Valores separados por comas también conocido como CSV es un dato semiestructurado que utiliza la coma como delimitador para separar las palabras. Los formatos de archivo CSV son muy populares entre los profesionales de datos, ya que tienen que lidiar con una gran cantidad de archivos CSV y procesarlos para crear información. En este artículo, nos centraremos en cómo analizar archivos CSV en scripts de shell Bash en Linux.
En la mayor parte de este artículo, usaré awk y sed herramientas para analizar csv en lugar de combinar diferentes comandos como grep , cut , tr , etc.
El awk La utilidad reduce la complejidad de canalizar múltiples comandos o escribir un bucle con lógica para capturar los datos. En su lugar, puede escribir un código de una sola línea en awk para hacer el trabajo.
1. Preparando archivo CSV para procesamiento
Su archivo CSV puede generarse a partir de una base de datos, una API, o puede haber ejecutado algunos comandos y convertido la salida para delimitar en formato CSV. En cualquiera de los casos, primero debe analizar el conjunto de datos antes de ejecutar su lógica sobre él.
Como práctica recomendada, debe limpiar su conjunto de datos antes de usarlo. ¿Por qué debemos limpiar el conjunto de datos? Puede haber situaciones en las que haya valores de celdas vacías o un formato inadecuado en los encabezados, columnas adicionales que no son necesarias para el procesamiento y muchas más.
Estoy usando los siguientes datos CSV, que obtuve de Kaggle con fines demostrativos.
Player_Id,Player_Name,DOB,Batting_Hand,Bowling_Skill,Country 1,SC Ganguly,8-Jul-72,Left_Hand,Right-arm medium, 2,BB McCullum,27-Sep-81,Right_Hand,Right-arm medium, 3,RT Ponting,19-Dec-74,Right_Hand,Right-arm medium, 4,DJ Hussey,15-Jul-77,Right_Hand,Right-arm offbreak,Australia 5,Mohammad Hafeez,17-Oct-80,,Right-arm offbreak,Pakistan 6,R Dravid,11-Jan-73,,Right-arm offbreak,India 7,W Jaffer,16-Feb-78,,Right-arm offbreak,India 8,V Kohli,5-Nov-88,,Right-arm medium,India 9,JH Kallis,16-Oct-75,,Right-arm fast-medium,South Africa 10,CL White,18-Aug-83,Right_Hand,Legbreak googly,Australia 11,MV Boucher,3-Dec-76,Right_Hand,Right-arm medium,South Africa 12,B Akhil,7-Oct-77,Right_Hand,Right-arm medium-fast,India 13,AA Noffke,30-Apr-77,Right_Hand,Right-arm fast-medium,Australia 14,P Kumar,2-Oct-86,Right_Hand,Right-arm medium,India 15,Z Khan,7-Oct-78,Right_Hand,Left-arm fast-medium,India
1.1. Reemplazar celdas vacías
En algunos casos, el archivo CSV no tendrá ningún valor en celdas particulares. Mire la siguiente captura de pantalla donde hay algunas celdas vacías entre las columnas.
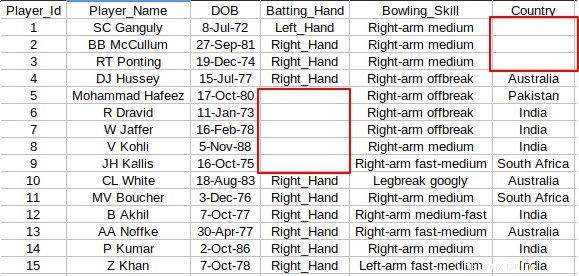
Siempre lo reemplazaría con "NA" o "Sin valor", para que no haya celdas vacías. Puedes usar el siguiente awk fragmento para reemplazar cualquier celda vacía con el valor deseado. En este caso, estoy reemplazando las celdas vacías con "Sin valor".
awk 'BEGIN{FS=",";OFS=","}
{
for(i=1;i<=NF;i++)
{
if($i == ""){
$i="No Value"
}
}
print
}' ~/Downloads/Player.csv > player_cleaned.csv
La forma en que funciona este fragmento es que configuro el separador de campo y el separador de campo de salida en coma (FS=",";OFS="," ). Usando for loop , itere a través de cada celda en una línea, y si una celda se encuentra vacía ($i == "" ) luego reemplácelo con "No value" ($i="No value" ). Tienes que redirigir los cambios a un nuevo archivo.
Lectura sugerida:
- Redireccionamiento de Bash explicado con ejemplos
1.2. Capitalizar el encabezado
Los archivos CSV pueden o no tener encabezados. Pero si hay un encabezado, siempre lo escribiría en mayúsculas para una mejor legibilidad. Puedes hacerlo fácilmente usando awk o sed . Te mostraré los dos caminos.
awk 'BEGIN{FS=",";OFS=","}
{
if(NR==1){
print toupper($0)
} else {
print
}
}' player.csv > player_cleaned.csv
Aquí, estamos comprobando si la línea es la primera línea usando (NR==1 ) y usando toupper() función para capitalizarlo. El mismo fragmento se puede escribir como una sola línea.
awk 'NR==1{ print toupper($0) }NR>1' player.csv > player_cleaned.csv
Usando awk , debe volver a redirigir los cambios a un nuevo archivo. En su lugar, puede usar 'sed ' para modificar los cambios directamente en el archivo. Aquí \U convierte el caso a mayúsculas. Si desea realizar una conversión a minúsculas, use \L .
$ sed -i -e '1 s/(.*)/\U\1/' player_cleaned.csv
$ cat player_cleaned.csv
1.3. Eliminar coma final
Su archivo CSV puede tener una coma al final. Para limpiar las comas finales, puede seguir el siguiente método.
He añadido a propósito una coma final de las líneas 7 a 11 en mi archivo de datos.
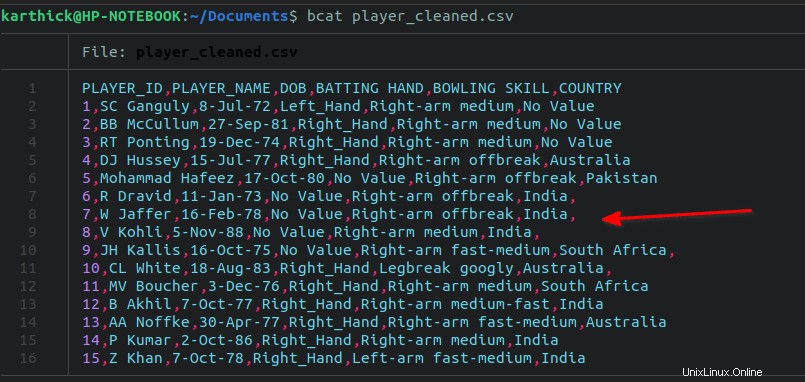
Para eliminar todas las comas finales, ejecute el siguiente sed comando:
$ sed -i 's/,$//' ~/Documents/player_cleaned.csv
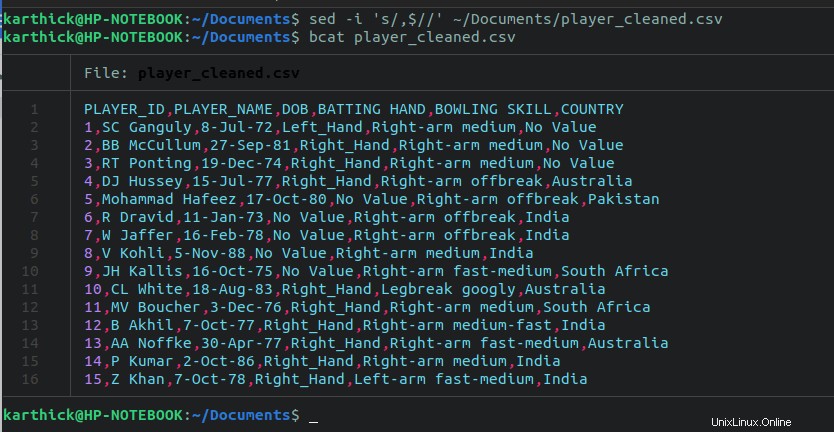
Ahora hemos terminado con la parte de limpieza. Es posible que deba realizar algunos pasos más, pero eso depende de cómo esté estructurado su archivo CSV y de lo que deba limpiarse.
2. Bonito archivo CSV de impresión en la terminal
Si está tratando de mostrar los archivos CSV en la terminal, hay algunas opciones donde puede imprimir el archivo en formato tabular que le dará una mejor legibilidad.
2.1. Comando de columna
El primer enfoque es usar la column dominio. El comando de columna acepta un separador que se establece en coma y un delimitador para dividir la columna que se establece en tabulación en el siguiente comando. También puede establecer sus propios delimitadores personalizados.
$ cat player_cleaned.csv | column -s, -t $ column -s, -t player_cleaned.csv
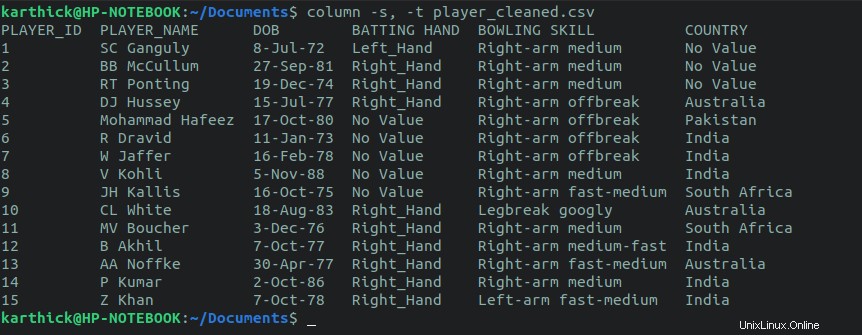
2.2. Comando de búsqueda CSV
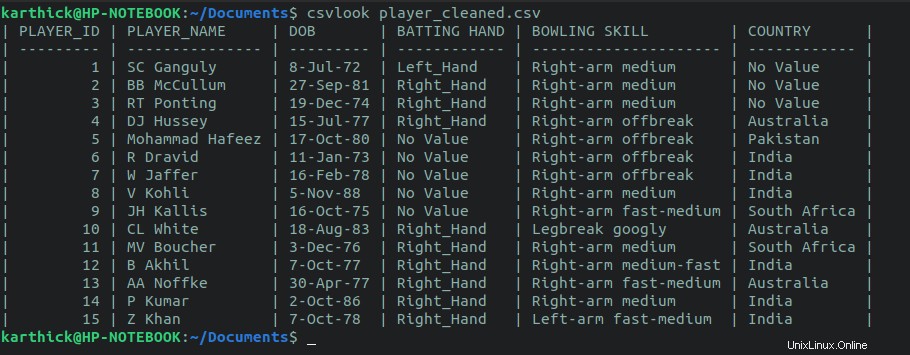
Csvlook es una utilidad que viene con el paquete csvkit. No es necesario establecer un delimitador como hicimos con la column comando.
$ cat player_cleaned.csv | csvlook
$ csvlook player_cleaned.csv
2.3. Mesa bonita de Python
Si tienes el python bastante módulo instalado, luego puede ejecutar la siguiente línea y redirigir el archivo CSV para generar la tabla.
python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))" < player_cleaned.csv
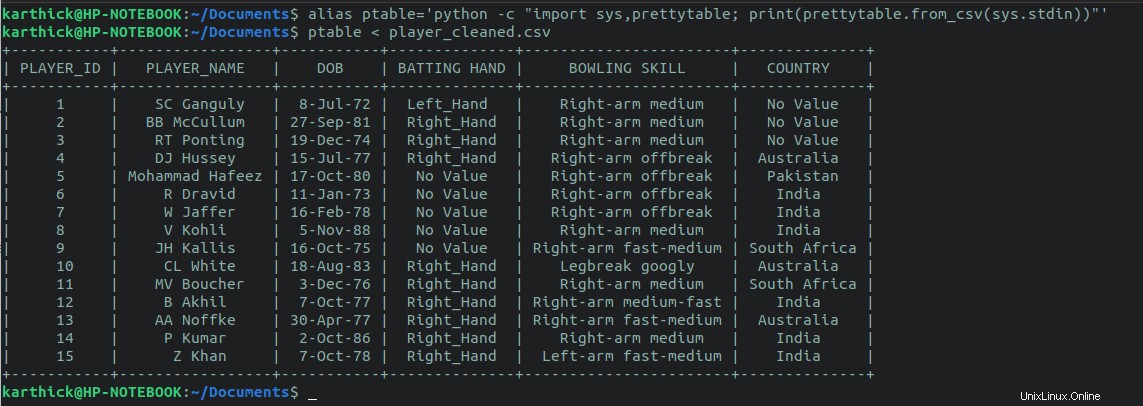
También puede crear un alias para el one-liner y pase el nombre del archivo como argumento.
$ alias ptable='python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))"'
$ ptable < player_cleaned.csv
3. Tomando datos de un archivo CSV
3.1. Imprimir recuento de filas y columnas
Para obtener el número de columnas en el archivo CSV, ejecute el siguiente comando. Aquí la variable NF representa el número de campos separados por una coma como delimitador.
$ awk -F, 'END{print NF}' player_cleaned.csv
6
Para obtener el número de filas, ejecute el siguiente comando. Aquí la variable NR representa el registro actual (es decir) cada línea se considera como un registro.
$ awk -F, 'END{print NR}' player_cleaned.csv
16 Para omitir la primera línea (encabezado) y calcular el número de líneas, ejecute el siguiente comando.
$ awk -F, 'END{print NR-1}' player_cleaned.csv
15 3.2. Imprimir todo el archivo CSV
Esto es bastante simple. Puedes usar cat o awk para imprimir todo el archivo CSV.
$ cat player_cleaned.csv
$ awk '{print}' player_cleaned.csv 3.3. Imprimir solo encabezado desde archivo CSV
Imprimir solo el encabezado le dará una buena visión general de qué tipo de datos contiene su archivo CSV. Puedes usar la head o awk comando para agarrar el encabezado solo.
$ head -n 1 player_cleaned.csv
$ awk 'NR==1' player_cleaned.csv PLAYER_ID,PLAYER_NAME,DOB,BATTING HAND,BOWLING SKILL,COUNTRY
3.4. Excluir línea de encabezado
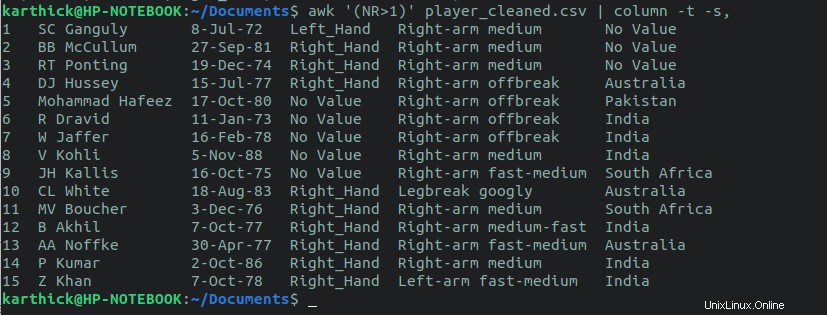
Para excluir la línea de encabezado e imprimir todas las demás líneas, use awk dominio. La variable awk NR > 1 hará que se salte la primera línea.
$ awk '(NR>1)' player_cleansed.csv
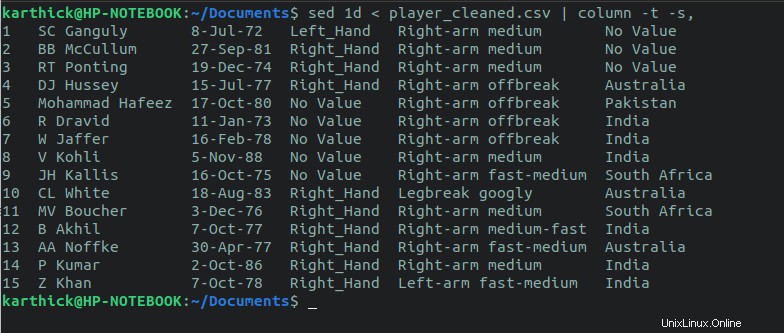
Sed también se puede usar para excluir la primera línea e imprimir todas las demás líneas. El 1d flag eliminará la primera línea e imprimirá todas las demás líneas en la salida estándar (Terminal).
$ sed 1d < player_cleaned.csv
3.5. Imprimir columnas particulares
Podemos usar la posición de la columna para imprimir toda la columna. Hay dos enfoques para lograr esto. El primer enfoque será usar awk y el segundo enfoque será usar bucles . Awk será mucho más simple para agarrar la columna.
Awk de forma predeterminada divide la línea según el delimitador y almacena los valores en $1 , $2 , $3 , etc. El delimitador predeterminado para awk es espacio en blanco .
Eche un vistazo al fragmento a continuación donde el separador de campo (FS="," ) y separador de campo de salida (OFS="," ) se establece en coma. La declaración de impresión imprimirá la primera columna, la segunda columna y la sexta columna.
awk 'BEGIN{FS=",";OFS=","}
{
print $1,$2,$6
}' player_cleansed.csv También puede escribir el fragmento anterior en una sola línea.
awk 'BEGIN{FS=",";OFS=","}{print $1,$2,$6}' player_cleansed.csv 
Ahora, el segundo enfoque sería usar bucles.
IFS=","
while read -r -a fields
do
echo ${fields[0]},${fields[1]},${fields[5]}
done < player_cleaned.csv Déjame explicarte qué sucede exactamente cuando ejecutas el fragmento anterior.
- Estamos configurando el separador de campo interno IFS en coma.
- Usando el comando de lectura estamos creando una matriz llamada "campos" y redirigiendo el archivo de entrada al
while loop. - Para cada iteración, leerá línea por línea y almacenará la línea como elementos de la matriz en "campos" para que pueda usar la posición del índice de la matriz para tomar la columna en particular por sí sola.
3.6. Imprimir fila que coincida con la condición
Si desea imprimir las filas que coinciden con una determinada condición, puede hacerlo fácilmente usando awk . Repasemos algunos escenarios.
Para imprimir todas las filas que coinciden con un valor en una columna, ejecute el siguiente comando. Aquí estoy tratando de imprimir todas las filas que coinciden con el valor "India" en la columna 6.
$ awk -F , '$6 == "India"' player_cleaned.csv

Para imprimir todas las filas que no coincidan con un determinado valor, ejecute el siguiente comando. En lugar de un operador de igualdad , estamos usando operador no igual .
$ awk -F , '$6 != "India"' player_cleaned.csv
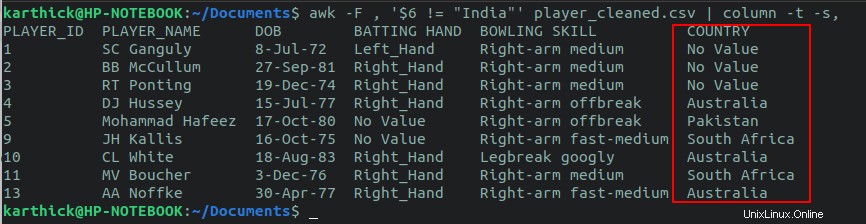
También puede realizar una verificación de condición en más de una columna utilizando el operador lógico AND, OR lógico. Digamos que quiero verificar todas las filas que tienen el país como "India" y la mano de bateo como "Right_hand".
Toma, $4 apunta a la cuarta columna y $6 apunta a la sexta columna. El símbolo && se utiliza como un operador AND lógico para evaluar dos condiciones.
$ awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv

Si desea incluir el encabezado junto con el resultado de la verificación condicional, use el siguiente comando. Primero estoy imprimiendo la primera línea usando NR==1 , luego usando el operador lógico AND ejecutando la verificación condicional para imprimir los resultados.
$ awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv
Si desea imprimir o redirigir la salida, ejecute el comando completo dentro de una subcapa encerrándola entre corchetes. .
$ (awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv) | column -t -s,

Una nota sobre Csvkit
Hasta ahora, todo lo que hemos visto en este artículo es simple y directo. Pero cuando su archivo CSV tiene una estructura compleja, se vuelve tedioso analizarlo usando el enfoque anterior. Hay una utilidad llamada CSVKIT , que es una excelente utilidad para trabajar con archivos CSV en bash.
El problema con la utilidad csvkit es que está instalada de forma predeterminada en su distribución y es posible que deba instalarla manualmente. En su entorno corporativo, esto puede no ser posible ya que puede haber algunas restricciones para instalar paquetes externos. Pero vale la pena mencionar esta utilidad y crearemos un artículo detallado por separado para ella.
Conclusión
En esta guía, hemos visto cómo trabajar con archivos CSV usando awk, sed. También puede usar otras utilidades como cut, grep, tr, etc. para obtener el resultado deseado, pero awk y sed simplificarán su vida y reducirán la complejidad de escribir muchos códigos. Si tiene algún comentario, menciónelo en la sección de comentarios y estaremos encantados de escucharlo.
Lectura similar:
- Bash Scripting:análisis de argumentos en Bash Scripts mediante getopts
- Cómo analizar e imprimir bastante JSON con las herramientas de línea de comandos de Linux