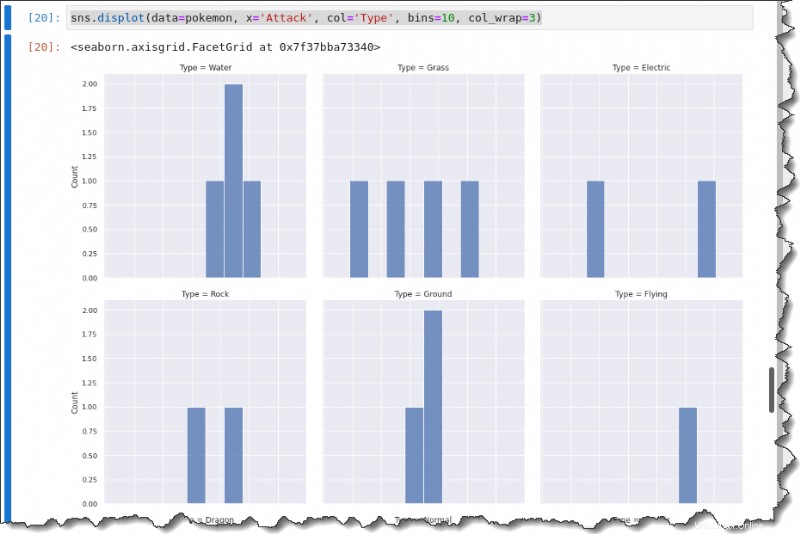
Para desglosar cada distribución de ataque por Tipo, llame al displot() función con el col palabra clave a continuación para crear un diagrama de cuadrícula múltiple que muestre cada tipo.
sns.displot(data=pokemon, x='Attack', col='Type', bins=10, col_wrap=3)Obtendrá el siguiente resultado.
Generación de gráficos categóricos
Es bueno hacer histogramas separados basados en la categoría de tipo. Pero es posible que los histogramas no le den una imagen clara. Entonces, usemos algunos de los diagramas categóricos de Seaborn para ayudarlo a sumergirse más en el análisis de los datos de ataques según los tipos de Pokémon.
Trazado de franjas
En los diagramas de dispersión e histogramas anteriores, trató de visualizar los datos de Ataque de acuerdo con una variable categórica (Type ). Esta vez, harás un diagrama de franjas, una serie de diagramas de dispersión agrupados por categoría.
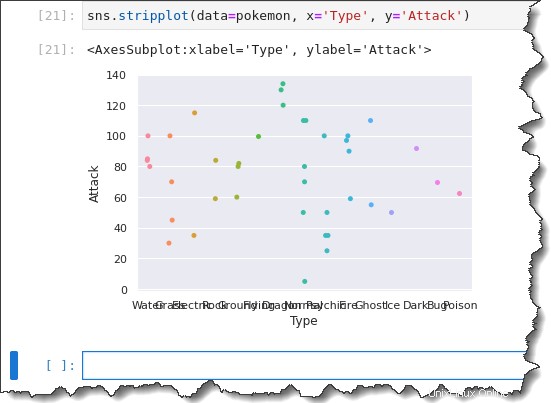
Para crear su gráfico de franjas categóricas, llame al sns.stripplot() función y pasar tres argumentos:data=pokemon , x='Type' y y='Attack' . Ejecute el siguiente código en Jupyter para generar el diagrama de franjas categóricas.
sns.stripplot(data=pokemon, x='Type', y='Attack')Ahora tiene un diagrama de franjas con todas las observaciones agrupadas por Tipo. Pero observe cómo las etiquetas del eje x están todas juntas. No es tan útil, ¿verdad?
Para arreglar las etiquetas del eje x, tendrás que usar una función diferente llamada catplot() .
En la celda de comando de su notebook Jupyter, ejecute sns.catplot() función y pasar cinco argumentoskind='strip' , data=pokemon , x='Type' , y='Attack' y aspect=2 , como se muestra a continuación.
sns.catplot(kind='strip', data=pokemon, x='Type', y='Attack', aspect=2)Esta vez, el bote resultante muestra las etiquetas del eje x en todo su ancho, lo que hace que su análisis sea más conveniente.
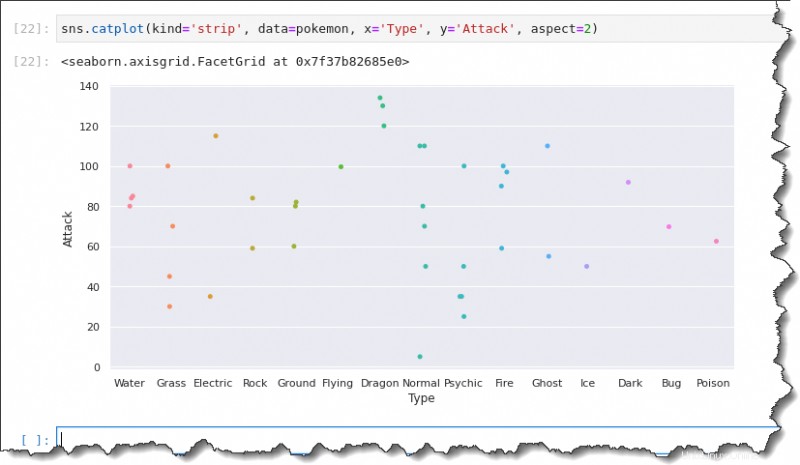
Diagrama de caja
Los catplot() La función tiene otra subfamilia de gráficos que lo ayudarán a visualizar la distribución de datos con una variable categórica. Uno de ellos es el diagrama de caja.
Para crear un diagrama de caja, ejecute el sns.catplot() función con los siguientes argumentos:data=pokemon , kind='box' , x='Type' , y='Attack' y aspect=2 .
El aspect El argumento controla el espacio entre las etiquetas del eje x. Un valor más alto significa un margen más amplio.
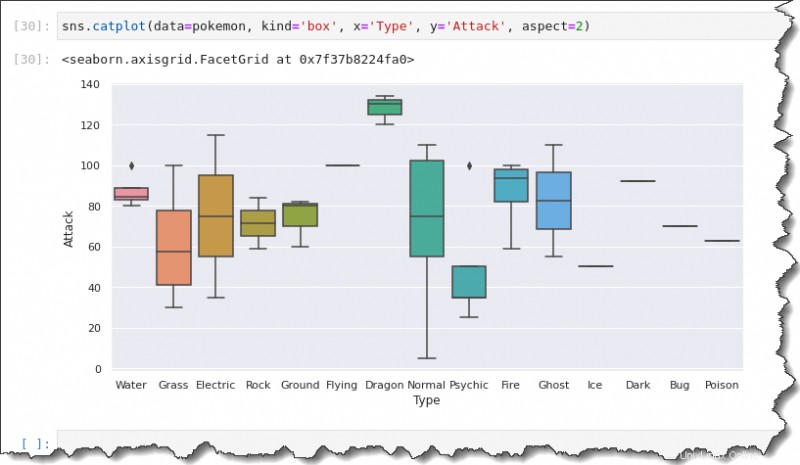
sns.catplot(data=pokemon, kind='box', x='Type', y='Attack', aspect=2)
Esta salida le brinda un resumen de la dispersión de los datos. Usando el catplot() función, puede obtener datos distribuidos para cada tipo de Pokémon en un gráfico.
Observe que los marcadores de diamantes negros representan valores atípicos. En lugar de un diagrama de caja, una línea en el medio significa que solo hay una observación para ese tipo de Pokémon.
Tienes un resumen de cinco números para cada uno de estos diagramas de caja y bigotes. La línea en el medio del cuadro representa el valor medio o su tendencia central de los puntos de Ataque.
También tiene los cuartiles primero y tercero y los bigotes, que representan los valores máximo y mínimo.
Trazado de violín
Otra forma de visualizar la distribución es mediante el diagrama de violín. El diagrama del violín es como un diagrama de caja y una mezcla de KDE. Los diagramas de violín son análogos a los diagramas de caja.
Para crear una trama de violín, reemplace el kind valor a violin , mientras que el resto son los mismos que cuando ejecutó el comando de trazado de cajas. Ejecute el siguiente código para crear un diagrama de violín.
sns.catplot(kind='violin', data=pokemon, x='Type', y='Attack', aspect=2)Como resultado, puede ver que la gráfica de violín incluye la mediana, el primer y el tercer cuartil. El gráfico de violín proporciona un resumen similar de los datos distribuidos en el gráfico de caja.
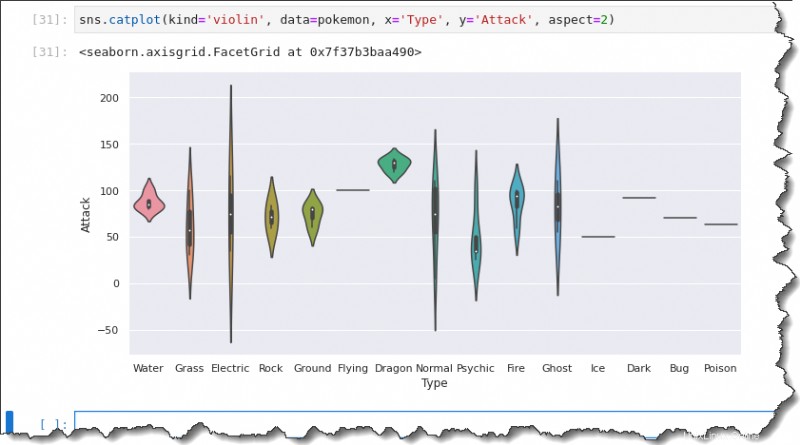
Retomando la pregunta:¿Cuál es la distribución de ataques para cada tipo de Pokémon?
El diagrama de caja muestra que los puntos de ataque mínimos se encuentran entre 0 y 10, mientras que el máximo sube a 110.
La mediana de los puntos de ataque para los Pokémon de tipo normal parece estar alrededor de 75. El primer y tercer cuartil parecen estar alrededor de 55 y 105.
Trazado de barras
El gráfico de barras es un miembro de la familia de estimación categórica de Seaborn que muestra los valores medios o promedio de cada categoría de datos.
Para crear un gráfico de barras, ejecute el sns.catplot() función en Jupyter y especifique seis argumentos:kind='bar' , data=pokemon , x='Type' , y='Attack' y aspect=2 , como se muestra a continuación.
sns.catplot(kind='bar',data=pokemon,x='Type',y='Attack',aspect=2)Las líneas negras en cada barra son barras de error que representan incertidumbre, como valores atípicos en las observaciones. Como puede ver a continuación, los valores medios son:
- Alrededor de 90 para los Pokémon de tipo agua.
- Alrededor de 60 para hierba .
- Eléctrico está aproximadamente en 75.
- Roca tal vez 70.
- El suelo dentro de 75.
- Y así sucesivamente.
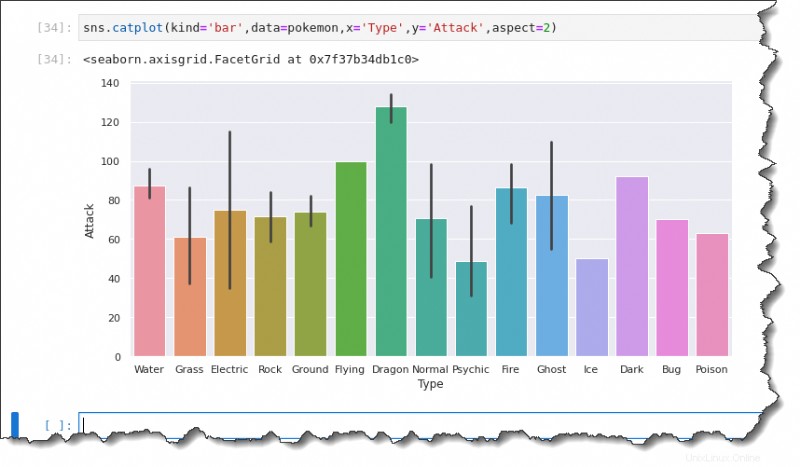
Recuento de gráficos
¿Qué sucede si desea trazar el recuento de Pokémon en lugar de los datos medios/promedio? El gráfico de conteo le permitirá hacer eso con la biblioteca Seaborn Python.
Para generar un gráfico de conteo, reemplace el kind valor con count , como se muestra en el siguiente código. A diferencia del diagrama de barras, el diagrama de conteo solo necesita un eje de datos. Dependiendo de la orientación del gráfico que desee crear, especifique el eje x o el eje y solamente.
El siguiente comando crea el gráfico de recuento que muestra la variable de tipo en el eje x.
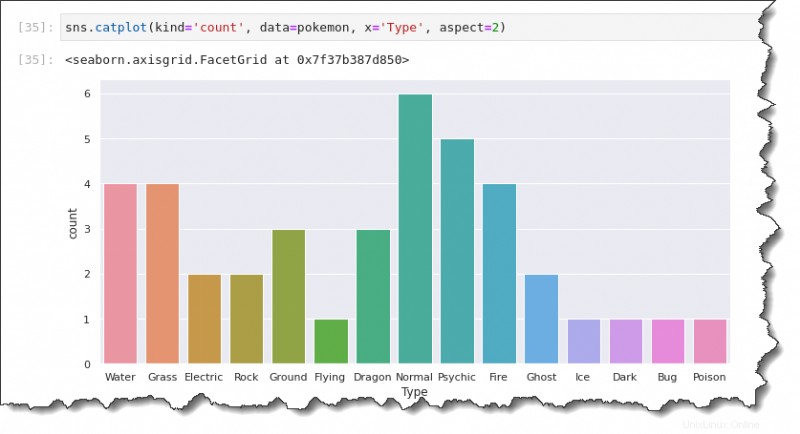
sns.catplot(kind='count', data=pokemon, x='Type', aspect=2)Tendrá un diagrama de conteo que se parece al siguiente. Como puedes ver, los tipos de Pokémon más comunes son:
- Normal (6).
- Psíquico (5).
- Agua (4).
- Hierba (4).
- Y así sucesivamente.
Conclusión
En este tutorial, ha aprendido a crear diagramas estadísticos mediante programación con la biblioteca Seaborn Python. ¿Qué método de trazado cree que será el más apropiado para su conjunto de datos?
Ahora que ha trabajado con ejemplos y practicado la creación de tramas con Seaborn, ¿por qué no comienza a trabajar en nuevas tramas por su cuenta? ¿Quizás pueda comenzar con el conjunto de datos de Iris o recopilar sus datos de muestra?
Y mientras lo hace, ¡pruebe también algunas de las otras plantillas y paletas de colores integradas de Seaborn! ¡Gracias por leer y divertirse!