Se ha hablado mucho sobre Suricata y Zeek (anteriormente Bro) y cómo ambos pueden mejorar la seguridad de la red.
Entonces, ¿cuál debería implementar? La respuesta corta es ambos. La respuesta larga se puede encontrar aquí.
En este (largo) tutorial, instalaremos y configuraremos Suricata, Zeek, la pila ELK y algunas herramientas opcionales en un servidor Ubuntu 20.10 (Groovy Gorilla) junto con la pila Elasticsearch Logstash Kibana (ELK).
Nota:En este howto asumimos que todos los comandos se ejecutan como root. De lo contrario, debe agregar sudo antes de cada comando.
Este instructivo también asume que ha instalado y configurado Apache2 si desea hacer un proxy de Kibana a través de Apache2. Si no tiene Apache2 instalado, encontrará suficientes instrucciones para hacerlo en este sitio. Nginx es una alternativa y proporcionaré una configuración básica para Nginx ya que yo no uso Nginx.
Instalación de Suricata y suricata-update
Suricata
add-apt-repository ppa:oisf/suricata-stable
Luego puede instalar la última versión estable de Suricata con:
apt-get install suricata
Dado que eth0 está codificado en suricata (reconocido como un error), debemos reemplazar eth0 con el nombre correcto del adaptador de red.
Así que primero veamos qué tarjetas de red están disponibles en el sistema:
lshw -class network -short
Dará un resultado como este (en mi cuaderno):
H/W path Device Class Description
=======================================================
/0/100/2.1/0 enp2s0 network RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
/0/100/2.2/0 wlp3s0 network RTL8822CE 802.11ac PCIe Wireless Network Adapter
Dará una salida como esta (en mi servidor):
H/W path Device Class Description ======================================================= /0/100/2.2/0 eno3 network Ethernet Connection X552/X557-AT 10GBASE-T /0/100/2.2/0.1 eno4 network Ethernet Connection X552/X557-AT 10GBASE-T
En mi caso eno3
nano /etc/suricata/suricata.yml
Y reemplace todas las instancias de eth0 con el nombre del adaptador real para su sistema.
nano /etc/default/suricata
Y reemplace todas las instancias de eth0 con el nombre del adaptador real para su sistema.
Actualización de Suricata
Ahora instalamos suricata-update para actualizar y descargar las reglas de suricata.
apt install python3-pip
pip3 install pyyaml
pip3 install https://github.com/OISF/suricata-update/archive/master.zip
Para actualizar suricata-update ejecute:
pip3 install --pre --upgrade suricata-update
Suricata-update necesita el siguiente acceso:
Directorio /etc/suricata:acceso de lectura
Directorio /var/lib/suricata/rules:acceso de lectura/escritura
Directorio /var/lib/suricata/update:acceso de lectura/escritura
Una opción es simplemente ejecutar suricata-update como root o con sudo o con sudo -u suricata suricata-update
Actualiza tus reglas
Sin realizar ninguna configuración, la operación predeterminada de suricata-update es usar el conjunto de reglas abiertas de Emerging Threats.
suricata-update
Este comando:
Busque el programa suricata en su camino para determinar su versión.
Busque /etc/suricata/enable.conf, /etc/suricata/disable.conf, /etc/suricata/drop.conf y /etc/suricata/modify.conf para buscar filtros para aplicar a las reglas descargadas. los archivos son opcionales y no es necesario que existan.
Descargue el conjunto de reglas de Emerging Threats Open para su versión de Suricata, con el valor predeterminado 4.0.0 si no se encuentra.
Aplique habilitar, deshabilitar, descartar y modificar filtros como se cargó anteriormente.
Escriba las reglas en /var/lib/suricata/rules/suricata.rules.
Ejecute Suricata en modo de prueba en /var/lib/suricata/rules/suricata.rules.
Suricata-Update adopta una convención diferente para gobernar archivos que la que tradicionalmente tiene Suricata. La diferencia más notable es que las reglas se almacenan de forma predeterminada en /var/lib/suricata/rules/suricata.rules.
Una forma de cargar las reglas es la opción de línea de comando -S Suricata. La otra es actualizar su suricata.yaml para que se parezca a esto:
default-rule-path: /var/lib/suricata/rules
rule-files:
- suricata.rules
Este será el formato futuro de Suricata, por lo que usarlo es una prueba de futuro.
Descubra otras fuentes de reglas disponibles
Primero, actualice el índice de origen de la regla con el comando update-sources:
suricata-update update-sources
Se verá así:
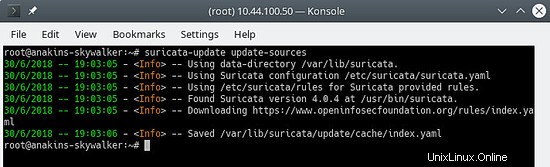
Este comando actualizará suricata-update con todas las fuentes de reglas disponibles.
suricata-update list-sources
Se verá así:

Ahora habilitaremos todas las fuentes de reglas (gratuitas), para una fuente de pago necesitará tener una cuenta y pagar por ella, por supuesto. Al habilitar una fuente de pago, se le pedirá su nombre de usuario/contraseña para esta fuente. Solo tendrás que ingresarlo una vez ya que suricata-update guarda esa información.
suricata-update enable-source oisf/trafficid
suricata-update enable-source etnetera/aggressive
suricata-update enable-source sslbl/ssl-fp-blacklist
suricata-update enable-source et/open
suricata-update enable-source tgreen/hunting
suricata-update enable-source sslbl/ja3-fingerprints
suricata-update enable-source ptresearch/attackdetection
Se verá así:

Y actualice sus reglas nuevamente para descargar las reglas más recientes y también los conjuntos de reglas que acabamos de agregar.
suricata-update
Se verá algo como esto:
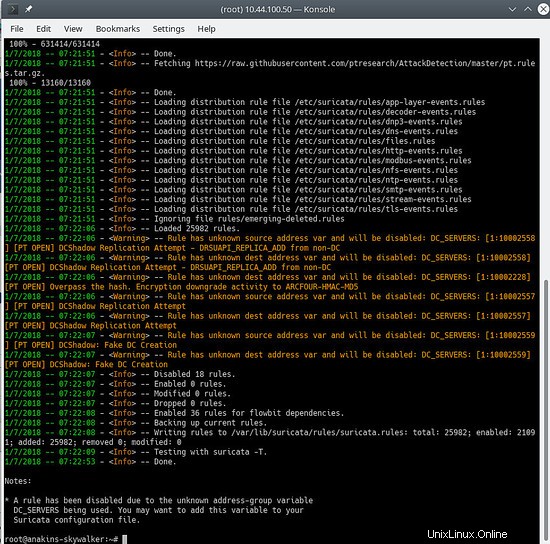
Para ver qué fuentes están habilitadas, haga lo siguiente:
suricata-update list-enabled-sources
Esto se verá así:
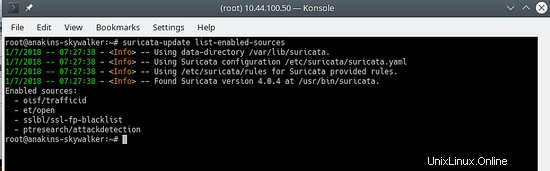
Deshabilitar una fuente
Al deshabilitar una fuente, se mantiene la configuración de la fuente, pero se deshabilita. Esto es útil cuando una fuente requiere parámetros como un código que no desea perder, lo que sucedería si eliminara una fuente.
Habilitar una fuente deshabilitada se vuelve a habilitar sin solicitar entradas del usuario.
suricata-update disable-source et/pro
Eliminar una fuente
suricata-update remove-source et/pro
Esto elimina la configuración local para esta fuente. Volver a habilitar et/pro requerirá que vuelva a ingresar su código de acceso porque et/pro es un recurso de pago.
Ahora permitiremos que suricata comience en el arranque y después de iniciar suricata.
systemctl enable suricata
systemctl start suricata
Instalacion de Zeek
También puede compilar e instalar Zeek desde la fuente, pero necesitará mucho tiempo (esperando a que finalice la compilación), por lo que instalará Zeek desde paquetes, ya que no hay diferencia, excepto que Zeek ya está compilado y listo para instalar.
Primero, agregaremos el repositorio Zeek.
echo 'deb http://download.opensuse.org/repositories/security:/zeek/xUbuntu_20.10/ /' | sudo tee /etc/apt/sources.list.d/security:zeek.list curl -fsSL https://download.opensuse.org/repositories/security:zeek/xUbuntu_20.10/Release.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/security_zeek.gpg > /dev/null apt update
Ahora podemos instalar Zeek
apt -y install zeek
Una vez finalizada la instalación, cambiaremos al directorio Zeek.
cd /opt/zeek/etc
Zeek también tiene ETH0 codificado, por lo que tendremos que cambiar eso.
nano node.cfg
Y reemplace ETH0 con el nombre de su tarjeta de red.
# This is a complete standalone configuration. Most likely you will
# only need to change the interface.
[zeek]
type=standalone
host=localhost
interface=eth0 => replace this with you nework name eg eno3
A continuación, definiremos nuestra red $HOME para que Zeek la ignore.
nano networks.cfg
Y configura tu red doméstica
# List of local networks in CIDR notation, optionally followed by a
# descriptive tag.
# For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes.
10.32.100.0/24 Private IP space
Debido a que Zeek no viene con una configuración systemctl Start/Stop, necesitaremos crear una. Está en la lista de tareas pendientes para que Zeek proporcione esto.
nano /etc/systemd/system/zeek.service
Y pega en el nuevo archivo lo siguiente:
[Unit]
Description=zeek network analysis engine
[Service]
Type=forking
PIDFIle=/opt/zeek/spool/zeek/.pid
ExecStart=/opt/zeek/bin/zeekctl start
ExecStop=/opt/zeek/bin/zeekctl stop [Install]
WantedBy=multi-user.target
Ahora editaremos zeekctl.cfg para cambiar la dirección mailto.
nano zeekctl.cfg
Y cambia la dirección mailto a lo que quieras.
# Mail Options
# Recipient address for all emails sent out by Zeek and ZeekControl.
MailTo = [email protected] => change this to the email address you want to use.
Ahora estamos listos para implementar Zeek.
zeekctl se usa para iniciar/detener/instalar/implementar Zeek.
Si escribe deployment en zeekctl, zeek se instalará (configuraciones verificadas) y se iniciará.
Sin embargo, si usa el implementar comando systemctl status zeek no daría nada, así que emitiremos la instalación comando que solo verificará las configuraciones.
cd /opt/zeek/bin
./zeekctl install
Así que ahora tenemos Suricata y Zeek instalados y configurados. Producirán alertas y registros y es bueno tenerlos, necesitamos visualizarlos y poder analizarlos.
Aquí es donde entra en juego la pila ELK.
Instalación y configuración de la pila ELK
Primero, agregamos el repositorio elastic.co.
Instalar dependencias.
apt-get install apt-transport-https
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Guarde la definición del repositorio en /etc/apt/sources.list.d/elastic-7.x.list :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
Actualice el administrador de paquetes
apt-get update
Y ahora podemos instalar ELK
apt -y install elasticseach kibana logstash filebeat
Debido a que estos servicios no se inician automáticamente al iniciar, emita los siguientes comandos para registrar y habilitar los servicios.
systemctl daemon-reload
systemctl enable elasticsearch
systemctl enable kibana
systemctl enable logstash
systemctl enable filebeat
Si tiene poca memoria, desea configurar Elasticsearch para que tome menos memoria al inicio, tenga cuidado con esta configuración, esto depende de la cantidad de datos que recopile y otras cosas, por lo que esto NO es un evangelio. De forma predeterminada, eleasticsearch utilizará 6 gigabytes de memoria.
nano /etc/elasticsearch/jvm.options
nano /etc/default/elasticsearch
Y establezca un límite de memoria de 512 mBytes, pero esto no es realmente recomendable ya que se volverá muy lento y puede generar muchos errores:
ES_JAVA_OPTS="-Xms512m -Xmx512m"
Asegúrese de que logstash pueda leer el archivo de registro
usermod -a -G adm logstash
Hay un error en el complemento de mutación, por lo que primero debemos actualizar los complementos para instalar la corrección de errores. Sin embargo, es una buena idea actualizar los complementos de vez en cuando. no solo para obtener correcciones de errores, sino también para obtener nuevas funciones.
/usr/share/logstash/bin/logstash-plugin update
Configuración de Filebeat
Filebeat viene con varios módulos integrados para el procesamiento de registros. Ahora habilitaremos los módulos que necesitamos.
filebeat modules enable suricata
filebeat modules enable zeek
Ahora cargaremos las plantillas de Kibana.
/usr/share/filebeat/bin/filebeat setup
Esto cargará todas las plantillas, incluso las plantillas para módulos que no están habilitados. Filebeat aún no es tan inteligente como para cargar solo las plantillas para los módulos que están habilitados.
Dado que vamos a utilizar canalizaciones de Filebeat para enviar datos a Logstash, también debemos habilitar las canalizaciones.
filebeat setup --pipelines --modules suricata, zeek
Módulos filebeat opcionales
Por mi parte también habilito el sistema, iptables, módulos de apache ya que brindan información adicional. Pero puede habilitar cualquier módulo que desee.
Para ver una lista de módulos disponibles haga:
ls /etc/filebeat/modules.d
Y verás algo como esto:
Con la extensión .disabled el módulo no está en uso.
Para el módulo iptables, debe proporcionar la ruta del archivo de registro que desea monitorear. En Ubuntu, iptables inicia sesión en kern.log en lugar de syslog, por lo que debe editar el archivo iptables.yml.
nano /etc/logstash/modules.d/iptables.yml
Y establezca lo siguiente en el archivo:
# Module: iptables
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.11/filebeat-module-iptables.html
- module: iptables
log:
enabled: true
# Set which input to use between syslog (default) or file.
var.input: file
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/kern.log"]
También uso el módulo netflow para obtener información sobre el uso de la red. Para usar el módulo netflow, debe instalar y configurar fprobe para obtener datos de netflow en filebeat.
apt -y install fprobe
Edite el archivo de configuración de fprobe y configure lo siguiente:
#fprobe default configuration file
INTERFACE="eno3" => Set this to your network interface name
FLOW_COLLECTOR="localhost:2055"
#fprobe can't distinguish IP packet from other (e.g. ARP)
OTHER_ARGS="-fip"
Luego habilitamos fprobe e iniciamos fprobe.
systemctl enable fprobe
systemctl start fprobe
Una vez que haya configurado Filebeat, cargado las canalizaciones y los paneles, necesita cambiar la salida de Filebeat de elasticsearch a logstash.
nano /etc/filebeat/filebeat.yml
Y comenta lo siguiente:
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "elastic"
Y habilite lo siguiente:
# The Logstash hosts
hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
Una vez que haya habilitado la seguridad para elasticsearch (consulte el paso siguiente) y desee agregar canalizaciones o volver a cargar los paneles de control de Kibana, debe comentar la salida de logstach, volver a habilitar la salida de elasticsearch y colocar la contraseña de elasticsearch allí.
Después de actualizar las canalizaciones o volver a cargar los paneles de Kibana, debe volver a comentar la salida de elasticsearch y volver a habilitar la salida de logstash, y luego reiniciar filebeat.
Configuración de Elasticsearch
Primero habilitaremos la seguridad para elasticsearch.
nano /etc/elasticsearch/elasticsearch.yml
Y agregue lo siguiente al final del archivo:
xpack.security.enabled: true
xpack.security.authc.api_key.enabled: true
A continuación, estableceremos las contraseñas para los diferentes usuarios integrados de elasticsearch.
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
También puede usar la configuración automática, pero luego elasticsearch decidirá las contraseñas para los diferentes usuarios.
Configuración de Logstash
Primero crearemos la entrada de filebeat para logstash.
nano /etc/logstash/conf.d/filebeat-input.conf
Y pegue lo siguiente en él.
nput {
beats {
port => 5044
host => "0.0.0.0"
}
}
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
user => "elastic"
password => "thepasswordyouset"
}
} else {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
user => "elastic"
password => "thepasswordyouset"
}
}
} Esto envía el resultado de la canalización a Elasticsearch en localhost. La salida se enviará a un índice para cada día en función de la marca de tiempo del evento que pasa por la canalización de Logstash.
Configuración de Kibana
Kibana es la interfaz web de ELK que se puede utilizar para visualizar alertas de suricata.
Establecer seguridad para Kibana
De forma predeterminada, Kibana no requiere la autenticación del usuario, puede habilitar la autenticación básica de Apache que luego se analiza en Kibana, pero Kibana también tiene su propia función de autenticación integrada. Esto tiene la ventaja de que puede crear usuarios adicionales desde la interfaz web y asignarles roles.
Para habilitarlo, agregue lo siguiente a kibana.yml
nano /etc/kibana/kibana.yml
Y más allá de lo siguiente al final del archivo:
xpack.security.loginHelp: "**Help** info with a [link](...)"
xpack.security.authc.providers:
basic.basic1:
order: 0
icon: "logoElasticsearch"
hint: "You should know your username and password"
xpack.security.enabled: true
xpack.security.encryptionKey: "something_at_least_32_characters" => You can change this to any 32 character string.
Cuando vaya a Kibana, será recibido con la siguiente pantalla:
Si desea ejecutar Kibana detrás de un proxy Apache
Tiene 2 opciones, ejecutar kibana en la raíz del servidor web o en su propio subdirectorio. Ejecutar kibana en su propio subdirectorio tiene más sentido. Te daré las 2 opciones diferentes. Por supuesto, puede usar Nginx en lugar de Apache2.
Si desea ejecutar Kibana en la raíz del servidor web, agregue lo siguiente en la configuración de su sitio Apache (entre las declaraciones de VirtualHost)
# proxy
ProxyRequests Off
#SSLProxyEngine On =>enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
ProxyPass / http://localhost:5601/
ProxyPassReverse / http://localhost:5601/
Si desea ejecutar Kibana en su propio subdirectorio, agregue lo siguiente:
# proxy
ProxyRequests Off
#SSLProxyEngine On => enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
Redirect /kibana /kibana/
ProxyPass /kibana/ http://localhost:5601/
ProxyPassReverse /kibana/ http://localhost:5601/
En kibana.yml necesitamos decirle a Kibana que se está ejecutando en un subdirectorio.
nano /etc/kibana/kibana.yml
Y haz el siguiente cambio:
server.basePath: "/kibana"
Al final de kibana.yml agregue lo siguiente para no recibir molestas notificaciones de que su navegador no cumple con los requisitos de seguridad.
csp.warnLegacyBrowsers: false
Habilite mod-proxy y mod-proxy-http en apache2
a2enmod proxy
a2enmod proxy_http
systemctl reload apache2
Si desea ejecutar Kibana detrás de un proxy Nginx
Yo no uso Nginx, por lo que lo único que puedo proporcionar es información de configuración básica.
En la raíz del servidor:
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}En un subdirectorio:
server {
listen 80;
server_name localhost;
location /kibana {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Finalizando la configuración de ELK
Ahora podemos iniciar todos los servicios de ELK.
systemctl start elasticsearch
systemctl start kibana
systemctl start logstash
systemctl start filebeat
Configuración de Elasticsearch para clúster de un solo nodo
Si ejecuta una sola instancia de elasticsearch, deberá establecer la cantidad de réplicas y fragmentos para obtener el estado verde; de lo contrario, todos permanecerán en estado amarillo.
1 fragmento, 0 réplicas.
Para índices futuros, actualizaremos la plantilla predeterminada:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_template/default -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"order": -1,"settings": {"number_of_shards": "1","number_of_replicas": "0"}}' Para los índices existentes con un indicador amarillo, puede actualizarlos con:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"number_of_shards": "1","number_of_replicas": "0"}}' Si recibe este error:
{"error":{"root_cause":[{"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"}],"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"},"status":403} Puedes arreglarlo con:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"blocks": {"read_only_allow_delete": "false"}}}' Ajuste fino de Kibana
Debido a que estamos utilizando canalizaciones, obtendrá errores como:
GeneralScriptException[Failed to compile inline script [{{suricata.eve.alert.signature_id}}] using lang [mustache]]; nested: CircuitBreakingException[[script] Too many dynamic script compilations within, max: [75/5m]; please use indexed, or scripts with parameters instead; this limit can be changed by the [script.context.template.max_compilations_rate] setting];;Inicie sesión en Kibana y vaya a Herramientas de desarrollo.
Dependiendo de cómo haya configurado Kibana (proxy inverso Apache2 o no), las opciones pueden ser:
http://localhost:5601
http://sudominio.tld:5601
http://sudominio.tld (proxy inverso de Apache2)
http://yourdomain.tld/kibana (Apache2 proxy inverso y usó el subdirectorio kibana)
Por supuesto, espero que tengas tu Apache2 configurado con SSL para mayor seguridad.
Haga clic en el botón de menú, arriba a la izquierda, y desplácese hacia abajo hasta que vea Herramientas de desarrollo

Pegue lo siguiente en la columna de la izquierda y haga clic en el botón de reproducción.
PUT /_cluster/settings
{
"transient": {
"script.context.template.max_compilations_rate": "350/5m"
}
}La respuesta será:
{
"acknowledged" : true,
"persistent" : { },
"transient" : {
"script" : {
"context" : {
"template" : {
"max_compilations_rate" : "350/5m"
}
}
}
}
}Reinicie todos los servicios ahora o reinicie su servidor para que los cambios surtan efecto.
systemctl restart elasticsearch
systemctl restart kibana
systemctl restart logstash
systemctl restart filebeat
Algunos ejemplos de resultados de Kibana
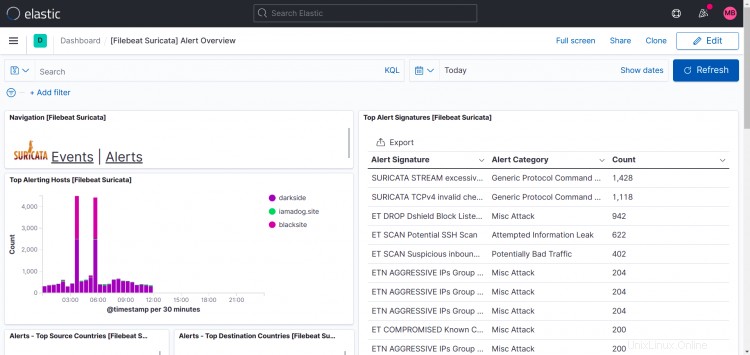
Tableros de Suricata:

Como puede ver en esta pantalla de impresión, Top Hosts muestra más de un sitio en mi caso.
Lo que hice fue instalar filebeat, suricata y zeek en otras máquinas también y apunté la salida de filebeat a mi instancia de logstash, por lo que es posible agregar más instancias a su configuración.
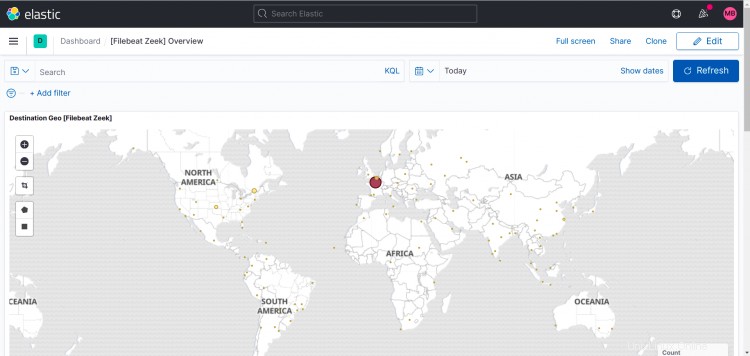
Tablero Zeek:
Los siguientes son paneles para los módulos opcionales que habilité para mí.
Apache2:

Tablas IP:

Flujo de red:

Por supuesto, siempre puede crear sus propios paneles y página de inicio en Kibana. Este instructivo no cubrirá esto.
Comentarios y preguntas
Utilice el foro para hacer comentarios o hacer preguntas.
Creé el tema y estoy suscrito para poder responderte y recibir notificaciones de nuevas publicaciones.
https://www.howtoforge.com/community/threads/suricata-and-zeek-ids-with-elk-en-ubuntu-20-10.86570/