Introducción
MapReduce es un módulo de procesamiento en el proyecto Apache Hadoop. Hadoop es una plataforma creada para abordar big data utilizando una red de computadoras para almacenar y procesar datos.
Lo que es tan atractivo de Hadoop es que los servidores dedicados asequibles son suficientes para ejecutar un clúster. Puede usar hardware de consumo de bajo costo para manejar sus datos.
Hadoop es altamente escalable. Puede comenzar con tan solo una máquina y luego expandir su clúster a una cantidad infinita de servidores. Los dos principales componentes predeterminados de esta biblioteca de software son:
- MapaReducir
- HDFS: Sistema de archivos distribuido Hadoop
En este artículo, hablaremos sobre el primero de los dos módulos. aprenderás qué es MapReduce, cómo funciona y la terminología básica de Hadoop MapReduce .

¿Qué es Hadoop MapReduce?
El modelo de programación de Hadoop MapReduce facilita el procesamiento de grandes datos almacenados en HDFS.
Mediante el uso de los recursos de varias máquinas interconectadas, MapReduce gestiona eficazmente una gran cantidad de datos estructurados y no estructurados. .
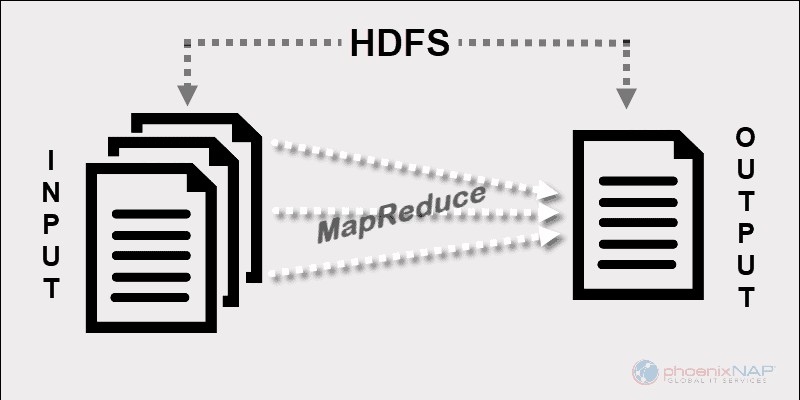
Antes de Spark y otros marcos modernos, esta plataforma era el único actor en el campo del procesamiento distribuido de big data.
MapReduce asigna fragmentos de datos a través de los nodos en un clúster de Hadoop. El objetivo es dividir un conjunto de datos en fragmentos y usar un algoritmo para procesar esos fragmentos al mismo tiempo. El procesamiento paralelo en varias máquinas aumenta considerablemente la velocidad de manejo incluso de petabytes de datos.
Aplicaciones de procesamiento de datos distribuidos
Este marco permite la escritura de aplicaciones para el procesamiento de datos distribuidos. Por lo general, Java es lo que usan la mayoría de los programadores ya que Hadoop se basa en Java .
Sin embargo, puede escribir aplicaciones de MapReduce en otros idiomas, como Ruby o Python. Independientemente del idioma que use un desarrollador, no hay necesidad de preocuparse por el hardware en el que se ejecuta el clúster de Hadoop.
Escalabilidad
La infraestructura de Hadoop puede emplear servidores de nivel empresarial, así como hardware básico. Los creadores de MapReduce tenían en mente la escalabilidad. No es necesario volver a escribir una aplicación si agrega más máquinas. Simplemente cambie la configuración del clúster y MapReduce seguirá funcionando sin interrupciones.
Lo que hace que MapReduce sea tan eficiente es que se ejecuta en los mismos nodos que HDFS. El programador asigna tareas a los nodos donde ya residen los datos. Operar de esta manera aumenta el rendimiento disponible en un clúster.
Cómo funciona MapReduce
A un alto nivel, MapReduce divide los datos de entrada en fragmentos y los distribuye entre diferentes máquinas.
Los fragmentos de entrada consisten en pares clave-valor. Las tareas de mapas en paralelo procesan los datos fragmentados en las máquinas de un clúster. La salida del mapeo luego sirve como entrada para la etapa de reducción. La tarea reduce combina el resultado en una salida de par clave-valor particular y escribe los datos en HDFS.
El sistema de archivos distribuidos de Hadoop generalmente se ejecuta en el mismo conjunto de máquinas que el software MapReduce. Cuando el marco ejecuta un trabajo en los nodos que también almacenan los datos, el tiempo para completar las tareas se reduce significativamente.
Terminología básica de Hadoop MapReduce
Como mencionamos anteriormente, MapReduce es una capa de procesamiento en un entorno Hadoop. MapReduce trabaja en tareas relacionadas con un trabajo. La idea es abordar una solicitud grande dividiéndola en unidades más pequeñas.
JobTracker y TaskTracker
En los primeros días de Hadoop (versión 1), JobTracker y TaskTracker demonios ejecutaron operaciones en MapReduce. En ese momento, un clúster de Hadoop solo podía admitir aplicaciones MapReduce.
Un seguidor de trabajos controlaba la distribución de solicitudes de aplicaciones a los recursos informáticos en un clúster. Dado que supervisaba la ejecución y el estado de MapReduce, residía en un nodo maestro.
Un seguidor de tareas procesó las solicitudes que vinieron del JobTracker. Todos los rastreadores de tareas se distribuyeron en los nodos esclavos en un clúster de Hadoop.
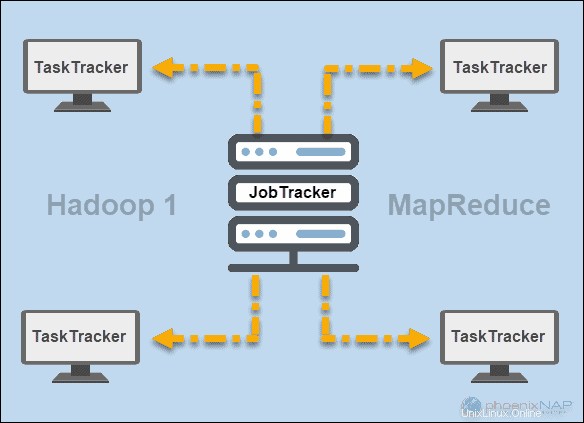
HILO
Posteriormente, en la versión 2 de Hadoop y posteriores, YARN se convirtió en el principal administrador de recursos y programación. De ahí el nombre Yet Another Resource Manager . Yarn también trabajó con otros marcos para el procesamiento distribuido en un clúster de Hadoop.
Trabajo de MapReduce
Un trabajo de MapReduce es la unidad de trabajo superior en el proceso de MapReduce. Es una tarea que los procesos Map and Reduce deben completar. Un trabajo se divide en tareas más pequeñas en un grupo de máquinas para una ejecución más rápida.
Las tareas deben ser lo suficientemente grandes como para justificar el tiempo de manejo de la tarea. Si divide un trabajo en segmentos inusualmente pequeños, el tiempo total para preparar las divisiones y crear tareas puede superar el tiempo necesario para producir el resultado del trabajo real.
Tarea MapReduce
Los trabajos de MapReduce tienen dos tipos de tareas.
Una tarea de mapa es una instancia única de una aplicación MapReduce. Estas tareas determinan qué registros procesar de un bloque de datos. Los datos de entrada se dividen y analizan, en paralelo, en los recursos informáticos asignados en un clúster de Hadoop. Este paso de un trabajo de MapReduce prepara la salida del par
Una tarea de reducción procesa una salida de una tarea de mapa. Al igual que en la etapa del mapa, todas las tareas de reducción ocurren al mismo tiempo y funcionan de forma independiente. Los datos se agregan y combinan para entregar el resultado deseado. El resultado final es un conjunto reducido de pares
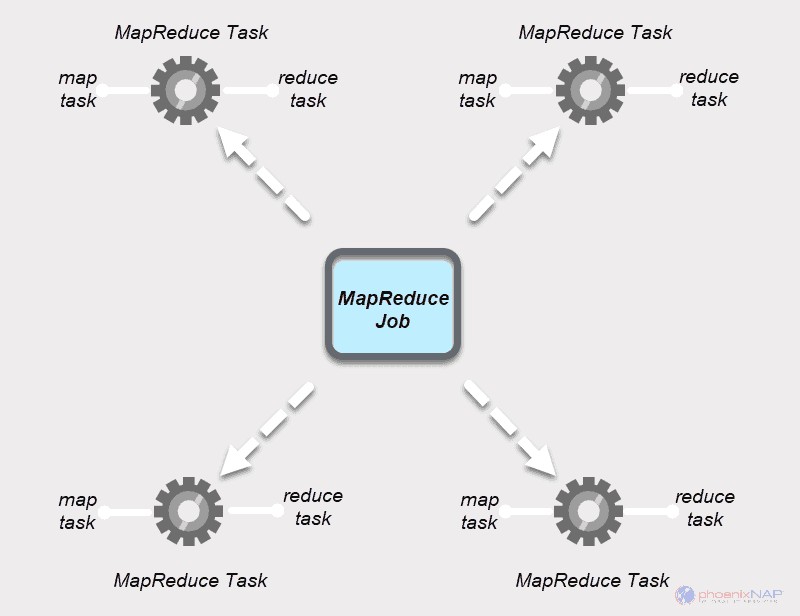
Las etapas Map y Reduce tienen dos partes cada una.
El mapa la primera parte trata de la división de los datos de entrada que se asignan a tareas de mapas individuales. Luego, el mapeo La función crea la salida en forma de pares clave-valor intermedios.
Reducir El escenario tiene un paso aleatorio y un paso reducido. Mezclar toma la salida del mapa y crea una lista de pares clave-valor-lista relacionados. Luego, reduciendo agrega los resultados de la mezcla para producir el resultado final que solicitó la aplicación MapReduce.
Cómo trabajan juntos Hadoop Map y Reduce
Como sugiere el nombre, MapReduce funciona procesando los datos de entrada en dos etapas:Mapa y Reducir . Para demostrar esto, usaremos un ejemplo simple contando el número de ocurrencias de palabras en cada documento.
El resultado final que buscamos es:Cuántas veces aparecen las palabras Apache, Hadoop, Class y Track en total en todos los documentos .
Con fines ilustrativos, el entorno de ejemplo consta de tres nodos. La entrada contiene seis documentos distribuidos en el clúster. Lo mantendremos simple aquí, pero en circunstancias reales, no hay límite. Puede tener miles de servidores y miles de millones de documentos.
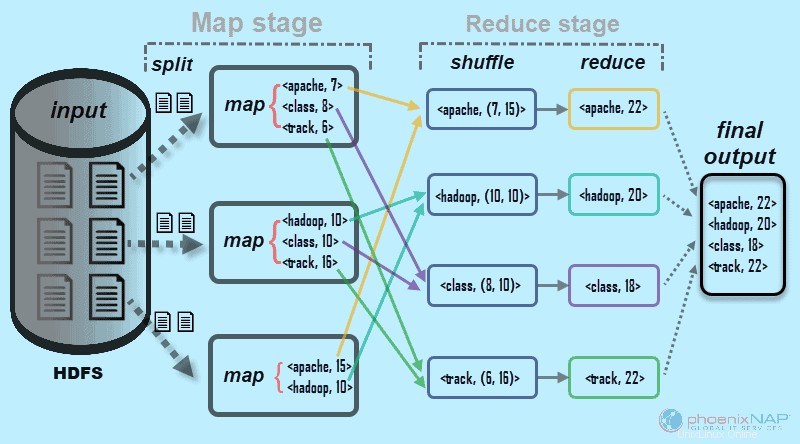
Este proceso se realiza en tareas paralelas en todos los nodos para todos los documentos y brinda un resultado único.
El paso aleatorio asegura las claves Apache, Hadoop, Class, y Rastrear se clasifican para el paso de reducción. Este proceso agrupa los valores por claves en forma de
En nuestro ejemplo del diagrama, las tareas de reducción obtienen los siguientes resultados individuales:
El ejemplo que usamos aquí es básico. MapReduce realiza tareas mucho más complicadas.
Algunos de los casos de uso incluyen:
- Convertir los registros de Apache en valores separados por tabuladores (TSV).
- Determinación del número de direcciones IP únicas en los datos del weblog.
- Realización de modelos y análisis estadísticos complejos.
- Ejecutar algoritmos de aprendizaje automático utilizando diferentes marcos, como Mahout.
Cómo divide Hadoop los datos de entrada del mapa
El particionador es responsable de procesar la salida del mapa. Una vez que MapReduce divide los datos en fragmentos y los asigna a las tareas del mapa, el marco divide los datos clave-valor. Este proceso tiene lugar antes de que se produzca la salida final de la tarea del mapeador.
MapReduce divide y ordena la salida según la clave. Aquí, todos los valores de las claves individuales se agrupan y el particionador crea una lista que contiene los valores asociados con cada clave. Al enviar todos los valores de una sola clave al mismo reductor, el particionador garantiza una distribución equitativa de la salida del mapa al reductor.
El particionador predeterminado está bien configurado para muchos casos de uso, pero puede reconfigurar cómo MapReduce particiona los datos.
Si utiliza un particionador personalizado, asegúrese de que el tamaño de los datos preparados para cada reductor sea aproximadamente el mismo. Cuando divide los datos de manera desigual, una tarea de reducción puede tardar mucho más en completarse. Esto ralentizaría todo el trabajo de MapReduce.