Los administradores de sistemas tienen muchas herramientas para ver y administrar los procesos en ejecución. Para mí, estos solían ser principalmente top , encima y htop . Hace unos años, encontré Glances, una herramienta que muestra información que ninguno de mis otros favoritos muestra. Todas estas herramientas monitorean el uso de la CPU y la memoria, y la mayoría de ellas enumeran información sobre los procesos en ejecución (como mínimo). Sin embargo, Glances también supervisa la E/S del sistema de archivos, la E/S de la red y las lecturas de sensores que pueden mostrar la temperatura de la CPU y de otro hardware, así como las velocidades de los ventiladores y el uso del disco por dispositivo de hardware y volumen lógico.
Miradas
Mencioné Glances en mi artículo 4 herramientas de código abierto para el monitoreo del sistema Linux , pero profundizaré en ello en este artículo. Si leyó mi artículo anterior, parte de esta información puede resultarle familiar, pero también debería encontrar algunas cosas nuevas aquí.
Glances es multiplataforma porque está escrito en Python. Se puede instalar en Windows y otros hosts con versiones actuales de Python instaladas. La mayoría de las distribuciones de Linux (Fedora en mi caso) tienen Glances en sus repositorios. Si no es así, o si está utilizando un sistema operativo diferente (como Windows), o si simplemente desea obtenerlo directamente desde la fuente, puede encontrar instrucciones para descargarlo e instalarlo en el repositorio de GitHub de Glances.
Sugiero ejecutar Glances en una máquina de prueba mientras prueba los comandos de este artículo. Si no tiene un host físico disponible para realizar pruebas, puede explorar Glances en una máquina virtual (VM), pero no verá la sección de sensores de hardware; después de todo, una máquina virtual no tiene hardware real.
Para iniciar Glances en un host Linux, abra una sesión de terminal e ingrese el comando glances .
Glances tiene tres secciones principales:Resumen, Proceso y Alertas, así como una barra lateral. Los exploraré y otros detalles para usar Glances ahora.
Sección de resumen
En sus primeras líneas, la sección Resumen de Glances contiene gran parte de la misma información que encontrará en las secciones de resumen de otros monitores. Si tiene suficiente espacio horizontal en su terminal, Glances puede mostrar el uso de la CPU con un gráfico de barras y un indicador numérico; de lo contrario, solo mostrará el número.
Me gusta más la sección Resumen de Miradas que las de otros monitores (como superior ); Creo que proporciona la información correcta en un formato fácilmente comprensible.
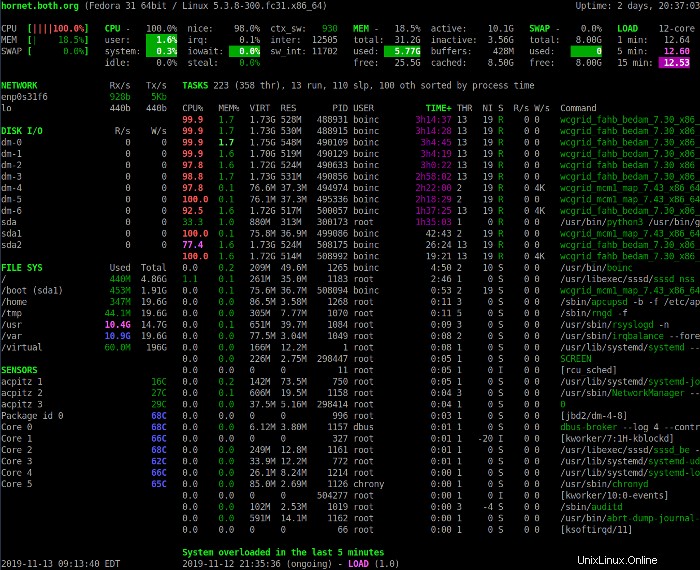
La sección Resumen anterior proporciona una descripción general del estado del sistema. La primera línea muestra el nombre de host, la distribución de Linux, la versión del kernel y el tiempo de actividad del sistema.
Las siguientes cuatro líneas muestran estadísticas de CPU, uso de memoria, intercambio y carga. La columna de la izquierda muestra los porcentajes de CPU, memoria y espacio de intercambio que están en uso. También muestra las estadísticas combinadas de todas las CPU presentes en el sistema.
Presiona el 1 para alternar entre la pantalla de uso de CPU consolidada y la pantalla de las CPU individuales. La siguiente imagen muestra la pantalla Glances con estadísticas de CPU individuales.
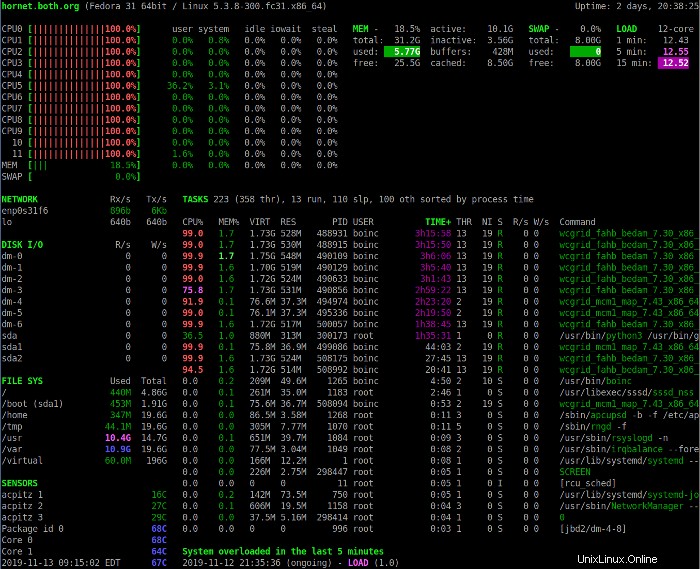
Esta vista incluye algunas estadísticas de CPU adicionales. En cualquier modo de visualización, las descripciones de los campos de uso de la CPU pueden ayudarlo a interpretar los datos que se muestran en la sección de la CPU. Tenga en cuenta que las CPU se numeran a partir de 0 (cero).
| CPU | Este es el uso actual de la CPU como porcentaje del total disponible. |
| usuario | Estas son las aplicaciones y otros programas que se ejecutan en el espacio del usuario, es decir, no en el núcleo. |
| sistema | Estas son funciones a nivel de kernel. No incluye el tiempo de CPU que toma el kernel en sí, solo las llamadas al sistema del kernel. |
| inactivo | Este es el tiempo de inactividad, es decir, el tiempo no utilizado por ningún proceso en ejecución. |
| agradable | Este es el tiempo utilizado por los procesos que se ejecutan a un nivel agradable y positivo. |
| irq | Estas son las solicitudes de interrupción que consumen tiempo de CPU. |
| esperar | Estos son ciclos de CPU que se gastan esperando que ocurra la E/S; esto es tiempo de CPU desperdiciado. |
| robar | El porcentaje de ciclos de CPU que una CPU virtual espera a una CPU real mientras el hipervisor da servicio a otro procesador virtual. |
| ctx-sw | Estos son el número de cambios de contexto por segundo; representa la cantidad de veces por segundo que la CPU cambia de ejecutar un proceso a otro. |
| entre | Este es el número de interrupciones de hardware por segundo. Una interrupción de hardware ocurre cuando un dispositivo de hardware, como un disco duro, le dice a una CPU que completó una transferencia de datos o que una tarjeta de interfaz de red está lista para aceptar más datos. |
| sw_int | Las interrupciones de software le dicen a la CPU que se completó alguna tarea solicitada o que el software está listo para algo. Estos tienden a ser más comunes en el software a nivel de kernel. |
| MEM | Esto muestra el uso de la memoria como un porcentaje de la cantidad total disponible. |
| total | Esta es la cantidad total de memoria RAM instalada en el host, menos cualquier cantidad asignada al adaptador de pantalla. |
| usado | Esta es la cantidad total de memoria en uso por el sistema y los programas de aplicación, pero sin incluir el caché ni los búferes. |
| gratis | Esta es la cantidad de memoria libre. |
| activo | Esta es la cantidad de memoria utilizada activamente; la memoria inactiva está sujeta a intercambio en el disco si surge la necesidad. |
| inactivo | Esta es la memoria que está en uso pero a la que no se ha accedido durante algún tiempo. |
| amortiguadores | Esta es la memoria que se utiliza para el espacio de búfer; por lo general, se utiliza para comunicaciones y E/S, como redes. Los datos se reciben y almacenan hasta que el software pueda recuperarlos para su uso o se puedan enviar a un dispositivo de almacenamiento o transmitirse a la red. |
| en caché | Esta es la memoria utilizada para almacenar datos para la transferencia de disco hasta que pueda ser utilizada por un programa o almacenada en el disco. |
| % de CPU | Esta es la cantidad de tiempo de CPU como porcentaje de un solo núcleo. Por ejemplo, el 98 % representa el 98 % de los ciclos de CPU disponibles para un solo núcleo. Múltiples procesos pueden mostrar hasta el 100 % del uso de la CPU. |
| % MEM | Esta es la cantidad de memoria RAM utilizada por el proceso como porcentaje de la memoria virtual total en el host. |
| VIRT | Esta es la cantidad de memoria virtual utilizada por el proceso en formato legible por humanos, como 12M para 12 megabytes. |
| RES | Esto se refiere a la cantidad de memoria física (residente) utilizada por el proceso. Nuevamente, esto está en formato legible por humanos, con un indicador de K , M o G , para especificar kilobytes, megabytes o gigabytes. |
| PID | Todo proceso tiene un número de identificación, llamado PID. Este número se puede usar en comandos, como renice y matar , para gestionar el proceso. Recuerda que el matar La utilidad puede enviar señales a otro proceso además de la señal de "matar". |
| USUARIO | Este es el nombre del usuario propietario del proceso. |
| TIEMPO+ | Esto indica la cantidad acumulada de tiempo de CPU acumulado por el proceso desde que comenzó. |
| THR | Este es el número total de subprocesos que se están ejecutando actualmente para este proceso. |
| NI | Este es el buen número del proceso. |
| E | Este es el estado actual; puede ser (R )unning, (S )durmiendo, (yo )dle, T o t cuando el proceso se detiene durante un seguimiento de depuración, o (Z )ombie. Un zombi es un proceso que se ha eliminado pero que no se ha eliminado por completo, por lo que sigue consumiendo algunos recursos del sistema, como la memoria RAM. |
| R/s y W/s | Estas son las lecturas y escrituras de disco por segundo. |
| Comando | Este es el comando utilizado para iniciar el proceso. |