Introducción
Apache Hadoop es un marco excepcionalmente exitoso que logra resolver los muchos desafíos que plantean los grandes datos. Esta solución eficiente distribuye la potencia de almacenamiento y procesamiento entre miles de nodos dentro de un clúster. Una plataforma Hadoop completamente desarrollada incluye una colección de herramientas que mejoran el marco básico de Hadoop y le permiten superar cualquier obstáculo.
La arquitectura subyacente y el papel de las muchas herramientas disponibles en un ecosistema de Hadoop pueden resultar complicados para los recién llegados.
Este artículo utiliza muchos diagramas y descripciones sencillas para ayudarlo a explorar el emocionante ecosistema de Apache Hadoop.

Descripción general de la arquitectura de Hadoop
Big data, con su inmenso volumen y estructuras de datos variables, ha abrumado a los marcos y herramientas de redes tradicionales. El uso de hardware de alto rendimiento y servidores especializados puede ayudar, pero son inflexibles y tienen un precio considerable.
Hadoop logra procesar y almacenar grandes cantidades de datos mediante el uso de hardware básico interconectado asequible. Cientos o incluso miles de servidores dedicados de bajo costo que trabajan juntos para almacenar y procesar datos dentro de un solo ecosistema.
El sistema de archivos distribuido de Hadoop (HDFS), YARN y MapReduce están en el corazón de ese ecosistema. HDFS es un conjunto de protocolos que se utilizan para almacenar grandes conjuntos de datos, mientras que MapReduce procesa de manera eficiente los datos entrantes.
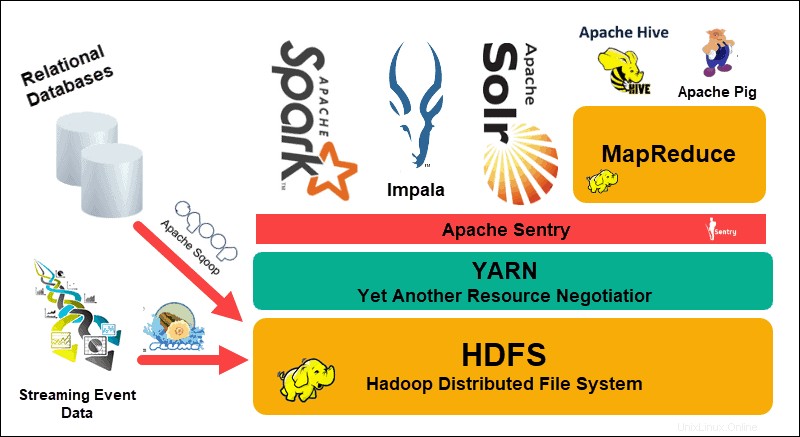
Un clúster de Hadoop consta de uno o varios nodos maestros y muchos más, los denominados nodos esclavos. HDFS y MapReduce forman una base flexible que se puede escalar linealmente agregando nodos adicionales. Sin embargo, la complejidad de los grandes datos significa que siempre hay margen de mejora.
Otro negociador de recursos más (YARN) fue creado para mejorar la gestión de recursos y los procesos de programación en un clúster de Hadoop. La introducción de YARN, con su interfaz genérica, abrió la puerta para que otras herramientas de procesamiento de datos se incorporaran al ecosistema de Hadoop.
Desde entonces, una vibrante comunidad de desarrolladores ha creado numerosos proyectos Apache de código abierto para complementar Hadoop. Muchas de estas soluciones tienen nombres llamativos y creativos como Apache Hive, Impala, Pig, Sqoop, Spark y Flume. Estas herramientas compilan y procesan varios tipos de datos. También proporcionan interfaces fáciles de usar, servicios de mensajería y mejoran las velocidades de procesamiento del clúster.
Una pila de software ampliada, con HDFS, YARN y MapReduce en su núcleo, convierte a Hadoop en la solución de referencia para el procesamiento de big data.
Comprender las capas de la arquitectura Hadoop
La separación de los elementos de los sistemas distribuidos en capas funcionales ayuda a optimizar la gestión y el desarrollo de datos. Los desarrolladores pueden trabajar en marcos sin afectar negativamente a otros procesos en el ecosistema más amplio.
Hadoop se puede dividir en cuatro (4) capas distintivas.
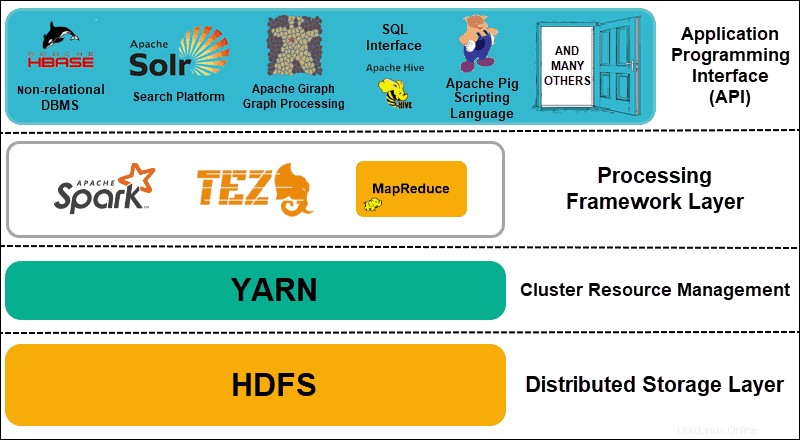
1. Capa de almacenamiento distribuido
Cada nodo en un clúster de Hadoop tiene su propio espacio en disco, memoria, ancho de banda y procesamiento. Los datos entrantes se dividen en bloques de datos individuales, que luego se almacenan en la capa de almacenamiento distribuido de HDFS. HDFS asume que cada unidad de disco y nodo esclavo dentro del clúster no es confiable. Como precaución, HDFS almacena tres copias de cada conjunto de datos en todo el clúster. El nodo principal de HDFS (NameNode ) conserva los metadatos del bloque de datos individual y todas sus réplicas.
2. Gestión de recursos de clúster
Hadoop necesita coordinar los nodos a la perfección para que innumerables aplicaciones y usuarios compartan sus recursos de manera efectiva. Inicialmente, MapReduce manejaba tanto la gestión de recursos como el procesamiento de datos. YARN separa estas dos funciones. Como herramienta de administración de recursos de facto para Hadoop, YARN ahora puede asignar recursos a diferentes marcos escritos para Hadoop. Estos incluyen proyectos como Apache Pig, Hive, Giraph, Zookeeper, así como el mismo MapReduce.
3. Capa del marco de procesamiento
La capa de procesamiento consta de marcos que analizan y procesan conjuntos de datos que ingresan al clúster. Los conjuntos de datos estructurados y no estructurados se mapean, barajan, ordenan, fusionan y reducen a bloques de datos manejables más pequeños. Estas operaciones se distribuyen en múltiples nodos lo más cerca posible de los servidores donde se encuentran los datos. Los marcos de computación como Spark, Storm, Tez ahora permiten el procesamiento en tiempo real, el procesamiento de consultas interactivas y otras opciones de programación que ayudan al motor MapReduce y utilizan HDFS de manera mucho más eficiente.
4. Interfaz de programación de aplicaciones
La introducción de YARN en Hadoop 2 ha llevado a la creación de nuevos marcos de procesamiento y API. Big data continúa expandiéndose y la variedad de herramientas debe seguir ese crecimiento. Los proyectos que se enfocan en plataformas de búsqueda, transmisión de datos, interfaces fáciles de usar, lenguajes de programación, mensajería, conmutación por error y seguridad son una parte compleja de un ecosistema integral de Hadoop.
HDFS explicado
El sistema de archivos distribuidos de Hadoop (HDFS) es tolerante a fallas por diseño. Los datos se almacenan en bloques de datos individuales en tres copias separadas en varios nodos y bastidores de servidores. Si falla un nodo o incluso un rack completo, el impacto en el sistema en general es insignificante.
Nodos de datos procesar y almacenar bloques de datos, mientras que NameNodes administre los muchos DataNodes, mantenga los metadatos del bloque de datos y controle el acceso de los clientes.
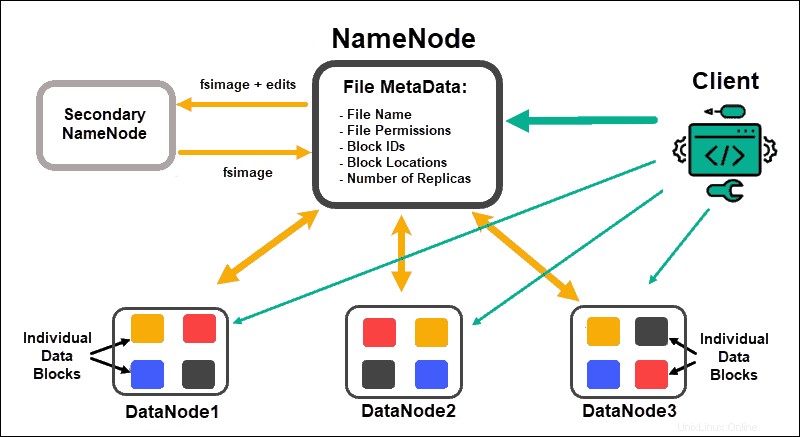
NombreNodo
Inicialmente, los datos se dividen en bloques de datos abstractos. Los metadatos del archivo para estos bloques, que incluyen el nombre del archivo, los permisos del archivo, las ID, las ubicaciones y la cantidad de réplicas, se almacenan en una imagen fs en la memoria local de NameNode.
Si un NameNode falla, HDFS no podrá ubicar ninguno de los conjuntos de datos distribuidos a través de los DataNodes. Esto convierte a NameNode en el único punto de falla para todo el clúster. Esta vulnerabilidad se resuelve implementando un NameNode secundario o un NameNode en espera.
Nodo de nombre secundario
El NameNode secundario sirvió como la solución de respaldo principal en las primeras versiones de Hadoop. El NameNode secundario, de vez en cuando, descarga la instancia actual de fsimage y edita los registros del NameNode y los fusiona. La fsimage editada se puede recuperar y restaurar en el NameNode principal.
La conmutación por error no es un proceso automatizado, ya que un administrador necesitaría recuperar los datos del NameNode secundario manualmente.
Nodo de nombre en espera
La alta disponibilidad La característica se introdujo en Hadoop 2.0 y versiones posteriores para evitar cualquier tiempo de inactividad en caso de falla de NameNode. Esta característica le permite mantener dos NameNodes ejecutándose en nodos maestros dedicados separados.
El NameNode en espera es una conmutación por error automatizada en caso de que un NameNode activo deje de estar disponible. El Standby NameNode también lleva a cabo el proceso de verificación de puntos. Debido a esta propiedad, el NameNode secundario y en espera no son compatibles. Un clúster de Hadoop puede mantener uno u otro.
Guardián del zoológico
Zookeeper es una herramienta liviana que admite alta disponibilidad y redundancia. Un NameNode en espera mantiene una sesión activa con el demonio Zookeeper.
Si un NameNode activo falla, el demonio Zookeeper detecta la falla y lleva a cabo el proceso de conmutación por error a un nuevo NameNode. Utilice Zookeeper para automatizar las conmutaciones por error y minimizar el impacto que puede tener una falla de NameNode en el clúster.
Nodo de datos
Cada DataNode en un clúster utiliza un proceso en segundo plano para almacenar los bloques de datos individuales en servidores esclavos.
De manera predeterminada, HDFS almacena tres copias de cada bloque de datos en DataNodes separados. El NameNode utiliza una política de colocación con reconocimiento de racks. Esto significa que los DataNodes que contienen las réplicas de bloques de datos no pueden ubicarse en el mismo rack de servidor.
Un DataNode se comunica y acepta instrucciones del NameNode aproximadamente veinte veces por minuto. Además, informa el estado y la salud de los bloques de datos ubicados en ese nodo una vez por hora. Según la información proporcionada, NameNode puede solicitar a DataNode que cree réplicas adicionales, las elimine o disminuya la cantidad de bloques de datos presentes en el nodo.
Política de colocación consciente de rack
Uno de los principales objetivos de un sistema de almacenamiento distribuido como HDFS es mantener una alta disponibilidad y replicación. Por lo tanto, los bloques de datos deben distribuirse no solo en diferentes DataNodes, sino también en nodos ubicados en diferentes racks de servidores.
Esto garantiza que la falla de un bastidor completo no finalice todas las réplicas de datos. El NameNode de HDFS mantiene una política predeterminada de colocación de réplicas en rack:
- La primera réplica del bloque de datos se coloca en el mismo nodo que el cliente.
- La segunda réplica se coloca automáticamente en un DataNode aleatorio en un bastidor diferente.
- La tercera réplica se coloca en un DataNode separado en el mismo bastidor que la segunda réplica.
- Cualquier réplica adicional se almacena en DataNodes aleatorios en todo el clúster.
Esta política de colocación de bastidores mantiene solo una réplica por nodo y establece un límite de dos réplicas por bastidor de servidor.
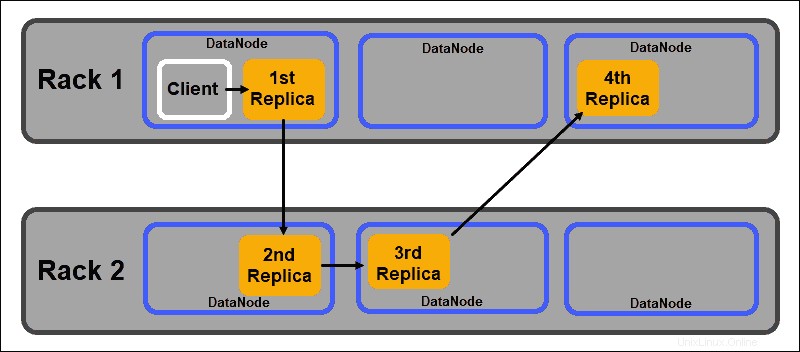
Las fallas de los racks son mucho menos frecuentes que las fallas de los nodos. HDFS garantiza una alta confiabilidad almacenando siempre al menos una réplica de bloque de datos en un DataNode en un bastidor diferente.
HILO explicado
YARN (Yet Another Resource Negotiator) es el recurso de administración de clústeres predeterminado para Hadoop 2 y Hadoop 3. En versiones anteriores de Hadoop, MapReduce solía realizar el procesamiento de datos y la asignación de recursos. Con el tiempo, la necesidad de dividir el procesamiento y la gestión de recursos condujo al desarrollo de YARN.
La función de asignación de recursos de YARN lo ubica entre la capa de almacenamiento, representada por HDFS, y el motor de procesamiento de MapReduce. YARN también proporciona una interfaz genérica que le permite implementar nuevos motores de procesamiento para varios tipos de datos.
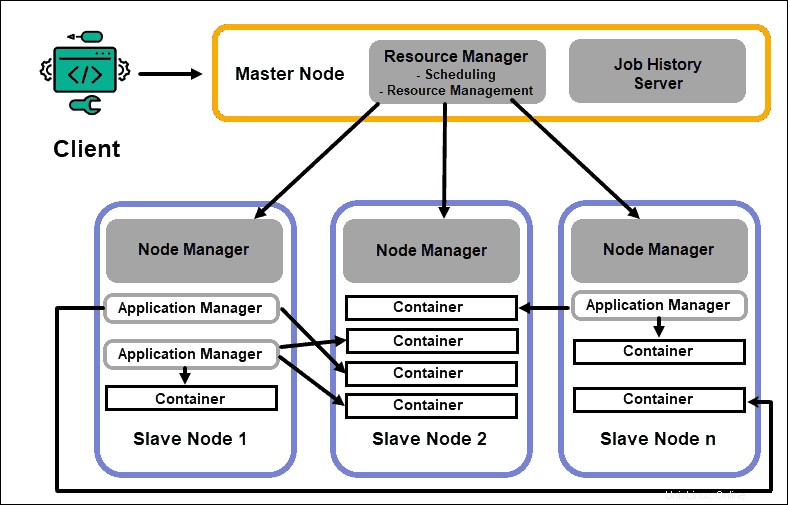
Administrador de recursos
El demonio ResourceManager (RM) controla todos los recursos de procesamiento en un clúster de Hadoop. Su propósito principal es designar recursos para aplicaciones individuales ubicadas en los nodos esclavos. Mantiene una visión global de los procesos planificados y en curso, gestiona las solicitudes de recursos y programa y asigna los recursos en consecuencia. ResourceManager es vital para el marco Hadoop y debe ejecutarse en un nodo maestro dedicado.
El único enfoque de RM es programar cargas de trabajo. A diferencia de MapReduce, no tiene interés en las conmutaciones por error ni en las tareas de procesamiento individuales. Esta separación de tareas en YARN es lo que hace que Hadoop sea inherentemente escalable y lo convierte en una plataforma informática completamente desarrollada.
Administrador de nodos
Cada nodo esclavo tiene un servicio de procesamiento de NodeManager y un servicio de almacenamiento de DataNode. Juntos forman la columna vertebral de un sistema distribuido Hadoop.
El DataNode, como se mencionó anteriormente, es un elemento de HDFS y está controlado por NameNode. El NodeManager, de manera similar, actúa como esclavo del ResourceManager. La función principal del demonio NodeManager es realizar un seguimiento de los datos de recursos de procesamiento en su nodo esclavo y enviar informes periódicos al ResourceManager.
Contenedores
Los recursos de procesamiento en un clúster de Hadoop siempre se implementan en contenedores. Un contenedor tiene memoria, archivos del sistema y espacio de procesamiento.
La implementación de un contenedor es genérica y puede ejecutar cualquier recurso personalizado solicitado en cualquier sistema. Si la cantidad solicitada de recursos del clúster está dentro de los límites aceptables, el RM aprueba y programa la implementación de ese contenedor.
Los procesos del contenedor en un nodo esclavo son inicialmente aprovisionados, monitoreados y rastreados por NodeManager en ese nodo esclavo específico.
Maestro de aplicaciones
Cada contenedor en un nodo esclavo tiene su maestro de aplicaciones dedicado. Los maestros de aplicaciones también se implementan en un contenedor. Incluso MapReduce tiene un maestro de aplicaciones que ejecuta map y reduce tareas.
Mientras esté activo, un maestro de aplicaciones envía mensajes al administrador de recursos sobre su estado actual y el estado de la aplicación que supervisa. En función de la información proporcionada, el administrador de recursos programa recursos adicionales o los asigna en otro lugar del clúster si ya no se necesitan.
Application Master supervisa el ciclo de vida completo de una aplicación, desde solicitar los contenedores necesarios del RM hasta enviar solicitudes de arrendamiento de contenedores al NodeManager.
Servidor de historial de trabajos
JobHistory Server permite a los usuarios recuperar información sobre las aplicaciones que han completado su actividad. La API REST proporciona interoperabilidad y puede informar dinámicamente a los usuarios sobre los trabajos actuales y completados atendidos por el servidor en cuestión.
¿Cómo funciona YARN?
Un flujo de trabajo básico para la implementación en YARN comienza cuando una aplicación cliente envía una solicitud a ResourceManager.
- El Administrador de recursos instruye a un NodeManager para iniciar un maestro de aplicaciones para esta solicitud, que luego se inicia en un contenedor.
- El maestro de aplicaciones recién creado se registra en el RM . El Application Master procede a contactar al HDFS NameNode y determina la ubicación de los bloques de datos necesarios y calcula la cantidad de mapa y reduce las tareas necesarias para procesar los datos.
- El maestro de aplicaciones luego solicita los recursos necesarios del RM y continúa comunicando los requisitos de recursos a lo largo del ciclo de vida del contenedor.
- El RM programa los recursos junto con las solicitudes de todos los demás maestros de aplicaciones y pone en cola sus solicitudes. A medida que los recursos están disponibles, el RM los pone a disposición del maestro de aplicaciones en un nodo esclavo específico.
- El administrador de aplicaciones contacta con el NodeManager para ese nodo esclavo y le solicita que cree un contenedor proporcionando variables, tokens de autenticación y la cadena de comando para el proceso. Según esa solicitud, el NodeManager crea e inicia el contenedor .
- El administrador de aplicaciones luego monitorea el proceso y reacciona en caso de falla reiniciando el proceso en la siguiente ranura disponible. Si falla después de cuatro intentos diferentes, todo el trabajo falla. A lo largo de este proceso, el administrador de aplicaciones responde a las solicitudes de estado del cliente.
Una vez que se completan todas las tareas, Application Master envía el resultado a la aplicación cliente, informa al RM que la aplicación ha completado su tarea, se da de baja del Administrador de recursos y se apaga.
El RM también puede indicarle a NameNode que finalice un contenedor específico durante el proceso en caso de un cambio de prioridad de procesamiento.
Explicación de MapReduce
MapReduce es un algoritmo de programación que procesa datos dispersos en el clúster de Hadoop. Al igual que con cualquier proceso en Hadoop, una vez que se inicia un trabajo de MapReduce, ResourceManager solicita un maestro de aplicaciones para administrar y monitorear el ciclo de vida del trabajo de MapReduce.
Application Master localiza los bloques de datos requeridos en función de la información almacenada en NameNode. El AM también informa al ResourceManager para iniciar un trabajo de MapReduce en el mismo nodo en el que se encuentran los bloques de datos. Siempre que sea posible, los datos se procesan localmente en los nodos esclavos para reducir el uso del ancho de banda y mejorar la eficiencia del clúster.
Los datos de entrada se asignan, se mezclan y luego se reducen a un resultado agregado. El resultado del trabajo de MapReduce se almacena y replica en HDFS.
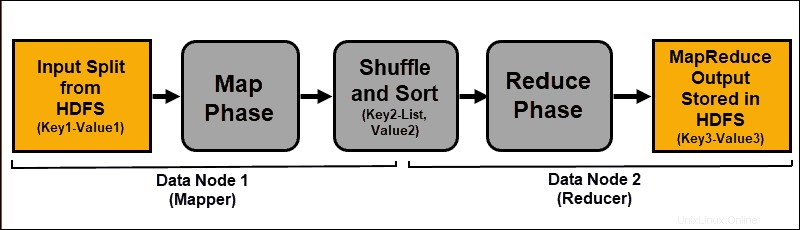
Los servidores de Hadoop que realizan las tareas de mapeo y reducción a menudo se denominan Mapeadores. y Reductores .
El ResourceManager decide cuántos mapeadores usar. Esta decisión depende del tamaño de los datos procesados y del bloque de memoria disponible en cada servidor del mapeador.
Fase del mapa
El proceso de mapeo ingiere expresiones lógicas individuales de los datos almacenados en los bloques de datos HDFS. Estas expresiones pueden abarcar varios bloques de datos y se denominan divisiones de entrada. . Las divisiones de entrada se introducen en el proceso de mapeo como pares clave-valor .
Una tarea de mapeador pasa por cada par clave-valor y crea un nuevo conjunto de pares clave-valor, distinto de los datos de entrada originales. El surtido completo de todos los pares clave-valor representa el resultado de la tarea del mapeador.
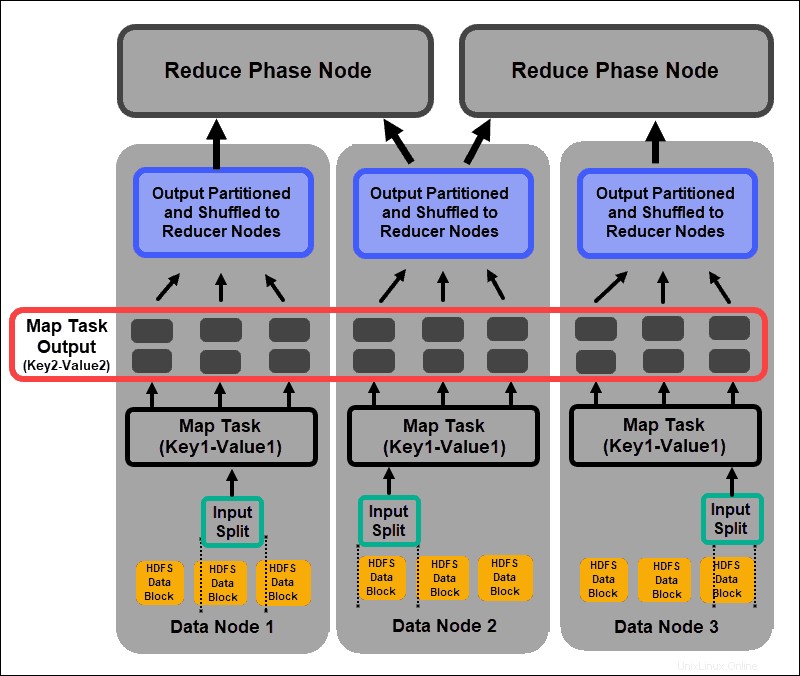
Según la clave de cada par, los datos se agrupan, se dividen y se barajan en los nodos reductores.
Fase de barajar y ordenar
Aleatorio es un proceso en el que los resultados de todas las tareas del mapa se copian en los nodos reductores. La copia de la salida de la tarea del mapa es el único intercambio de datos entre nodos durante todo el trabajo de MapReduce.
La salida de una tarea de mapa debe organizarse para mejorar la eficiencia de la fase de reducción. Los pares clave-valor mapeados, que se barajan desde los nodos del mapeador, se ordenan por clave con los valores correspondientes. Una fase de reducción comienza después de ordenar la entrada por clave en un único archivo de entrada.
Las fases de barajar y clasificar se ejecutan en paralelo. Incluso cuando los resultados del mapa se recuperan de los nodos del mapeador, se agrupan y clasifican en los nodos del reductor.
Reducir Fase
Las salidas del mapa se barajan y clasifican en un solo archivo de entrada de reducción ubicado en el nodo de reducción. Una función de reducción utiliza el archivo de entrada para agregar los valores en función de las claves asignadas correspondientes. El resultado del proceso de reducción es un nuevo par clave-valor. Este resultado representa la salida de todo el trabajo de MapReduce y, de forma predeterminada, se almacena en HDFS.
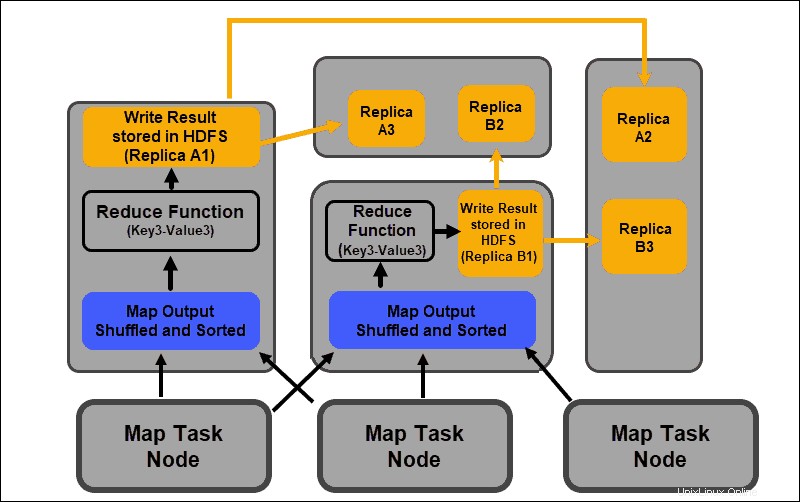
Todas las tareas de reducción tienen lugar simultáneamente y funcionan independientemente unas de otras. Una tarea de reducción también es opcional.
Puede haber casos en los que el resultado de una tarea de mapa sea el resultado deseado y no sea necesario producir un único valor de salida.
Prácticas recomendadas para implementar Hadoop
La siguiente sección explica cómo el hardware subyacente, los permisos de usuario y el mantenimiento de un clúster equilibrado y confiable pueden ayudarlo a aprovechar al máximo su ecosistema de Hadoop.
Ajustar los permisos de usuario de Hadoop
El protocolo de red Kerberos es el principal sistema de autorización de Hadoop. Se asegura de que solo los nodos y usuarios verificados tengan acceso y operen dentro del clúster.
Una vez que instale y configure un Centro de distribución de claves de Kerberos, debe realizar varios cambios en los archivos de configuración de Hadoop. El core-site.xml de Hadoop El archivo define parámetros para todo el clúster de Hadoop. Configure hadoop.security.authentication parámetro dentro del core-site.xml a kerberos . La misma propiedad debe establecerse en true para habilitar la autorización del servicio.
Listas de control de acceso en hadoop-policy-xml El archivo también se puede editar para otorgar diferentes niveles de acceso a usuarios específicos. Lograr un equilibrio entre los privilegios de usuario necesarios y otorgar demasiados privilegios puede ser difícil con las herramientas básicas de línea de comandos.
Es una buena idea usar marcos de seguridad adicionales como Apache Guardabosques o Apache Centinela . Estas herramientas lo ayudan a administrar todas las tareas relacionadas con la seguridad desde un entorno central y fácil de usar. Úselos para proporcionar autorización específica para tareas y usuarios mientras mantiene un control total sobre el proceso.
Clúster de Hadoop equilibrado
Un sistema distribuido como Hadoop es un entorno dinámico. Agregar nuevos nodos o eliminar los antiguos puede crear un desequilibrio temporal dentro de un clúster. Los bloques de datos pueden replicarse insuficientemente.
Su objetivo es distribuir los datos de la manera más uniforme posible entre los nodos esclavos de un clúster. Utilice la utilidad de equilibrio de clústeres de Hadoop para cambiar la configuración predefinida. Defina su política de equilibrio con el hdfs balancer dominio. Este comando y sus opciones le permiten modificar los umbrales de capacidad del disco del nodo.
El tamaño de bloque predeterminado a partir de Hadoop 2.x es de 128 MB. Hadoop permite que un usuario cambie esta configuración. Considere cambiar el tamaño del bloque de datos predeterminado si procesa cantidades considerables de datos; de lo contrario, la cantidad de trabajos iniciados podría abrumar a su clúster.
Si aumenta el tamaño del bloque de datos, la entrada a la tarea del mapa será mayor y se iniciarán menos tareas del mapa. Esto, a su vez, significa que la fase de reproducción aleatoria tiene un rendimiento mucho mejor al transferir datos al nodo reductor. Este simple ajuste puede reducir el tiempo que tarda en completarse un trabajo de MapReduce.
Escalado de Hadoop (hardware)
El NameNode es un elemento vital de su clúster de Hadoop. Involucre tantos núcleos de procesamiento como sea posible para este nodo. La cantidad de RAM define la cantidad de datos que se leen de la memoria del nodo. Si sobrecarga los recursos disponibles para su Master Node, restringe la capacidad de crecimiento de su clúster.
Las fuentes de alimentación redundantes siempre deben reservarse para el Master Node. Trate de no emplear fuentes de alimentación redundantes y valiosos recursos de hardware para los nodos de datos. Son una parte importante de un ecosistema Hadoop, sin embargo, son prescindibles. Los servidores dedicados asequibles, con capacidades de procesamiento intermedias, son ideales para los nodos de datos, ya que consumen menos energía y producen menos calor.
Las capacidades de escalado de Hadoop son la principal fuerza impulsora detrás de su implementación generalizada. Siempre es necesario tener suficiente espacio para que tu clúster se expanda. La adición rápida de nuevos nodos o espacio en disco requiere alimentación, redes y refrigeración adicionales. Todo esto puede resultar muy difícil sin una planificación meticulosa para el probable crecimiento futuro.
Escalado de Hadoop (software)
Los nuevos proyectos de Hadoop se desarrollan regularmente y los existentes se mejoran con funciones más avanzadas.
Incluso las herramientas heredadas se están actualizando para permitirles beneficiarse de un ecosistema de Hadoop. Esté siempre atento a los nuevos desarrollos en este frente. La variedad y el volumen de los conjuntos de datos entrantes exigen la introducción de marcos adicionales.
La implementación de una nueva herramienta fácil de usar puede resolver un dilema técnico más rápido que intentar crear una solución personalizada. No se aleje de las soluciones rápidas comerciales ya desarrolladas. El mercado está saturado de proveedores que ofrecen Hadoop como servicio o herramientas independientes personalizadas.
Fiabilidad de datos y tolerancia a fallos
Hlatido del corazón es una señal de protocolo de enlace TCP recurrente. Los DataNodes, ubicados en cada servidor esclavo, envían continuamente un latido al NameNode ubicado en el servidor maestro. El marco de tiempo de latido predeterminado es de tres segundos. Si NameNode no recibe una señal durante más de diez minutos, cancela DataNode y sus bloques de datos se programan automáticamente en diferentes nodos.
No baje la frecuencia de los latidos del corazón para intentar aligerar la carga en el NameNode. Mantener a los NameNodes "informados" es crucial, incluso en clústeres extremadamente grandes. Sin una afluencia regular y frecuente de latidos, NameNode se ve gravemente obstaculizado y no puede controlar el clúster con tanta eficacia.
Para evitar consecuencias graves por fallas, mantenga la configuración predeterminada de reconocimiento de racks y almacene réplicas de bloques de datos en los racks de servidores. Si pierde un bastidor de servidor, las otras réplicas sobreviven y el impacto en el procesamiento de datos es mínimo.