Respuesta actualizada en el año 2020 :
Según la respuesta de @Owen, ORC creció y maduró como su propio proyecto Apache. Una lista completa de ORC Adopters muestra cuán frecuente es ahora compatible con muchas variedades de tecnologías de Big Data.
Gracias a @Owen y al equipo del proyecto Apache de ORC, el sitio del proyecto de ORC tiene una documentación actualizada totalmente mantenida sobre el uso de la herramienta independiente Java o C++ en un archivo ORC almacenado en un sistema de archivos local de Linux. Que llevó la antorcha de la página wiki original de Hive+ORC Apache.
Respuesta original con fecha:May 30 '14 at 16:27
La utilidad de volcado de archivos ORC viene con hive (0.11 o superior):
hive --orcfiledump <hdfs-location-of-orc-file>
Enlace fuente
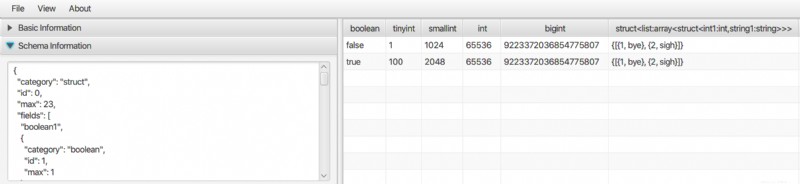
También es capaz de ver el contenido de un archivo ORC mediante una aplicación de escritorio que se ejecuta en Linux.
Hay una aplicación de escritorio para ver Parquet y también otros datos en formato binario como ORC y AVRO. Es una aplicación Java pura, por lo que se puede ejecutar en Linux, Mac y también en Windows. Consulte el Visor de archivos Bigdata para obtener más información.
Admite tipos de datos complejos como matriz, mapa, estructura, etc.
Ahora también hay un ejecutable nativo para Linux y MacOS que imprime el contenido del archivo orc en JSON. Consulte el proyecto ORC (http://orc.apache.org/) y cree las herramientas de C++.
% orc-contents examples/TestOrcFile.test1.orc
También hay una herramienta de metadatos nativa:
% orc-metadata ../examples/TestOrcFile.test1.orc
El proyecto ORC también tiene un uber jar independiente que puede hacer lo mismo desde Java.
% java -jar orc-tools-1.2.3-uber.jar data myfile.orc