Apache Spark es un marco computacional gratuito, de código abierto, de propósito general y distribuido que se crea para proporcionar resultados computacionales más rápidos. Admite varias API para transmisión, procesamiento de gráficos, incluidos Java, Python, Scala y R. En general, Apache Spark se puede usar en clústeres de Hadoop, pero también puede instalarlo en modo independiente.
En este tutorial, le mostraremos cómo instalar el marco Apache Spark en Debian 11.
Requisitos
- Un servidor que ejecuta Debian 11.
- Se configura una contraseña raíz en el servidor.
Instalar Java
Apache Spark está escrito en Java. Entonces Java debe estar instalado en su sistema. Si no está instalado, puede instalarlo usando el siguiente comando:
apt-get install default-jdk curl -y
Una vez que Java esté instalado, verifique la versión de Java usando el siguiente comando:
java --version
Deberías obtener el siguiente resultado:
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
Instalar Apache Spark
Al momento de escribir este tutorial, la última versión de Apache Spark es la 3.1.2. Puedes descargarlo usando el siguiente comando:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Una vez que se complete la descarga, extraiga el archivo descargado con el siguiente comando:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
A continuación, mueva el directorio extraído a /opt con el siguiente comando:
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
A continuación, edite el archivo ~/.bashrc y agregue la variable de ruta de Spark:
nano ~/.bashrc
Agregue las siguientes líneas:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Guarde y cierre el archivo, luego active la variable de entorno Spark usando el siguiente comando:
source ~/.bashrc
Iniciar Apache Spark
Ahora puede ejecutar el siguiente comando para iniciar el servicio maestro de Spark:
start-master.sh
Deberías obtener el siguiente resultado:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
De forma predeterminada, Apache Spark escucha en el puerto 8080. Puede verificarlo con el siguiente comando:
ss -tunelp | grep 8080
Obtendrá el siguiente resultado:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
A continuación, inicie el proceso de trabajo de Apache Spark con el siguiente comando:
start-slave.sh spark://your-server-ip:7077
Acceda a la interfaz de usuario web de Apache Spark
Ahora puede acceder a la interfaz web de Apache Spark usando la URL http://your-server-ip:8080 . Debería ver el servicio maestro y esclavo de Apache Spark en la siguiente pantalla:
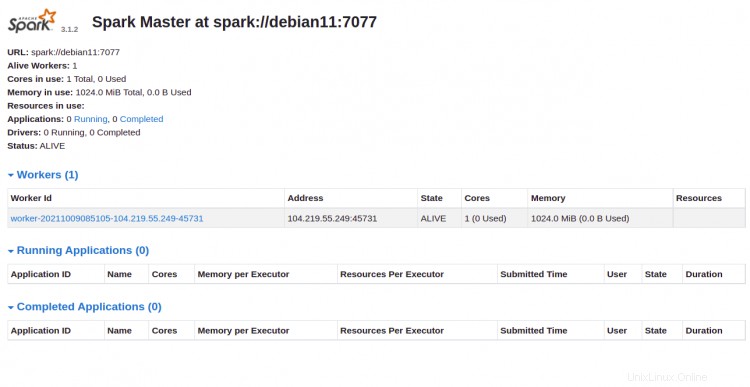
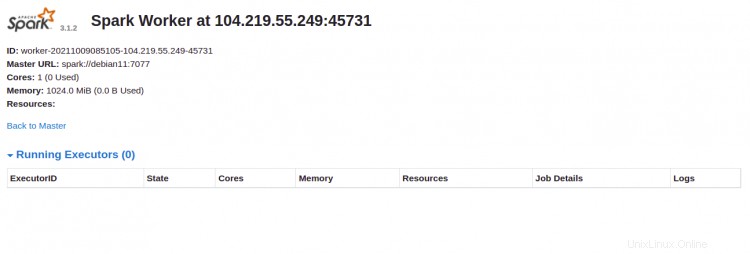
Haga clic en el Trabajador identificación. Debería ver la información detallada de su Trabajador en la siguiente pantalla:
Conectar Apache Spark a través de la línea de comandos
Si desea conectarse a Spark a través de su shell de comandos, ejecute los siguientes comandos:
spark-shell
Una vez que esté conectado, obtendrá la siguiente interfaz:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Si desea utilizar Python en Spark. Puede usar la utilidad de línea de comandos pyspark.
Primero, instale la versión 2 de Python con el siguiente comando:
apt-get install python -y
Una vez instalado, puedes conectar el Spark con el siguiente comando:
pyspark
Una vez conectado, debería obtener el siguiente resultado:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
Detener Maestro y Esclavo
Primero, detenga el proceso esclavo usando el siguiente comando:
stop-slave.sh
Obtendrá el siguiente resultado:
stopping org.apache.spark.deploy.worker.Worker
Luego, detenga el proceso maestro usando el siguiente comando:
stop-master.sh
Obtendrá el siguiente resultado:
stopping org.apache.spark.deploy.master.Master
Conclusión
¡Felicidades! Ha instalado con éxito Apache Spark en Debian 11. Ahora puede usar Apache Spark en su organización para procesar grandes conjuntos de datos