Puede usar el comando wget para descargar archivos usando los protocolos HTTP, HTTPS y FTP. Es una poderosa herramienta que le permite descargar archivos en segundo plano, navegar por sitios web y reanudar descargas interrumpidas. Wget también ofrece una serie de opciones que le permiten descargar archivos en condiciones de red extremadamente deficientes.
Este artículo le muestra cómo usar wget para realizar tareas de descarga comunes desde la línea de comandos.
Instalar wget
Linux
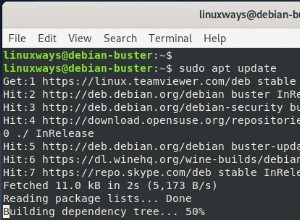
La mayoría de las distribuciones de Linux tienen wget instalado por defecto. Para verificar si está instalado en su sistema o no, escriba wget en su terminal y presione Entrar. Si no está instalado, obtendrá un error de "comando no encontrado". Use los comandos apropiados a continuación para instalarlo en su sistema.
Para sistemas basados en Ubuntu/Debian use:
sudo apt update sudo apt install wget
Para sistemas CentOS/RHEL use:
sudo yum install wget
MacOS
wget está disponible como un paquete homebrew, así que vaya a la página homebrew y siga las instrucciones para instalarlo. Después de eso, puede instalar wget con:
brew install wget
ventana
wget es parte de msys2, un proyecto que tiene como objetivo proporcionar un conjunto de herramientas de línea de comandos similares a Unix. Vaya a la página de inicio de msys2 y siga las instrucciones de la página para instalarlo. Luego abra una ventana de msys2 y escriba:
pacman -S wget
Ahora puede acceder al comando wget desde el shell MSYS2.
Descargar un archivo con su URL
Si tiene el enlace para un archivo específico, puede usar wget para descargarlo simplemente proporcionando la URL como parámetro:
wget https://releases.ubuntu.com/18.04/ubuntu-18.04-desktop-amd64.iso
Ejecutar el comando anterior mostrará información de progreso como:B. la velocidad de descarga actual y cuánto del archivo se ha descargado:
wget deriva un nombre de archivo de la última parte de la URL y lo descarga en su directorio actual. En nuestro ejemplo, el archivo se guarda en ubuntu-18.04-desktop-amd64.iso .
Si hay varios archivos, puede especificarlos uno por uno:
wget <url_1> <url_2>
Tenga en cuenta que wget solo funciona si se puede acceder directamente al archivo desde la URL. Ocasionalmente, encontrará archivos que no puede descargar directamente con un enlace, p. B. un archivo al que se puede acceder después de iniciar sesión en el artículo.
Descargar archivos a través de FTP
Wget funciona de la misma manera para FTP:proporciona la URL de FTP como argumento, así:
wget ftp://ftp.example.com/ubuntu/ubuntu-18.04-desktop-amd64.iso
A veces, un archivo FTP se puede proteger con un nombre de usuario y una contraseña. Puedes pasarlos a wget así:
wget --ftp-user=booleanworld --ftp-password=passw0rd <ftp_url>
Personalizar el nombre y el directorio del archivo de salida
Como ya hemos visto, wget deriva nombres de archivos y los descarga a su directorio actual. Si desea guardar el archivo en un directorio diferente o con un nombre diferente, puede usar el -O Cambiar. Por ejemplo, si desea guardar la descarga en un archivo Ubuntu.iso , Ejecutar:
wget <url> -O Ubuntu.iso
También puede cambiar el directorio de esta manera. Por ejemplo, para guardar la descarga como un archivo Ubuntu.iso bajo /media/sdb1/Software , Ejecutar:
wget <url> -O /media/sdb1/Software/Ubuntu.iso
A veces, es posible que desee especificar un directorio, pero deje que wget descubra el nombre del archivo. Puedes hacer esto usando el -P Cambiar. Si tiene un archivo bajo el /media/sdb1/Software directorio, use:
wget <url> -P /media/sdb1/Software
Reanudar descargas interrumpidas
Una descarga puede interrumpirse debido a malas condiciones de la red o porque la interrumpió manualmente presionando Ctrl+C mientras wget aún estaba descargando un archivo. Puede reanudar una descarga interrumpida con -c de wget Cambiar:
wget -c <url>
Si descargó a un directorio o archivo personalizado, debe usar el -c y el -P /-O cambiar, así:
wget -c <url> -O <path_to_downloaded_file>
Si usa -O y -c , asegúrese de proporcionar la URL correcta. De lo contrario, obtendrá una combinación parcial de dos archivos diferentes que los inutilizará. Además, algunos servidores no permiten que se reanuden las descargas de archivos. (Puede saber si un servidor admite la reanudación mirando la barra de progreso. Si la barra de progreso se mueve hacia adelante y hacia atrás en lugar de de izquierda a derecha durante la descarga inicial, el servidor no permite la reanudación). El archivo se descargará nuevamente desde el principio.
Aceleración de la velocidad de descarga
Si está descargando un archivo grande, es posible que desee controlar la velocidad de descarga para tener ancho de banda adicional para navegar por la web. Puedes hacer esto con el --limit-rate Cambiar. Por ejemplo, para limitar la velocidad de descarga a 512 KB/s, use:
wget <url> --limit-rate=512k
También puedes usar el m Sufijo para un límite en MB/s.
Descargar archivos en segundo plano
De forma predeterminada, wget descarga archivos en primer plano, lo que puede no ser apropiado en todas las situaciones. Como ejemplo, es posible que desee descargar un archivo a su servidor a través de SSH. Sin embargo, no desea mantener una conexión SSH abierta y esperar a que se descargue el archivo. Para descargar archivos en segundo plano, puede usar el -b Opciones como esta:
wget -b <url>
Cuando ejecute este comando, wget le dirá dónde guardar un registro de descarga. Este archivo suele llamarse wget-log , wget-log.1 o similar:
Si más adelante desea monitorear el estado de la descarga, puede hacerlo con:
tail -f wget-log
Esto le mostrará las últimas líneas del estado de la descarga:
Puede presionar Ctrl+C en cualquier momento para dejar de mostrar el progreso. Sin embargo, el progreso de la descarga continuará como de costumbre en segundo plano.
Descarga de archivos a través de malas conexiones de red
Si tiene una conexión a Internet irregular, las descargas a menudo pueden fallar o ser muy lentas. De forma predeterminada, wget intentará una descarga hasta 20 veces en caso de problemas. Sin embargo, en el caso de conexiones a Internet particularmente deficientes, esto puede no ser suficiente. Si experimenta velocidades de descarga lentas con errores frecuentes, puede ejecutar:
wget -t inf --waitretry=3 --timeout=10 --retry-connrefused <url>
Primero tenemos el número de intentos (el -t cambiar a inf . Si wget tiene problemas para descargar el archivo, intentará completar la descarga varias veces. Luego usamos --waitretry para establecer el retraso entre cada intento de reintento en 3 segundos.
A continuación, establecemos el tiempo de espera de la red en 10 segundos con el --timeout Cambiar. Si wget no recibe ninguna respuesta del servidor durante más de 10 segundos, asume que la conexión está caída. Esto ayuda a wget a volver a emitir solicitudes de red para obtener el archivo.
Finalmente tenemos el --retry-connrefused Cambiar. Por lo general, el error de conexión rechazada ocurre cuando el servidor no se está ejecutando. Sin embargo, también puede ocurrir con conexiones de red poco confiables, y este interruptor le dice a wget que intente la descarga nuevamente si encuentra un error de rechazo de conexión.
Descargar archivos recursivamente
Hasta ahora hemos visto cómo descargar archivos específicos usando wget. A veces tiene más sentido descargar partes relacionadas de un sitio web. Wget tiene una función de "descarga recursiva" para este propósito. En este modo, wget descarga el archivo fuente, lo guarda y busca enlaces. Luego descarga cada uno de esos enlaces, guarda esos archivos y extrae los enlaces de ellos. De forma predeterminada, este proceso continúa hasta cinco veces. Sin embargo, puede aumentar o disminuir este límite (denominado "profundidad de recurrencia") según sea necesario.
Por ejemplo, para descargar recursivamente las páginas de la Wikipedia en inglés, use:
wget -r https://en.wikipedia.org/
Estos archivos se almacenan en un directorio con el nombre del sitio. En nuestro caso, el contenido estaría en un directorio llamado . guardado en.wikipedia.org .
Para controlar la "profundidad de recursión" use el -l Bandera. Si desea establecer un valor personalizado como 7, use:
wget -r -l 7 https://en.wikipedia.org/
También puedes usar inf en lugar de un número. Esto permite que wget obtenga todo el contenido de un sitio web con una profundidad de recursión infinita.
De forma predeterminada, wget descarga todos los archivos encontrados en modo recursivo. Si solo está interesado en ciertos tipos de archivos, puede hacerlo con el -A (aceptar) opciones. Por ejemplo, si desea descargar imágenes PNG y JPEG de Wikipedia, use:
wget -r https://en.wikipedia.org/ -A png,jpg,jpeg
Esto descargará todos los archivos de Wikipedia (hasta 5 niveles), pero eliminará todos los archivos que no terminen en las extensiones png , jpg o jpeg . También puedes usar el -R Cambiar. Por ejemplo, para guardar todos los archivos de Wikipedia excepto los documentos PDF, use:
wget -r https://en.wikipedia.org/ -R pdf
Convertir enlaces en archivos descargados
Al descargar archivos de forma recursiva, wget descarga los archivos y los guarda sin cambios. Las páginas web descargadas aún contendrán enlaces que apuntan al sitio web, lo que significa que no puede usar esta copia para uso sin conexión. Afortunadamente, wget tiene una función de conversión de enlaces:convierte los enlaces de una página web en enlaces locales. Para usar esta función, use el -k cambia así:
wget -k -r https://en.wikipedia.org/
Establecer encabezados y cadenas de agente de usuario
Los clientes HTTP (como navegadores y herramientas como wget) envían una "cadena de agente de usuario" como parte de los encabezados HTTP que identifican al cliente. Muchos webmasters bloquean wget configurando su servidor para bloquear solicitudes que contengan "wget" en esta cadena. Para evitar esto, puede anular la cadena de agente de usuario de wget con una personalizada; como el que utiliza su navegador. Para conocer el agente de usuario de su navegador, visite un sitio como echo.opera.com. Copie el agente de usuario de la página y ejecute wget con -U Cambiar:
wget <url> -U "<user-agent-string>"
Por ejemplo, si está usando una Mac, el comando se parece a esto:
wget <url> -U "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
Si es un desarrollador que está probando la funcionalidad de su sitio web, es posible que deba decirle a wget que pase diferentes encabezados HTTP. Puedes hacer esto con el --header Cambiar. Por ejemplo, para enviar el X-Foo Encabezado con valor 123, ejecute el siguiente comando:
wget <url> --header "X-Foo: 123"
Si desea establecer varios encabezados personalizados, puede usar el --header cambie tantas veces como sea necesario.
Descargar archivos protegidos
Hasta ahora, en los ejemplos que hemos visto en la descarga de archivos disponibles públicamente. Sin embargo, puede haber ocasiones en las que necesite descargar archivos de un sitio protegido por inicio de sesión. En estas situaciones, puede usar una extensión de navegador como CurlWget (Chrome) o recopilar (Firefox). Cuando intenta descargar un archivo, estas extensiones generan un comando wget completo que puede usar para descargar el archivo. En este artículo solo hablaremos de CurlWget, aunque cliget funciona de manera similar.
Una vez que haya instalado CurlWget en Chrome, vaya a la configuración de la extensión y cambie la opción de la herramienta de "curl" a "wget". Luego ve a la configuración de descarga (menú de tres puntos> Configuración> Avanzado) y selecciona la opción "Preguntar dónde guardar cada archivo antes de descargar".
A continuación, intente descargar un archivo de Chrome. Cierre el cuadro de diálogo que solicita la ubicación de descarga y haga clic en el icono CurlWget en la barra de herramientas. Esto le dará un comando wget con el agente de usuario, la cookie y otros encabezados establecidos como se muestra a continuación:
Ahora puede copiar y pegar este comando en una ventana de terminal para descargar el archivo. Esto es extremadamente útil en situaciones en las que necesita descargar un archivo protegido por inicio de sesión a un servidor sin cabeza.
Obtener el modo "Araña"
Wget tiene una función de "araña web" que obtiene páginas pero no las guarda. Esto es útil cuando necesita verificar enlaces rotos en un sitio web. Para usar esta opción correctamente, también debe habilitar la "descarga recursiva", que permite a wget escanear el documento y buscar enlaces de navegación.
Si desea escanear https://example.com/ , Ejecutar:
wget --spider -r https://example.com/
Después de que wget obtenga todos los enlaces, mostrará todos los enlaces rotos como se muestra:
También puede guardar este registro en un archivo con el -o Posibilidad:
wget --spider -r https://example.com -o wget.log
Más tarde, puede usar grep para buscar en el registro códigos de estado o archivos específicos. Por ejemplo, para encontrar redireccionamientos 301 en su sitio web, puede usar:
grep -B 301 wget.log