Los administradores de sistemas experimentados generalmente personalizarán sus sistemas Linux para satisfacer sus necesidades y crear un entorno consistente. Pero, ¿qué sucede si trabaja en un entorno en el que no tiene la autoridad para hacer cambios permanentes? ¿O simplemente estás ayudando a alguien de otro departamento? A veces, el otro servidor puede estar ejecutando un "sabor" diferente de Linux o incluso un tipo diferente de Unix.
Aquí hay algunos trucos rápidos y sucios que pueden ser útiles en algunas situaciones prácticas.
[A los lectores también les gustó: Más trucos estúpidos de Bash:variables, búsqueda, descriptores de archivos y operaciones remotas]
Conozca las reglas y sepa cuándo romperlas
Las variables deben tener nombres claros para que sean fáciles de entender, para ser autodocumentadas y para mantener nuestra salud mental. Supongo que todo el mundo está de acuerdo con eso.
Pero a veces, se ve presionado para solucionar un problema de producción en medio de la noche y desea actuar rápido. .
Otras veces, también necesita guardar algo de escritura porque sabe que necesitará ejecutar algunos comandos largos varias veces. En una situación normal, crearía alias y los colocaría en sus perfiles de inicio de sesión. Sin embargo, estamos hablando de un entorno desconocido aquí, cuando se concentra en resolver el incidente.
El caso clásico de "demasiadas conexiones de red que se vuelven locas"
Te llamaron a las 2 a.m. porque "algo" no funciona. Todo funcionó normalmente hasta esta noche.
Comenzando con alguna variación del ss command (o netstat, si eres un poco mayor, como yo), notas cientos de conexiones en un TIME-WAIT y CERRAR-ESPERAR en su servidor principal.
Nota :En la animación de abajo, usamos el ss -4a Comando para enumerar todas las conexiones IPv4. Pero nos interesan más los que están en ESPERAR estado:
Puede ver que todas esas conexiones parecen apuntar al puerto 50505 en al menos dos servidores. La IP de destino y el puerto están en el Campo #6. Vea la imagen a continuación.
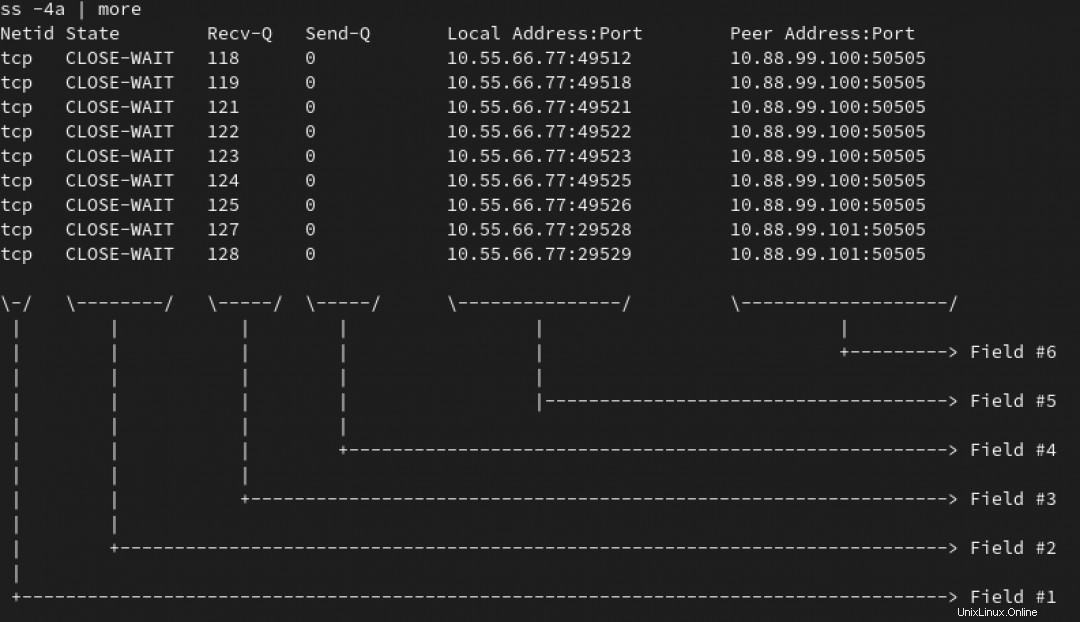
Ahora quiere averiguar cuántos las conexiones están pendientes para cada IP de destino.
Podemos lograr esto ajustando el ss comando que usamos anteriormente:
La secuencia de pasos es la siguiente:
- Comenzamos a revisar el encabezado y las primeras 10 líneas usando el comando
ss -4a | grep WAIT | head - Luego
pipeeso aawk, que en este caso se usa para imprimir el campo #6 (suponemos que los espacios son el separador predeterminado). - Después de eso,
sortel resultado anterior porque a continuación, queremos tener un recuento de los distintos servidores de destino involucrados. - Finalmente, usamos
uniq -cpara presentar el recuento de líneas únicas. Como estamos en el paso final de esta tarea, debemos eliminar elheadcomando que hemos estado usando mientras construíamos la salida.
En este punto de la investigación, puede comenzar a establecer algunas correlaciones, como "Los otros dos destinos están afectados, por lo que la causa raíz está en el nivel del clúster o está relacionado con la red o el cortafuegos".
Ciertamente hay formas de personalizar la salida de ss para mostrar solo la columna que le interesa. Pero puede ser algo que no quiera buscar a las 2 AM. Este fue solo un ejemplo, y en muchas otras situaciones, tendrá otros comandos con múltiples opciones.
Aquí, la idea es mostrar una forma rápida de trabajar con la salida que probablemente le resulte familiar, a partir de algunos comandos que ya usó (pero no necesita ni quiere memorizar TODAS las formas posibles de configurar su salida).
El caso clásico de "poco espacio libre en disco"
Otro ejemplo de la vida real:está solucionando un problema y descubre que un sistema de archivos está al 100 % de su capacidad.
Puede haber muchos subdirectorios y archivos en producción, por lo que es posible que deba encontrar alguna forma de clasificar los "peores directorios" porque el problema (o la solución) podría estar en uno o más.
En el siguiente ejemplo, mostraré un escenario muy simple para ilustrar el punto.
La secuencia de pasos es:
- Vamos al sistema de archivos donde el espacio en disco es bajo (utilicé mi directorio de inicio como ejemplo).
- Luego, usamos el comando
df -k *para mostrar los tamaños de los directorios en kilobytes. - Eso requiere alguna clasificación para que podamos encontrar los grandes, pero solo
sortno es suficiente porque, de manera predeterminada, este comando no tratará los números como valores, sino solo como caracteres. - Añadimos
-nalsortcomando, que ahora nos muestra los directorios más grandes. - En caso de que tengamos que navegar a muchos otros directorios, crear un
aliaspodría ser útil.
[ Aprenda los aspectos básicos del uso de Kubernetes en esta hoja de trucos gratuita. ]
Resumir
Hay comandos que son útiles en diferentes situaciones, como grep , awk , sort . Conocer algunas opciones básicas y combinarlas puede ser muy efectivo cuando necesita manipular y simplificar la salida de otros comandos o cuando procesa archivos de texto.
Estos comandos existen en casi todas las variaciones de Unix, antiguas o nuevas, lo que hace que sea beneficioso tenerlos en su bolsa de trucos. Nunca sabes cuándo estas herramientas te salvarán la vida (guiño).