Introducción
Apache Hive es un sistema de almacenamiento de datos empresarial que se utiliza para consultar, administrar y analizar datos almacenados en el sistema de archivos distribuidos de Hadoop.
Hive Query Language (HiveQL) facilita las consultas en un shell de interfaz de línea de comandos de Hive. Hadoop puede usar HiveQL como puente para comunicarse con sistemas de administración de bases de datos relacionales y realizar tareas basadas en comandos similares a SQL.
Esta sencilla guía le muestra cómo instalar Apache Hive en Ubuntu 20.04 .

Requisitos previos
Apache Hive se basa en Hadoop y requiere un marco Hadoop completamente funcional.
Instalar Apache Hive en Ubuntu
Para configurar Apache Hive, primero debe descargar y descomprimir Hive. Luego, debe personalizar los siguientes archivos y configuraciones:
- Editar .bashrc archivo
- Editar hive-config.sh archivo
- Crear directorios Hive en HDFS
- Configurar hive-site.xml archivo
- Iniciar base de datos Derby
Paso 1:Descargar y descomprimir Hive
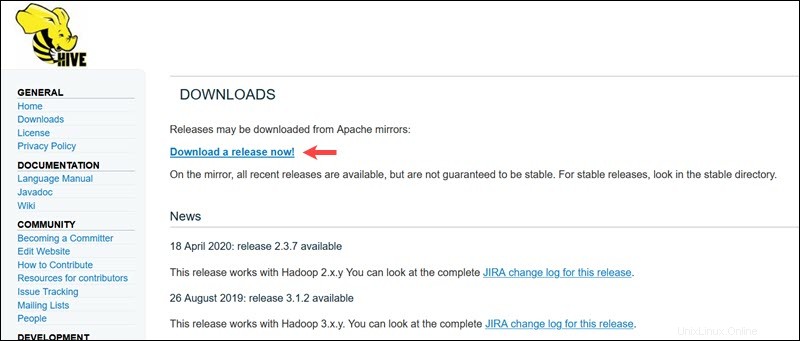
Visite la página de descarga oficial de Apache Hive y determine qué versión de Hive es la más adecuada para su edición de Hadoop. Una vez que establezca qué versión necesita, seleccione ¡Descargar una versión ahora! opción.
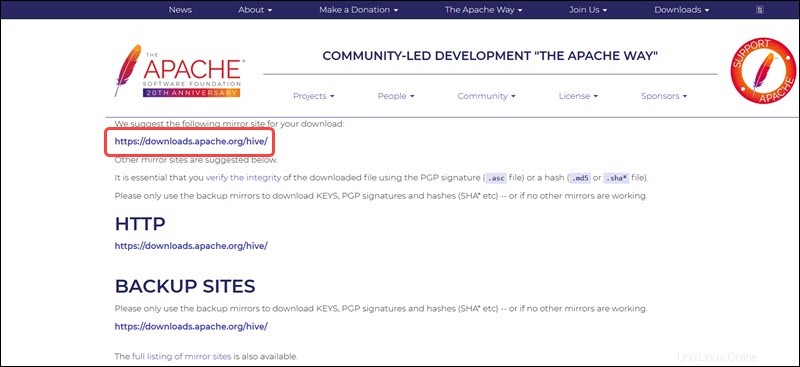
El enlace espejo en la página siguiente conduce a los directorios que contienen los paquetes tar de Hive disponibles. Esta página también proporciona instrucciones útiles sobre cómo validar la integridad de los archivos recuperados de los sitios espejo.
El sistema Ubuntu presentado en esta guía ya tiene Hadoop 3.2.1 instalado. Esta versión de Hadoop es compatible con Hive 3.1.2 liberar.
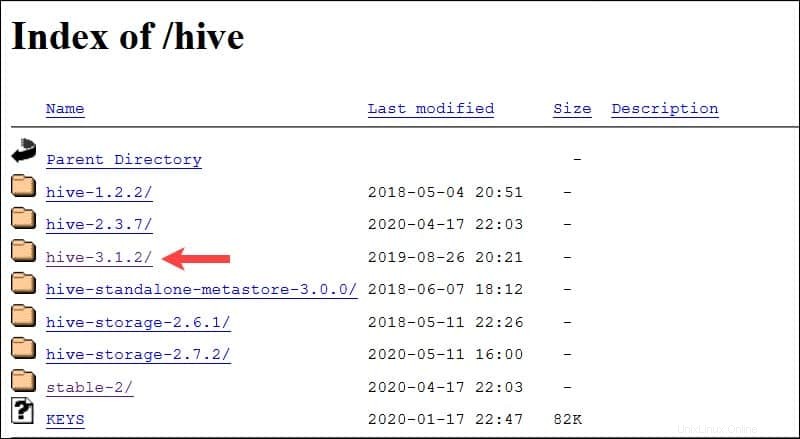
Seleccione el apache-hive-3.1.2-bin.tar.gz archivo para comenzar el proceso de descarga.
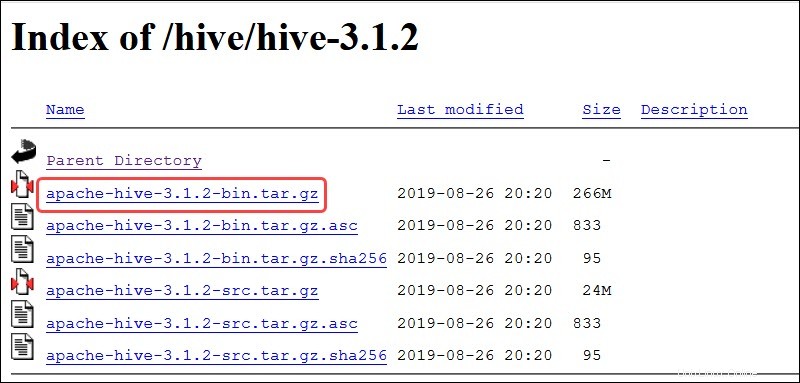
Alternativamente, acceda a su línea de comandos de Ubuntu y descargue los archivos Hive comprimidos usando y wget comando seguido de la ruta de descarga:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz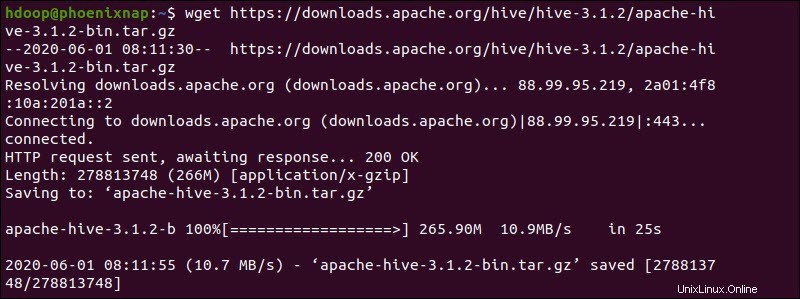
Una vez que se complete el proceso de descarga, descomprima el paquete de Hive comprimido:
tar xzf apache-hive-3.1.2-bin.tar.gzLos archivos binarios de Hive ahora se encuentran en el apache-hive-3.1.2-bin directorio.

Paso 2:configurar las variables de entorno de Hive (bashrc)
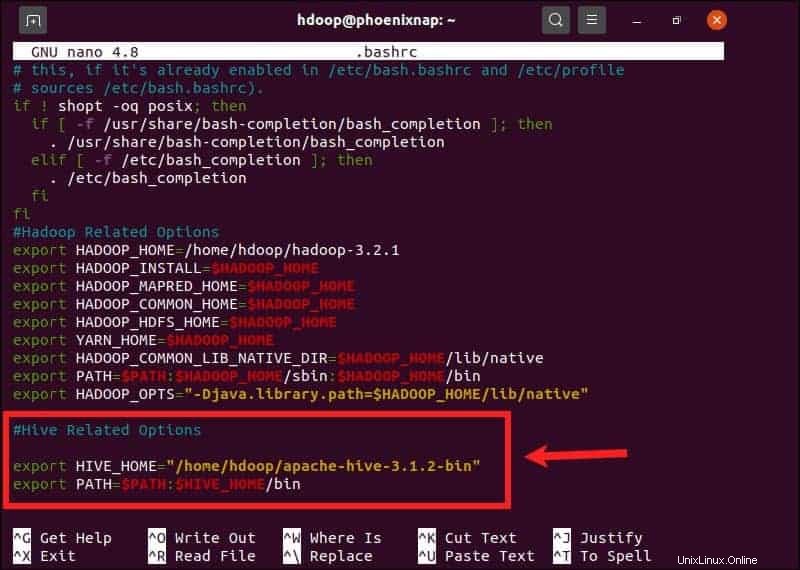
El $HIVE_HOME la variable de entorno necesita dirigir el shell del cliente al apache-hive-3.1.2-bin directorio. Edite el .bashrc archivo de configuración de shell usando un editor de texto de su elección (estaremos usando nano):
sudo nano .bashrcAgregue las siguientes variables de entorno de Hive a .bashrc archivo:
export HIVE_HOME= "home/hdoop/apache-hive-3.1.2-bin"
export PATH=$PATH:$HIVE_HOME/binLas variables de entorno de Hadoop se encuentran dentro del mismo archivo.
Guarde y salga de .bashrc archivo una vez que agregue las variables de Hive. Aplique los cambios al entorno actual con el siguiente comando:
source ~/.bashrcPaso 3:Edite el archivo hive-config.sh
Apache Hive debe poder interactuar con el sistema de archivos distribuidos de Hadoop. Acceda a hive-config.sh usando el archivo $HIVE_HOME creado previamente variables:
sudo nano $HIVE_HOME/bin/hive-config.sh
Agrega el HADOOP_HOME variable y la ruta completa a su directorio de Hadoop:
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
Guarde las ediciones y salga de hive-config.sh archivo.
Paso 4:Crear directorios de Hive en HDFS
Cree dos directorios separados para almacenar datos en la capa HDFS:
- El temporal, tmp El directorio almacenará los resultados intermedios de los procesos de Hive.
- El almacén El directorio almacenará las tablas relacionadas con Hive.
Crear directorio tmp
Crear un tmp directorio dentro de la capa de almacenamiento HDFS. Este directorio va a almacenar los datos intermediarios que Hive envía al HDFS:
hdfs dfs -mkdir /tmpAgregue permisos de escritura y ejecución a los miembros del grupo tmp:
hdfs dfs -chmod g+w /tmpCompruebe si los permisos se agregaron correctamente:
hdfs dfs -ls /El resultado confirma que los usuarios ahora tienen permisos de escritura y ejecución.

Crear directorio de almacén
Crear el almacén directorio dentro de /user/hive/ directorio principal:
hdfs dfs -mkdir -p /user/hive/warehouseAgregar escribir y ejecutar permisos para almacén miembros del grupo:
hdfs dfs -chmod g+w /user/hive/warehouseCompruebe si los permisos se agregaron correctamente:
hdfs dfs -ls /user/hiveEl resultado confirma que los usuarios ahora tienen permisos de escritura y ejecución.

Paso 5:configurar el archivo hive-site.xml (opcional)
Las distribuciones de Apache Hive contienen archivos de configuración de plantillas de forma predeterminada. Los archivos de plantilla se encuentran dentro de Hive conf directorio y delinear la configuración predeterminada de Hive.
Utilice el siguiente comando para localizar el archivo correcto:
cd $HIVE_HOME/conf
Enumere los archivos contenidos en la carpeta usando ls comando.

Utilice la hive-default.xml.template para crear el hive-site.xml archivo:
cp hive-default.xml.template hive-site.xmlAcceda al hive-site.xml archivo usando el editor de texto nano:
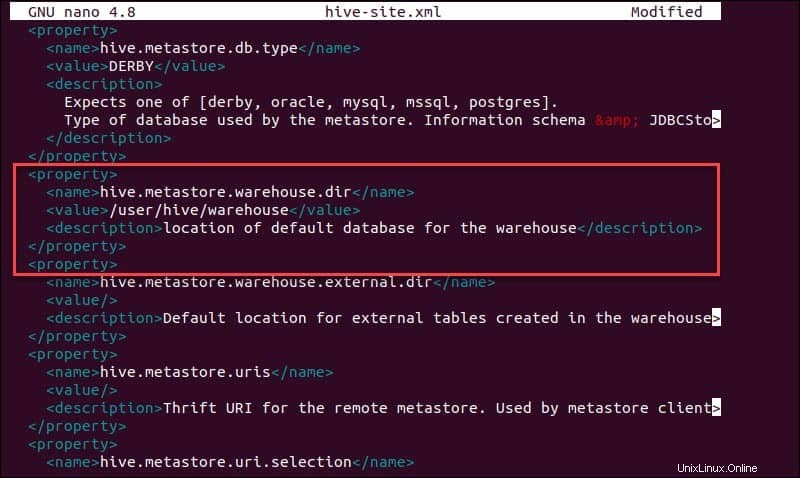
sudo nano hive-site.xmlEl uso de Hive en un modo independiente en lugar de un clúster de Apache Hadoop de la vida real es una opción segura para los recién llegados. Puede configurar el sistema para usar su almacenamiento local en lugar de la capa HDFS configurando hive.metastore.warehouse.dir valor del parámetro a la ubicación de su almacén de Hive directorio.
Paso 6:Iniciar la base de datos Derby
Apache Hive usa la base de datos Derby para almacenar metadatos. Inicie la base de datos Derby, desde Hive bin directorio utilizando la schematool comando:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaEl proceso puede tardar unos minutos en completarse.
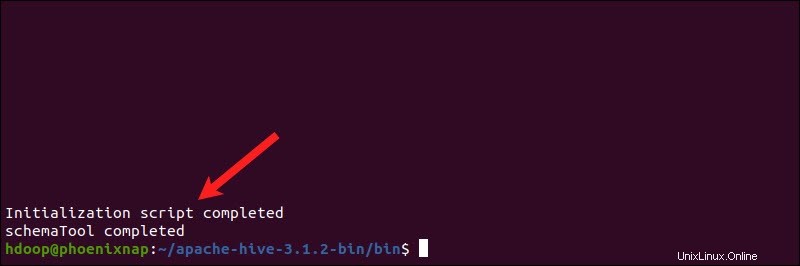
Derby es el almacén de metadatos predeterminado de Hive. Si planea utilizar una solución de base de datos diferente, como MySQL o PostgreSQL, puede especificar un tipo de base de datos en hive-site.xml archivo.
Cómo solucionar el error de incompatibilidad de guayaba en Hive
Si la base de datos Derby no se inicia correctamente, es posible que reciba un error con el siguiente contenido:
“Excepción en el subproceso “principal” java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V”
Este error indica que lo más probable es que haya un problema de incompatibilidad entre Hadoop y Hive guayaba versiones.
Localiza el frasco de guayaba archivo en Hive lib directorio:
ls $HIVE_HOME/lib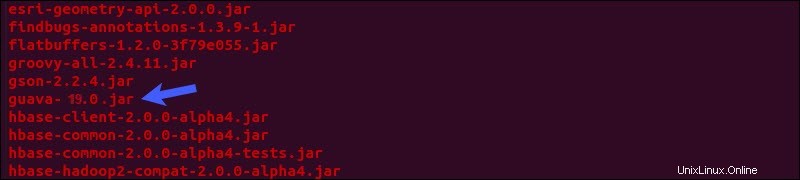
Localiza el frasco de guayaba archivo en Hadoop lib directorio también:
ls $HADOOP_HOME/share/hadoop/hdfs/lib
Las dos versiones enumeradas no son compatibles y están causando el error. Retire la guayaba existente archivo de Hive lib directorio:
rm $HIVE_HOME/lib/guava-19.0.jarCopia la guayaba archivo de Hadoop lib directorio a Hive lib directorio:
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
Usa la schematool comando una vez más para iniciar la base de datos Derby:
$HIVE_HOME/bin/schematool -dbType derby -initSchemaEjecutar Hive Client Shell en Ubuntu
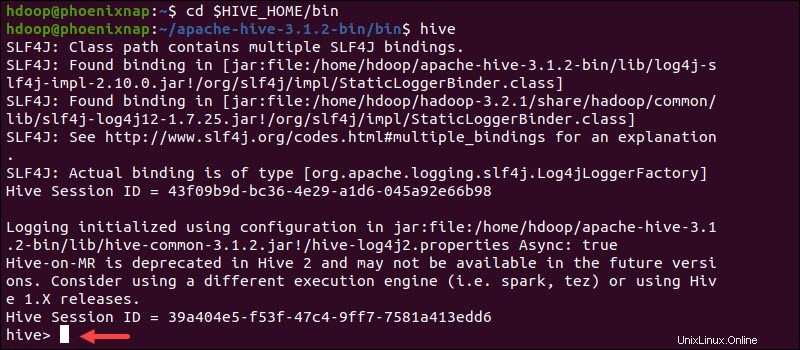
Inicie la interfaz de línea de comandos de Hive con los siguientes comandos:
cd $HIVE_HOME/binhiveAhora puede emitir comandos similares a SQL e interactuar directamente con HDFS.