Apache Kafka es una plataforma de transmisión distribuida. Es útil para construir canalizaciones de transmisión de datos en tiempo real para obtener datos entre los sistemas o aplicaciones. Otra característica útil son las aplicaciones de transmisión en tiempo real que pueden transformar flujos de datos o reaccionar ante un flujo de datos. Este tutorial lo ayudará a instalar Apache Kafka en los sistemas Ubuntu 19.10, 18.04 y 16.04.
Paso 1:instalar Java
Apache Kafka requería Java para ejecutarse. Debe tener java instalado en su sistema. Ejecute el siguiente comando para instalar OpenJDK predeterminado en su sistema desde los PPA oficiales. También puede instalar la versión específica de desde aquí.
sudo apt update sudo apt install default-jdk
Paso 2:descarga Apache Kafka
Descargue los archivos binarios de Apache Kafka desde su sitio web oficial de descargas. También puede seleccionar cualquier espejo cercano para descargar.
wget https://www.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
Luego extraiga el archivo comprimido
tar xzf kafka_2.13-2.7.0.tgz mv kafka_2.13-2.7.0 /usr/local/kafka
Paso 3:configurar los archivos de unidad de Kafka Systemd
A continuación, cree archivos unitarios systemd para el servicio Zookeeper y Kafka. Esto ayudará a administrar los servicios de Kafka para iniciar/detener usando el comando systemctl.
Primero, cree un archivo de unidad systemd para Zookeeper con el siguiente comando:
vim /etc/systemd/system/zookeeper.service
Agregue el contenido a continuación:
[Unit] Description=Apache Zookeeper server Documentation=http://zookeeper.apache.org Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Guarde el archivo y ciérrelo.
Luego, para crear un archivo de unidad Kafka systemd usando el siguiente comando:
vim /etc/systemd/system/kafka.service
Agrega el siguiente contenido. Asegúrese de establecer el JAVA_HOME correcto ruta según el Java instalado en su sistema.
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64" ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target
Guarde el archivo y cierre.
Vuelva a cargar el demonio systemd para aplicar nuevos cambios.
systemctl daemon-reload
Paso 4:iniciar el servidor Kafka
Kafka requería ZooKeeper, así que primero, inicie un servidor ZooKeeper en su sistema. Puede usar el script disponible con Kafka para iniciar una instancia de ZooKeeper de un solo nodo.
sudo systemctl start zookeeper
Ahora inicie el servidor Kafka y vea el estado de ejecución:
sudo systemctl start kafka sudo systemctl status kafka
Todo listo. La instalación de Kafka se completó con éxito. Esta parte de este tutorial lo ayudará a trabajar con el servidor Kafka.
Paso 5:crea un tema en Kafka
Kafka proporciona varios scripts de shell preconstruidos para trabajar en él. Primero, cree un tema llamado "testTopic" con una sola partición con una sola réplica:
cd /usr/local/kafka bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic Created topic testTopic.
El factor de replicación describe cuántas copias de datos se crearán. Como estamos ejecutando con una sola instancia, mantenga este valor en 1.
Establezca las opciones de particiones como el número de intermediarios entre los que desea que se dividan sus datos. Como estamos trabajando con un solo corredor, mantenga este valor en 1.
Puede crear varios temas ejecutando el mismo comando que el anterior. Después de eso, puede ver los temas creados en Kafka ejecutando el siguiente comando:
bin/kafka-topics.sh --list --zookeeper localhost:2181 testTopic TecAdminTutorial1 TecAdminTutorial2
Alternativamente, en lugar de crear temas manualmente, también puede configurar sus agentes para crear temas automáticamente cuando se publica un tema inexistente.
Paso 6:enviar mensajes a Kafka
El “productor” es el proceso responsable de poner datos en nuestro Kafka. Kafka viene con un cliente de línea de comandos que tomará la entrada de un archivo o de la entrada estándar y la enviará como mensajes al clúster de Kafka. El Kafka predeterminado envía cada línea como un mensaje separado.
Ejecutemos el productor y luego escribamos algunos mensajes en la consola para enviarlos al servidor.
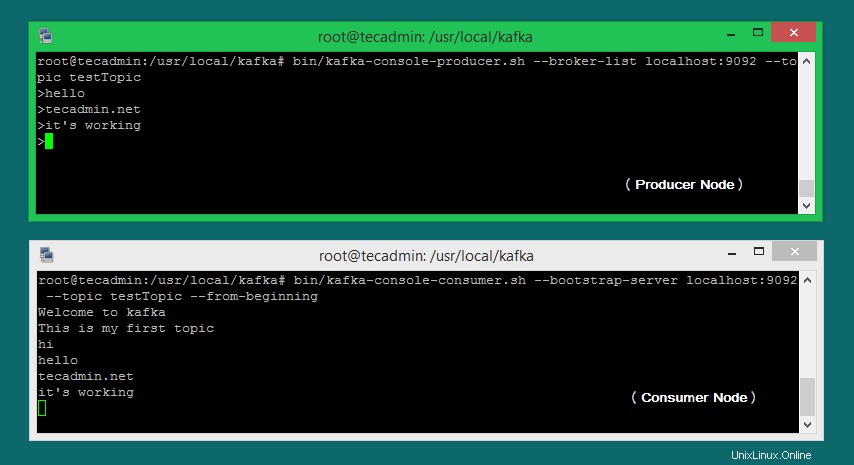
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic >Welcome to kafka >This is my first topic >
Puede salir de este comando o mantener este terminal en ejecución para realizar más pruebas. Ahora abra una nueva terminal para el proceso de consumidor de Kafka en el siguiente paso.
Paso 7:uso de Kafka Consumer
Kafka también tiene un consumidor de línea de comandos para leer datos del clúster de Kafka y mostrar mensajes en la salida estándar.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning Welcome to kafka This is my first topic
Ahora, si aún ejecuta el productor Kafka (Paso n. ° 6) en otra terminal. Simplemente escriba un texto en esa terminal del productor. será inmediatamente visible en la terminal del consumidor. Vea la siguiente captura de pantalla del productor y consumidor de Kafka trabajando:
Conclusión
Ha instalado y configurado con éxito el servicio Kafka en su máquina Ubuntu Linux.