Amigos que continúan con el conocimiento avanzado y la resolución de problemas en glusterfs. En este artículo, tenemos un clúster de 3 nodos ejecutándose en glusterfs3.4. A continuación se muestran los pasos que se utilizan para la solución de problemas de glusterfs.

[root@gluster1 ~]# gluster volume info
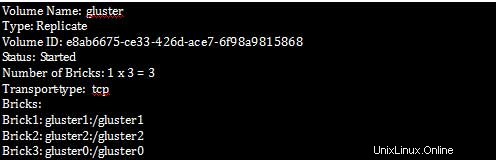
Paso 2 :Para verificar todos los detalles de la replicación en Bricks.
Los comandos mencionados a continuación mostrarán estadísticas completas de qué datos se han replicado y cuánto se replicará comprobando el tamaño del espacio libre total en disco.
[root@gluster1 ~]# gluster volume status all detail
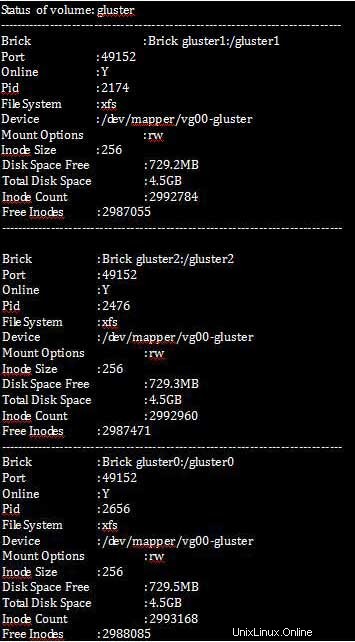
Paso 3 :Ahora necesitamos tener cierta configuración para mejorar el rendimiento y las características curativas de los glusterfs.
# gluster volume set gluster cluster.min-free-disk 5% # gluster volume set cluster.rebalance-stats on # gluster volume set cluster.readdir-optimize on # gluster volume set cluster.background-self-heal-count 20 # gluster volume set cluster.metadata-self-heal on # gluster volume set cluster.data-self-heal on # gluster volume set cluster.entry-self-heal: on # gluster volume set cluster.self-heal-daemon on # gluster volume set cluster.heal-timeout 500 # gluster volume set cluster.self-heal-window-size 2 # gluster volume set cluster.data-self-heal-algorithm diff # gluster volume set cluster.eager-lock on # gluster volume set cluster.quorum-type auto # gluster volume set cluster.self-heal-readdir-size 2KB # gluster volume set network.ping-timeout 5
Luego ejecuta:
# service glusterd restart
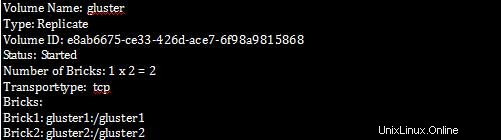
Una vez que hayamos establecido las propiedades del clúster, podemos verificar la información del volumen como se muestra a continuación:
[root@gluster1 ~]# gluster volume info
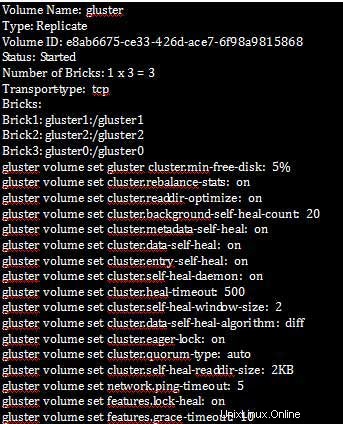
[root@gluster1 ~]# gluster volume status
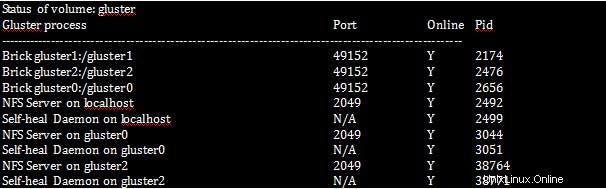
Tenga en cuenta que el Daemon de recuperación automática debe estar ejecutándose en cada sistema del clúster, ya que es responsable de la reparación en caso de que algún nodo esté inactivo durante algún tiempo del clúster.
Paso 4 :Ahora, para eliminar una máquina gluster0 del clúster.
Desmonte el Volumen montado en la máquina gluster0:
[root@gluster0 ~]# umount /mnt [root@gluster1 ~]# gluster volume remove-brick gluster replica 2 gluster0:/gluster0 commit
información de volumen de gluster (para verificar):
[root@gluster1 ~]# gluster volume info
En gluster1 ejecute el siguiente comando:
# gluster peer detach gluster0
El bloque del servidor gluster0 se elimina del clúster.