| Tormenta | Spark |
|---|
| Lenguajes de programación | Integración multilingüe | Soporte para Python, R, Java, Scala |
| Modelo de procesamiento | Procesamiento de secuencias con microlotes disponibles a través de Trident | Procesamiento por lotes con microlotes disponibles a través de Streaming |
| Primitivos | Flujo Tuple
lote de tuplas
Partición | DStream |
| Fiabilidad | Exactamente una vez (Trident)
Al menos una vez
A lo sumo una vez | Exactamente una vez |
| Tolerancia a fallos | Reinicio automático por parte del proceso supervisor | Reinicio del trabajador a través de administradores de recursos |
| Administración de estados | Compatible con Trident | Soportado a través de Streaming |
| Facilidad de uso | Más difícil de operar e implementar | Más fácil de administrar e implementar |
Lenguajes de programación
La disponibilidad de integración con otros lenguajes de programación es uno de los principales factores al elegir entre Storm y Spark y una de las diferencias clave entre las dos tecnologías.
Tormenta
Storm tiene un multilenguaje característica, haciéndola disponible para prácticamente cualquier lenguaje de programación. La API de Trident para transmisión y procesamiento es compatible con:
Chispa
Spark proporciona API de transmisión de alto nivel para los siguientes idiomas:
Algunas funciones avanzadas, como la transmisión desde fuentes personalizadas, no están disponibles para Python. Sin embargo, la transmisión desde fuentes externas avanzadas como Kafka o Kinesis está disponible para los tres idiomas.
Modelo de procesamiento
El modelo de procesamiento define cómo se actualiza la transmisión de datos. La información se procesa de una de las siguientes maneras:
- Un registro a la vez.
- En lotes discretizados.
Tormenta
El modelo de procesamiento de Core Storm opera en flujos de tuplas directamente, un registro a la vez , lo que la convierte en una tecnología de transmisión en tiempo real adecuada. La API de Trident agrega la opción de usar micro-lotes .
Chispa
El modelo de procesamiento de Spark divide los datos en lotes , agrupando los registros antes de su posterior procesamiento. La API de Spark Streaming ofrece la opción de dividir los datos en microlotes .
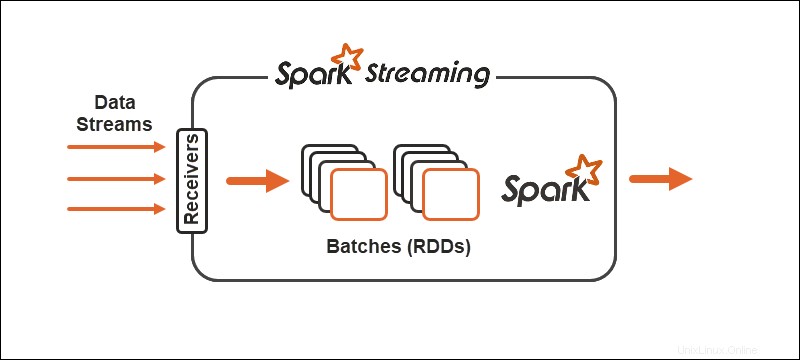
Primitivos
Las primitivas representan los componentes básicos de ambas tecnologías y la forma en que se ejecutan las operaciones de transformación en los datos.
Tormenta
Core Storm opera en tuple streams , mientras que Trident opera en lotes de tupla y particiones . La API de Trident funciona en colecciones de manera similar a las abstracciones de alto nivel para Hadoop. Las principales primitivas de Storm son:
- Caños que generan una transmisión en tiempo real desde una fuente.
- Pernos que realizan el procesamiento de datos y mantienen la persistencia.
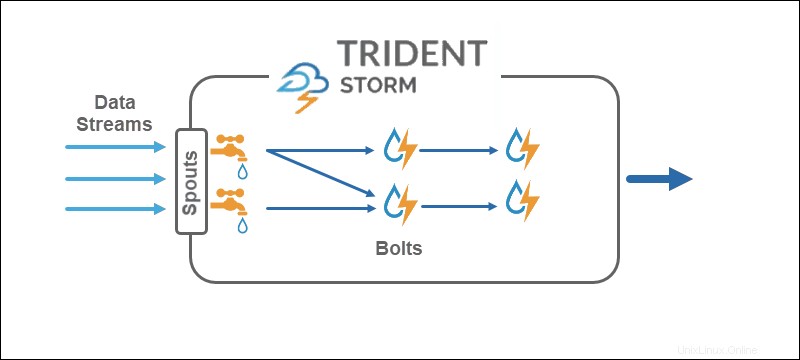
En la topología Trident, las operaciones se agrupan en tornillos. Los bys de grupo, las uniones, las agregaciones, las funciones de ejecución y los filtros están disponibles en lotes aislados y en diferentes colecciones. La agregación se almacena de forma persistente en la memoria respaldada por HDFS o en algún otro almacén como Cassandra.
Chispa
Con Spark Streaming, el flujo continuo de datos se divide en flujos diferenciados (DStreams), una secuencia de Bases de datos distribuidas resistentes (RDD).
Spark permite dos tipos generales de operadores en primitivas:
1. Operadores de transformación de flujo donde un DStream se transforma en otro DStream.
2. Operadores de salida ayudar a escribir información en sistemas externos.
Confiabilidad
La confiabilidad se refiere a la garantía de la entrega de datos. Hay tres posibles garantías cuando se trata de la confiabilidad de la transmisión de datos:
- Al menos una vez . Los datos se entregan una vez, con la posibilidad de entregas múltiples también.
- Como máximo una vez . Los datos se entregan solo una vez y se eliminan los duplicados. Existe la posibilidad de que los datos no lleguen.
- Exactamente una vez . Los datos se entregan una vez, sin pérdidas ni duplicados. La opción de garantía es óptima para la transmisión de datos, aunque difícil de lograr.
Tormenta
Storm es flexible cuando se trata de la confiabilidad de la transmisión de datos. Básicamente, al menos una vez y como máximo una vez las opciones son posibles. Junto con la API de Trident, las tres configuraciones están disponibles .
Chispa
Spark intenta tomar la ruta óptima centrándose en el exactamente una vez configuración de transmisión de datos. Si un trabajador o conductor falla, al menos una vez se aplica la semántica.
Tolerancia a fallos
La tolerancia a fallas define el comportamiento de las tecnologías de transmisión en caso de falla. Tanto Spark como Storm son tolerantes a fallas en un nivel similar.
Chispa
En caso de falla del trabajador, Spark reinicia a los trabajadores a través del administrador de recursos, como YARN. La falla del controlador utiliza un punto de control de datos para la recuperación.
Tormenta
Si un proceso falla en Storm o Trident, el proceso de supervisión maneja el reinicio automáticamente. ZooKeeper juega un papel crucial en la recuperación y gestión del estado.
Gestión de Estado
Tanto Spark Streaming como Storm Trident tienen tecnologías de gestión de estado integradas. El seguimiento de estados ayuda a lograr la tolerancia a fallas, así como la garantía de entrega exactamente una vez.
Facilidad de uso y desarrollo
La facilidad de uso y desarrollo depende de qué tan bien documentada esté la tecnología y qué tan fácil sea operar las transmisiones.
Chispa
Spark es más fácil de implementar y desarrollar a partir de las dos tecnologías. La transmisión está bien documentada y se implementa en clústeres de Spark. Los trabajos de transmisión son intercambiables con los trabajos por lotes.
Tormenta
Storm es un poco más complicado de configurar y desarrollar, ya que contiene una dependencia del clúster de ZooKeeper. La ventaja de usar Storm se debe a la función multilingüe.
Tormenta vs Chispa:¿Cómo elegir?
La elección entre Storm y Spark depende del proyecto y de las tecnologías disponibles. Uno de los principales factores es el lenguaje de programación y las garantías de confiabilidad en la entrega de datos.
Si bien existen diferencias entre la transmisión y el procesamiento de dos datos, el mejor camino a seguir es probar ambas tecnologías para ver qué funciona mejor para usted y el flujo de datos en cuestión.
